
Despite their significant contributions to deep learning, LSTMs have limitations, notably in revising stored information. For instance, when faced with the Nearest Neighbor Search problem, where a sequence needs to find the most similar vector, LSTMs struggle to update stored values when encountering a closer match later in the sequence. This inability to revise storage decisions hampers their performance in tasks requiring dynamic adjustments to stored information. These challenges demand ongoing advancements in neural network architectures to address limitations and improve model capabilities.
Researchers from the ELLIS Unit, LIT AI Lab, Institute for Machine Learning, JKU Linz, Austria NXAI Lab, Linz, Austria, and NXAI GmbH, Linz, Austria, aim to enhance LSTM language modeling by addressing its limitations. They introduce exponential gating and modify memory structures to create xLSTM, which can revise stored values efficiently, accommodate more information, and enable parallel processing. Integrating these advancements into residual block architectures achieves competitive performance comparable to state-of-the-art Transformers and State Space Models. Overcoming LSTM’s constraints opens avenues for scaling language models to the magnitude of current Large Language Models, potentially revolutionizing language understanding and generation tasks.
Various approaches have emerged to address the quadratic complexity of attention mechanisms in Transformers, including Linear Attention techniques like Synthesizer, Linformer, Linear Transformer, and Performer. State Space Models (SSMs) have gained traction for their linearity in context length, with models like S4, DSS, and BiGS showing promising results. Recurrent Neural Networks (RNNs) with linear units and gating mechanisms have also garnered attention, as seen in models like HGRN and RWKV. Covariance update rules, memory mixing, and residual stacking architectures are pivotal components in enhancing model capabilities, with xLSTM architectures standing as contenders against Transformers in large language modeling tasks.
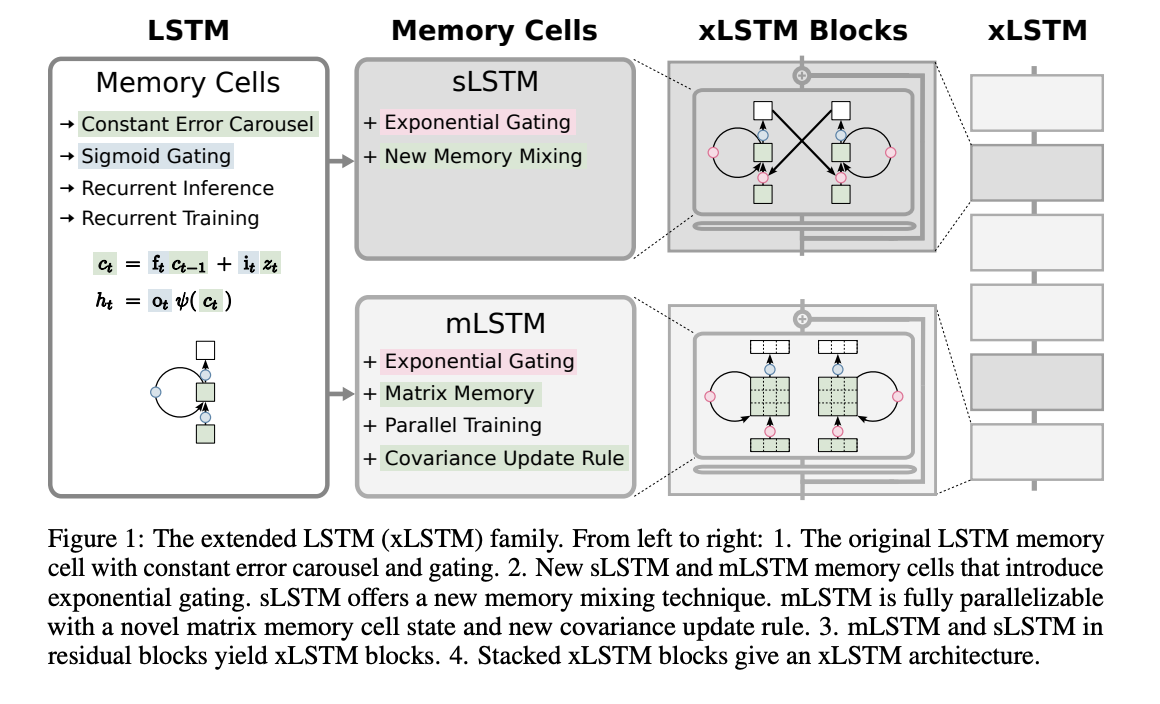
Extended Long Short-Term Memory (xLSTM) introduces exponential gating and memory structures to enhance LSTM models. It presents two variants: sLSTM with scalar memory and update, featuring memory mixing, and mLSTM with matrix memory and covariance update rule, which is fully parallelizable. Integration into residual block architectures yields xLSTM blocks, which can summarize past contexts nonlinearly in high-dimensional spaces. xLSTM architectures are constructed by stacking these blocks residually, offering linear computation and constant memory complexity concerning sequence length. While mLSTM is computationally expensive due to its matrix memory, optimizations enable efficient parallel processing on GPUs.
In the experimental evaluation of xLSTM for language modeling, synthetic tasks and performance on SlimPajama datasets are investigated. xLSTM’s capabilities are tested on formal languages, associative recall tasks, and long-range arena scenarios. Comparisons with existing methods reveal xLSTM’s superiority in validation perplexity. Ablation studies highlight the importance of exponential gating and matrix memory in xLSTM’s performance. Large-scale language modeling experiments on 300B tokens further validate xLSTM’s effectiveness, showing its robustness in handling long contexts, downstream tasks, and diverse text domains. Scaling behavior analysis suggests xLSTM’s favorable performance compared to other models as size increases.
In conclusion, xLSTM faces limitations, including slower parallelization than mLSTM, slower CUDA kernels, and computational complexity for matrix memory. Careful forget gate initialization is crucial, and longer contexts may strain memory. Despite these, xLSTM shows promise in language modeling, rivaling Transformers, and State Space Models. Scaling laws suggest its potential competitiveness with large language models. Further optimization is needed for larger xLSTM architectures. Overall, xLSTM’s innovations in gating and memory structures position it as a significant contender in language modeling and potentially other deep learning domains like Reinforcement Learning and Time Series Prediction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post xLSTM: Enhancing Long Short-Term Memory LSTM Capabilities for Advanced Language Modeling and Beyond appeared first on MarkTechPost.