Imagine machines that don’t just capture pixels but truly understand them, recognizing objects, reading text, interpreting scenes, and even “speaking” about images as fluently as a human. VLMs merge computer vision’s “sight” with language’s “speech,” letting AI both describe and converse about any picture it sees.
From generating captions and answering questions to counting objects, reading license plates, and creating new imagery from text, VLMs are already transforming accessibility, robotics, healthcare, and design, turning yesterday’s science fiction into today’s reality.
Below, we’ll explore the most transformative real-world use cases, each illustrated with concise code snippets using Google’s PaliGemma2 Mix, to show exactly how you can put vision and language to work in your own projects.
Meet PaliGemma 2 Mix
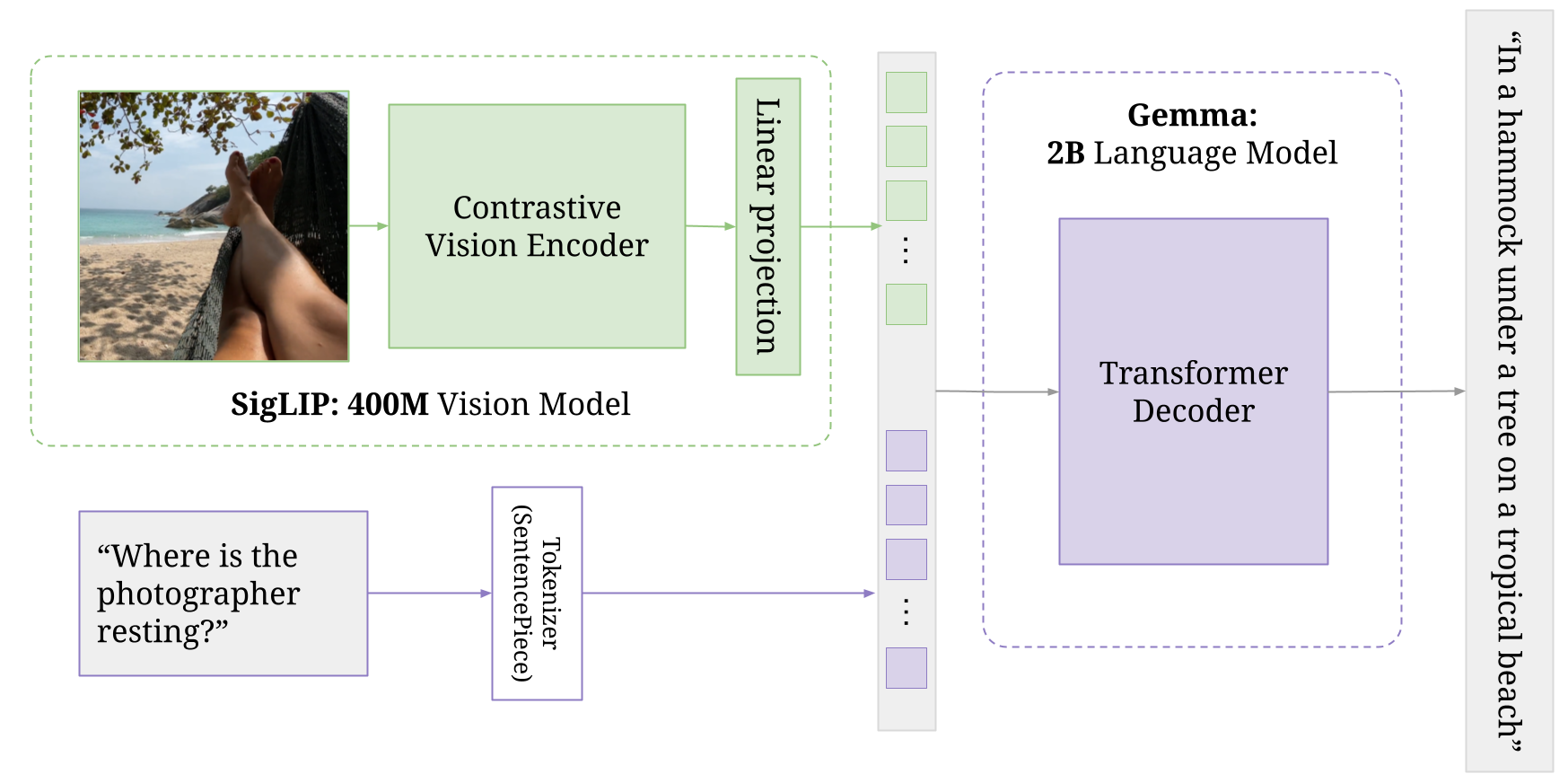
PaliGemma 2 is the next evolution of the original PaliGemma model, integrating the latest Gemma 2 language backbone with the SigLIP vision encoder. It’s designed for top-tier performance across a broad spectrum of vision-language tasks:
- Image & Video Captioning
- Visual Question Answering (VQA)
- Optical Character Recognition (OCR)
- Zero-Shot Object Detection & Segmentation
Architecture at a Glance
- Image Encoder: SigLIP-So400m/14 Vision Transformer
- Text Decoder: Gemma 2 Transformer (available in 2B, 9B, and 27B parameter sizes)
- Training Recipe: Follows PaLI-3’s proven multi-task regimen
https://storage.googleapis.com/gweb-developer-goog-blog-assets/images/image4_W4FHDmx.original.png
{kind=link}
Inputs & Outputs
- Input: An image plus a text prompt (e.g., “describe en,” “answer What’s in this picture?, “detect cat”, “segment dog”)
- Output: Generated text, captions, answers, bounding-box coordinates, segmentation masks, you name it.
Data & Responsible Filtering
Pre-training draws on a rich, multilingual mix of datasets:
- WebLI: Web-scale image-text pairs in dozens of languages
- CC3M-35L: 3 million curated English pairs translated into 34 languages
- VQ²A & VQG-CC3M: Question, answer and question-generation splits, also multilingual
- OpenImages & WIT: Object detection Q&A and Wikipedia image–text pairs
To ensure safety and privacy, PaliGemma 2 applies rigorous filters for pornography, toxic or offensive text, and sensitive personal information, using tools like Google’s DLP and Perspective APIs.
Using PaliGemma 2
Load the model and processor once:
from transformers import (
PaliGemmaProcessor,
PaliGemmaForConditionalGeneration,
)
from transformers.image_utils import load_image
import torch
model_id = "google/paligemma2-3b-mix-448"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg"
image = load_image(url)
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto").eval()
processor = PaliGemmaProcessor.from_pretrained(model_id)
prompt = "describe en"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(torch.bfloat16).to(model.device)
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)Prompt templates
You can use the following prompt templates to perform different tasks:
- “cap {lang}”: Raw short caption (from WebLI-alt)
- “caption {lang}”: Nice, COCO-like short captions
- “describe {lang}”: Longer, more descriptive captions
- “ocr”: Optical character recognition
- “answer {lang} {question}”: Question answering about the image contents
- “question {lang} {answer}”: Question generation for a given answer
- “detect {object} ; {object}”: Locate listed objects in an image and return the bounding boxes for those objects
- “segment {object}”: Locate the area occupied by the object in an image to create an image segmentation for that object
Let’s explore the major applications of VLMs, demonstrating their vast potential across different domains.
1. Image Captioning
One of the most prominent applications of Vision Language Models is Image Captioning. Image captioning involves generating natural language descriptions of the contents of an image. This task requires a deep understanding of both visual features and the contextual meanings of objects in the scene.
prompt = “segment dog”2. Visual Question Answering (VQA)
Visual Question Answering (VQA) allows users to ask specific questions about the content of an image, and the model answers based on the visual information present. VQA requires the model to both “see” and “understand” the image to provide a relevant response.
prompt = 'answer What dog breed and color it is?n'golden retriever3. Counting
Vision Language Models can be used to count the number of specific objects within an image. This task, often known as object counting, is valuable for applications in inventory management, surveillance, and analysis.
prompt = 'answer how many persons are there?n'114. OCR
Optical Character Recognition (OCR) uses VLMs to extract text from images or scanned documents. This enables machines to read printed or handwritten text and convert it into editable, searchable formats.
prompt = 'Read text'Original:
59-K1 903.00
D48FD3D6 15/09/2016 07:39:40 Paligemma OCR:
59-K1 903.00
D48FD3D6 15/09/2016 07:38:405. Chart Interpretation
VLMs can be used to interpret charts and graphs by understanding the visual elements of the chart (axes, labels, data points) and generating corresponding textual explanations.
prompt = ‘What is the total liabilities and stackholders equity as of 2023?’
$ 402,3926. Clock Face Recognition
Clock Face Recognition enables models to recognize the time shown on analog clocks. This is an interesting use case of VLMs that blends visual understanding with text or numerical output.
prompt = 'answer What is the time now?n'1:06Advanced Applications
7. Grounding Referring Object Detection – Zero Shot
Grounding referring object detection in a zero-shot setting allows a model to detect and identify objects in an image based on textual references, without needing prior examples for training. The term “zero-shot” refers to the model’s ability to generalize to unseen data.
Applications:
- Autonomous Vehicles: Detect and track objects (e.g., pedestrians, vehicles) based on natural language commands.
- Human-Robot Interaction: Enable robots to follow verbal instructions and interact with their environment based on textual input.
- Smart Surveillance: Identify specific people, objects, or actions in security footage using descriptive queries.
detect_prompts = [
"detect personn",
"detect dogn",
"detect catn"]8. Grounding Referring Segmentation – Zero Shot
Grounding referring segmentation involves segmenting specific objects in an image based on textual descriptions, again in a zero-shot manner. This enables pixel-level object identification directly from text.
Applications:
- Medical Imaging: Segment specific organs or anomalies in CT scans or MRI images based on textual descriptions.
- Satellite Imagery: Identify and segment specific areas or features, such as bodies of water or urban areas, based on a query.
- Robotic Vision: Help robots isolate and interact with specific objects in their environment.
segmentation_prompts = [
"segment personn",
"segment dogn",
"segment catn"]Conclusion
In the coming years, Multi modals will increasingly underpin systems that need to bridge sight and speech, whether that’s giving voice to images for users with vision impairments, powering real-time analytics in manufacturing and logistics, or even co-creating art and design. By treating images as just another form of “text,” these models unlock a unified interface for interacting with the visual world.
As you integrate PaliGemma 2 into your projects, you’ll discover new shortcuts for complex tasks: asking questions of images instead of writing bespoke detection pipelines, generating multilingual captions without separate translation steps, or automatically annotating datasets with semantic labels. The era of hand-crafted vision modules is giving way to versatile, prompt-driven solutions that learn from vast, responsibly curated data.
Whether you’re building assistive applications, intelligent surveillance, data-driven dashboards, or generative art tools, PaliGemma 2 offers a single, adaptable foundation. Its powerful combination of SigLIP’s visual features and Gemma 2’s language prowess makes it a compelling choice for any vision-language challenge. Unlock that potential today, and let your next project see and describe the world in ways you’ve only imagined.
The post Applications of Vision Language Models – Real World Use Cases with PaliGemma2 Mix appeared first on OpenCV.