In Boston, a groundbreaking study at Brigham and Women’s Hospital explored the impact of Speech Recognition (SR) on electronic health record (EHR) documentation-and the results were eye-opening. Experienced physicians participated in simulated outpatient scenarios, documenting patient notes using both speech recognition and traditional typing methods. The findings revealed that Speech Recognition notes were significantly more detailed (320.6 words vs. 180.8) and higher in quality, offering better clarity, completeness, and information. What’s more, the time spent documenting was similar between both methods, but SR allowed physicians to capture more relevant details with fewer mistakes.
Building on these advancements, speech recognition technology continues to evolve as we step into 2025. Its applications are becoming integral across various sectors worldwide, driving efficiency and innovation. The market for speech recognition is projected to grow exponentially, reaching a multi-billion dollar valuation by the end of the decade. Powered by advancements in artificial intelligence (AI) and deep learning, today’s speech recognition systems offer unprecedented accuracy and speed, expanding their usability in daily life and business operations alike.
With an estimated growth rate of 17.2% and a projected market value of $26.8 billion by 2025, speech recognition is poised to become an indispensable part of our daily lives.
Let’s dive deeper into the world of speech recognition and uncover its many applications shaping our future.
What is Speech Recognition?
Speech recognition, sometimes referred to as speech-to-text (STT), is a technology that enables computers to convert spoken language into written text. This process involves analyzing the acoustic signals produced during speech and matching them to the corresponding words or phrases in a given language. Speech recognition algorithms have evolved to understand natural speech in different languages, dialects, accents, and speech patterns.
The term “automatic speech recognition” was coined by engineers in the early 1990s to emphasize that this technology relies on machine processing. Over time, ASR and speech recognition have become synonymous, and the technology has become more sophisticated, enabling it to handle complex linguistic structures and context-specific nuances.
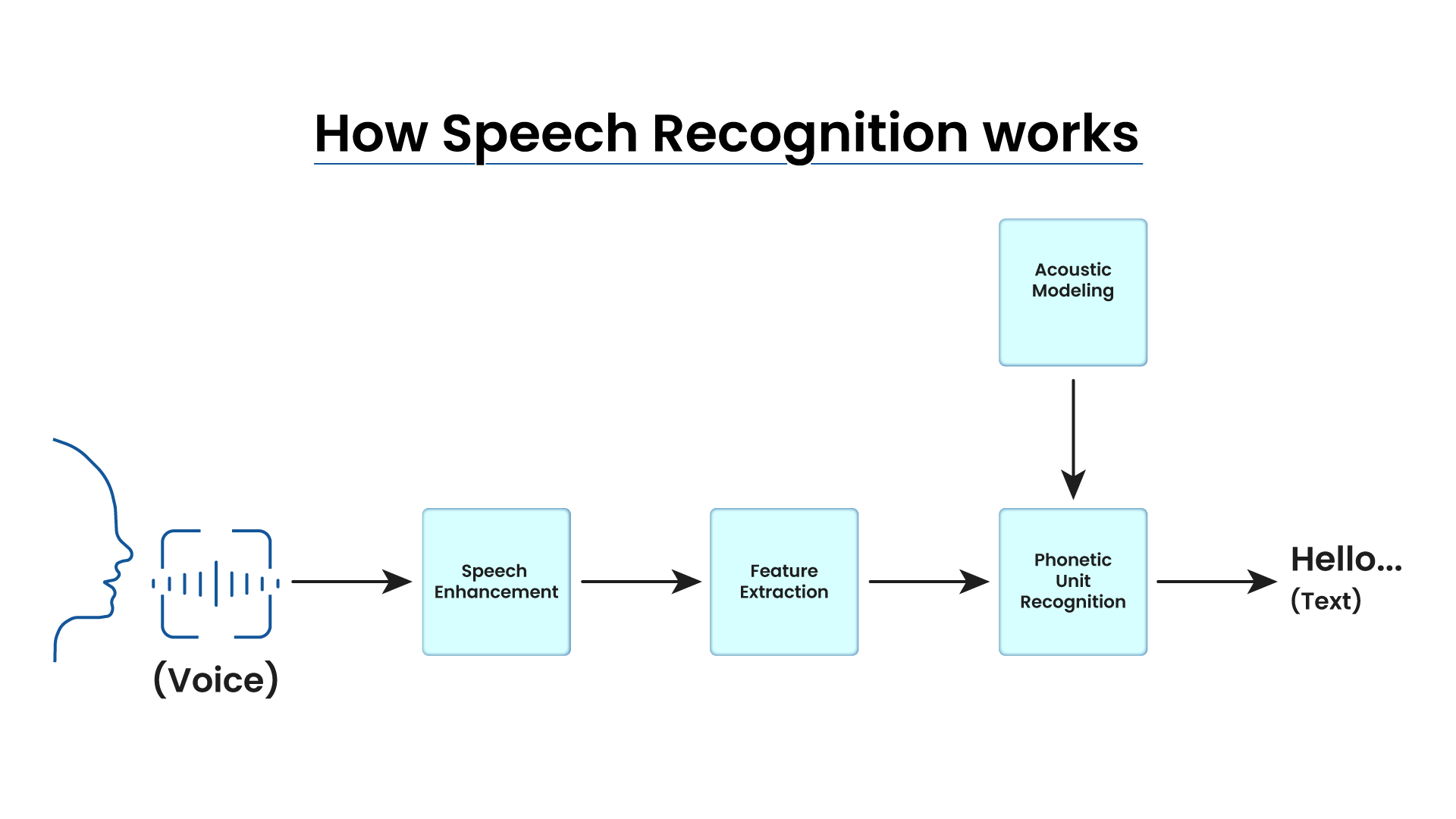
How It Works
At its core, speech recognition technology involves several complex processes that work together to convert spoken language into text. Here are the key components and steps involved in this process:
1. Acoustic Models:
Acoustic models are used to represent the relationship between the audio signals and the phonetic units of speech. These models are trained using large datasets of recorded speech and their corresponding transcriptions. The goal is to capture the variations in speech sounds and their acoustic properties.
2. Language Models:
Language models are used to predict the likelihood of word sequences in a given language. These models help the system understand the context and structure of the language, making it easier to transcribe spoken language accurately. Language models are typically trained on vast corpora of written text.
3. Signal Processing:
Signal processing involves analyzing the audio signals produced during speech and converting them into a digital format that can be processed by the computer. This step includes noise reduction, feature extraction, and transformation of the audio signals into a form that the speech recognition system can understand.
4. Machine Learning and Natural Language Processing (NLP):
Machine learning and NLP are crucial components of speech recognition technology. Once the system receives the input speech signal, it uses machine learning algorithms to generate word sequences that best match the input. NLP techniques help in understanding the linguistic context and producing a readable transcription that the user can further process or correct.
5. Steps in Speech-to-Text Conversion
The process of converting speech to text involves the following steps:
- Translating sound vibrations into electrical signals.
- Digitizing the signals.
- Analyzing the digital signals.
- Matching the signals with suitable text representing the sounds.
As simple as this process may sound, speech recognition technology is incredibly complex. It involves multiple layers of processing and analysis to ensure accurate transcription.
Speech vs. Voice Recognition
While both speech and voice recognition involve auditory inputs, their purposes differ significantly:
- Speech Recognition focuses on what is being said, disregarding who is speaking. Its primary goal is to convert speech into text or commands that a computer can understand.
- Voice Recognition is designed to identify who is speaking by analyzing voice patterns. This technology is often used for security purposes, such as verifying the identity of a speaker in biometric systems.
Types of Speech Recognition
- Automatic Speech Recognition (ASR): Automatically converts speech into text without the need for manual intervention. This technology underpins many virtual assistants and voice-controlled applications we use today.
- Speaker-Dependent Systems: These systems require training on a specific user’s voice to accurately interpret commands. They are typically used in environments where the system interacts with a single user, such as personalized accessibility setups.
- Speaker-Independent Systems: Capable of understanding speech inputs from any speaker without prior training, these systems are essential for public and commercial services where multiple users interact with the technology.
Applications in Various Industries
Smart Homes
According to a report by MarketsandMarkets, the global smart home market is projected to grow from $84.5 billion in 2021 to $138.9 billion by 2026, at a CAGR of 10.4% during the forecast period.
In smart homes, speech recognition technology transforms how homeowners interact with their living environments. Users can use voice commands to control a wide range of home automation systems—adjusting lighting levels, setting thermostats, activating security systems, and managing home entertainment devices. This hands-free control increases convenience and enhances energy efficiency by allowing precise control over home utilities, ensuring that lights and heating are only on when needed.
Customer Service
The AI customer services market is poised for significant growth, projected to reach nearly $3 billion by 2032, up from $308 million in 2022(source). This rapid expansion is driven by AI’s ability to handle increasingly complex customer interactions, enhancing personalized service and satisfaction. In fact, by 2025, AI is expected to facilitate 95% of customer interactions, showcasing its integral role in future customer service strategies.
Speech recognition has revolutionized the customer service landscape by enabling more efficient and responsive interaction systems. Automated customer service platforms, equipped with speech recognition capabilities, can swiftly handle basic inquiries and support tickets, significantly reducing wait times. More complex IVR (Interactive Voice Response) systems are capable of understanding and responding to customer queries without human intervention, directing callers to the appropriate department or providing immediate answers to common questions.
Automotive
The market for automotive voice recognition is robust, with projected growth from $2.81 billion in 2024 to $3.2 billion in 2025, further expanding to $5.58 billion by 2029 due to these technological advancements and increased vehicle automation (source).
In the automotive industry, speech recognition enhances safety and convenience by allowing drivers to operate hands-free navigation, communication, and entertainment systems. This minimizes driver distraction, a significant factor in road safety, by keeping their hands on the wheel and eyes on the road. Drivers can ask for directions, send messages, and control music without ever touching a device, making the driving experience safer and more enjoyable.
Travel
The global market for AI in the travel industry, including speech recognition applications, is projected to grow significantly. According to industry forecasts, the market could see an increase from $2 billion in 2024 to an estimated $4 billion by 2029, driven by a growing demand for automation and personalized travel solutions.
The travel industry benefits from speech recognition by offering more seamless and accessible customer service options. Travelers can interact with voice-activated kiosks to quickly obtain flight information, check in, book tickets, and get travel advice without waiting in line for a customer service representative. This technology enhances the customer experience at airports, hotels, and tourist attractions, making travel smoother and more enjoyable.
Transcription Services
The transcription services market is experiencing robust growth, particularly in the U.S., where it is projected to reach a size of $41.93 billion by 2030, growing at a compound annual growth rate (CAGR) of 5.2% from 2025 to 2030 (Source).
Speech recognition technology significantly expedites the transcription process in various fields such as legal, medical, and media. By accurately converting spoken language into text, it provides a fast and efficient way to create written records of meetings, interviews, court proceedings, medical consultations, and broadcasts. This not only saves time but also ensures that records are accurate and accessible for future reference.
Virtual Assistant
The global virtual assistant market is expected to grow to $19.66 billion by 2029, with a compound annual growth rate of 24.6%. This growth is largely driven by the increasing adoption of smart devices, which integrate virtual assistants to provide enhanced user experiences through voice commands(source).
Virtual assistants powered by speech recognition are increasingly becoming a staple in personal and professional lives. They assist users in managing daily tasks with simple voice commands. Tasks like setting reminders, making appointments, sending messages, or conducting internet searches can be performed without manual input. This hands-free assistance is particularly helpful when users are engaged in other activities, allowing multitasking with ease.
Public Safety & Law Enforcement
In the realm of public safety and law enforcement, speech recognition technology plays a critical role by allowing officers and emergency responders to access information and document incidents without physically interacting with devices. This capability is vital in high-stress environments where hands-free operation can save time and potentially lives. Officers can perform background checks, call up license data, and enter incident reports into systems all through voice commands, enabling them to stay alert and focused on their surroundings.
Accessibility Features
Speech recognition technology is profoundly impactful for individuals with physical disabilities. It provides an essential means of interaction with technology, enabling them to control computers, smartphones, and other smart devices entirely through voice. This not only fosters greater independence but also ensures that technology is inclusive, allowing individuals who might be unable to use traditional input methods to fully engage with digital content and services.
Related Reads: Speech-to-Speech
Challenges and Limitations
While speech recognition technology offers numerous benefits, it also faces several challenges and limitations:
1. Accuracy Issues with Different Accents and Dialects
Speech recognition systems may struggle to accurately transcribe speech with different accents, dialects, and speech patterns. This can affect the accuracy and reliability of the transcription.
2. Background Noise and Environmental Factors
Background noise and environmental factors can interfere with the accuracy of speech recognition systems. Ensuring clear and noise-free audio input is essential for reliable transcription.
3. Privacy and Security Concerns
Speech recognition technology raises privacy and security concerns, particularly when sensitive information is being transcribed. Ensuring robust data protection measures is crucial to address these concerns.
4. Dependence on High-Quality Data for Training Models
The performance of speech recognition systems depends on the quality of the data used to train the models. Ensuring access to diverse and high-quality datasets is essential for improving the accuracy and reliability of the technology.
Future of Speech Recognition: Expanding Horizons
The future of speech recognition holds immense promise as technological advancements continue to evolve. We are on the cusp of seeing systems that not only comprehend but also predict and respond to user needs with unprecedented accuracy. Future developments are expected to focus on several key areas:
- Contextual Understanding: Future speech recognition systems will excel in understanding the context behind conversations. This involves recognizing the setting or subject matter of discussions and adjusting responses accordingly, providing much more relevant and timely information.
- Emotional Intelligence: Recognizing and responding to emotional cues in speech is another frontier. Upcoming models will likely interpret variations in tone, pace, and pitch to gauge emotions, enhancing interactions by offering empathetic responses or adjusting the flow of conversation based on the user’s mood.
- Multilingual Support: As globalization continues, the demand for multilingual speech recognition systems will rise. Future advancements will ensure seamless support for multiple languages, including dialects and accents, thus broadening the accessibility and utility of speech-based interfaces globally. Interestingly, technologies like ChatGPT have already made significant strides in this area, offering support for multiple languages and understanding nuanced accents and dialects, making them accessible to a diverse user base worldwide.
- Increased Precision: Accuracy in speech recognition is set to improve, with errors becoming increasingly rare. This will be driven by more sophisticated neural networks that can learn from vast datasets without human oversight, reducing biases and misunderstandings.
- Anticipatory Interaction: Beyond reactive systems, the next generation of speech recognition technologies will proactively offer assistance based on predictive analytics. For example, if a calendar suggests a meeting soon, the system might preemptively offer traffic updates or set reminders without prompt.
- Integration Across Devices: Future speech recognition will be deeply integrated into virtually all types of technology, from wearable tech to IoT devices, creating a cohesive ecosystem where users can interact with multiple devices through a unified voice interface.
- Privacy Enhancements: As voice interfaces become more common, ensuring privacy and security of voice data will be paramount. Future advancements will likely include robust encryption methods and local processing to safeguard user data.
Conclusion
Speech recognition technology has come a long way since its inception, evolving into a powerful tool that enhances efficiency, accessibility, and user experience across various industries. From healthcare and automotive to customer service and education, the applications of speech recognition are diverse and impactful.
While the technology offers numerous benefits, it also faces challenges such as accuracy issues with different accents and dialects, background noise, privacy concerns, and the need for high-quality training data. However, continuous advancements in AI and machine learning, along with the integration of emerging technologies, promise to overcome these challenges and unlock new possibilities for speech recognition.
The future of speech recognition is bright, with expected market growth and innovative applications on the horizon. As this technology continues to evolve, it will play an increasingly important role in our lives, empowering us to communicate, interact, and achieve more with the power of our voice.
The post Speech Recognition and its Applications in 2025 appeared first on OpenCV.