The process of training a deep learning model requires managing many different steps and components. From data preparation to model evaluation, each step is crucial to ensure the model’s success.
This checklist is designed to guide you through every essential stage, helping you avoid common pitfalls and build a model that performs well in real-world scenarios.
1. Data Validation
High-quality data is the backbone of any deep learning model. Even the most sophisticated algorithms won’t perform well on poor data. Here’s how to make sure your data is ready for training:
- Ensure Data Quality: Start by examining your data for issues like corrupted files, missing entries, or any signs that the data may not be suitable for training. Spotting these problems early on can save you from headaches later.
- Data Cleaning: It’s common to find errors, missing values, or inconsistencies in raw data. Address these issues by removing or fixing problematic entries and filling with NAN or mean values where necessary. This cleanup step ensures that your data is accurate and consistent.
- Data Consistency: Check that your data follows a uniform format and scale across all variables. For example, if you’re working with images, ensure they’re all the same size and resolution. Consistency across data helps the model learn reliably and minimizes the risk of variability affecting model performance.
- Outliers and Anomalies: Outliers can skew model performance and lead to inaccurate results. Identify any unusual data points and decide whether to exclude them, transform them, or account for them with regularization in a way that won’t distort your model’s learning.

2. Data Preparation
Once your data is validated, it’s time to prepare it for the model. Proper preparation aligns your data with the model’s requirements, enhancing the learning process. Key steps include:
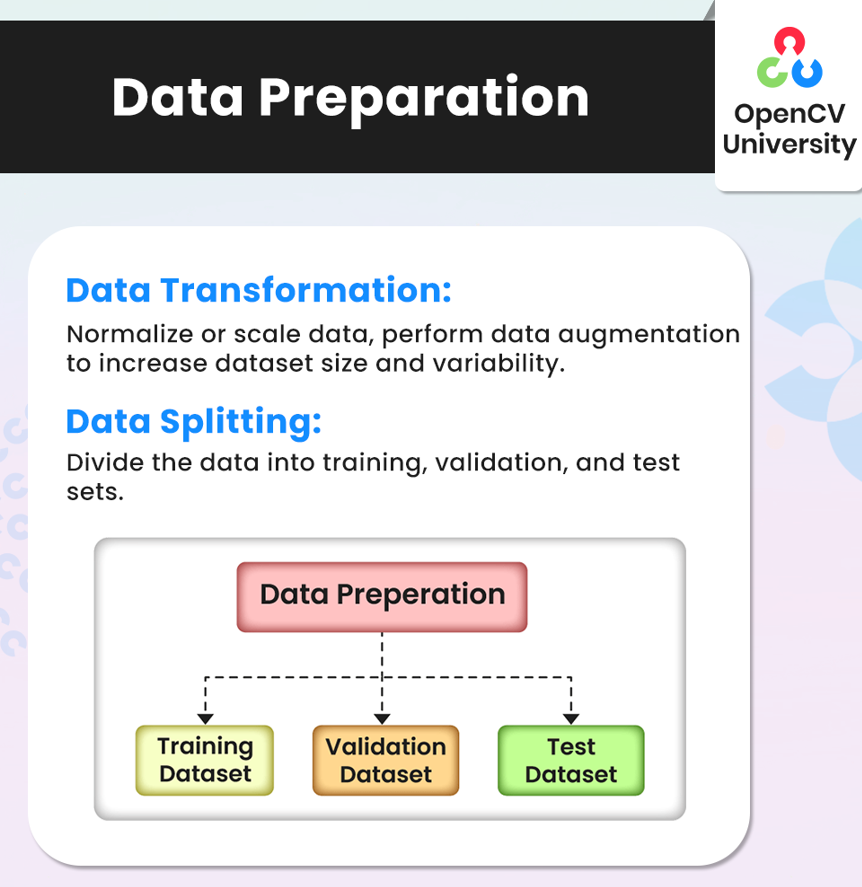
- Data Transformation: Normalize or scale your data so that values are on a similar scale, helping the model learn patterns more efficiently. For images, you might perform data augmentation, like rotating or flipping, to introduce more variability. This process can improve the model’s ability to generalize to new data by exposing it to diverse representations of similar content.
- Data Splitting: Divide your dataset into three parts—training, validation, and test sets. The training set is used to fit the model, the validation set helps tune it, and the test set evaluates the final model’s performance. This division ensures that your model is learning on unseen data at each stage, reducing the risk of overfitting.
3. Data Visualization
Before jumping into model training, it’s helpful to get a visual understanding of your data. Visualization can reveal hidden patterns, relationships, and potential issues, guiding your approach to model design and feature engineering.
- Exploratory Data Analysis (EDA): Use plots and charts to explore data distributions, trends, and relationships. Histograms, scatter plots, and box plots are great tools for understanding the spread and central tendencies of your data. EDA helps you grasp the data’s basic characteristics.
- Feature Correlation: Analyze how different features interact with each other and with the target variable. Correlation heatmaps, for example, can show which features are strongly related to the outcome you’re predicting. This step can reveal which features might be more important or if there’s redundancy among them.
- Insight Extraction: Gleaning insights from your data can be useful for choosing which features to prioritize or engineer further. For instance, if you find that certain features have a strong influence on the target, you may want to emphasize them in feature selection.

4. Model Architecture
Choosing the right model architecture is a pivotal step. The model’s structure directly impacts how well it can learn patterns in the data. Consider the following steps to set up an effective model:
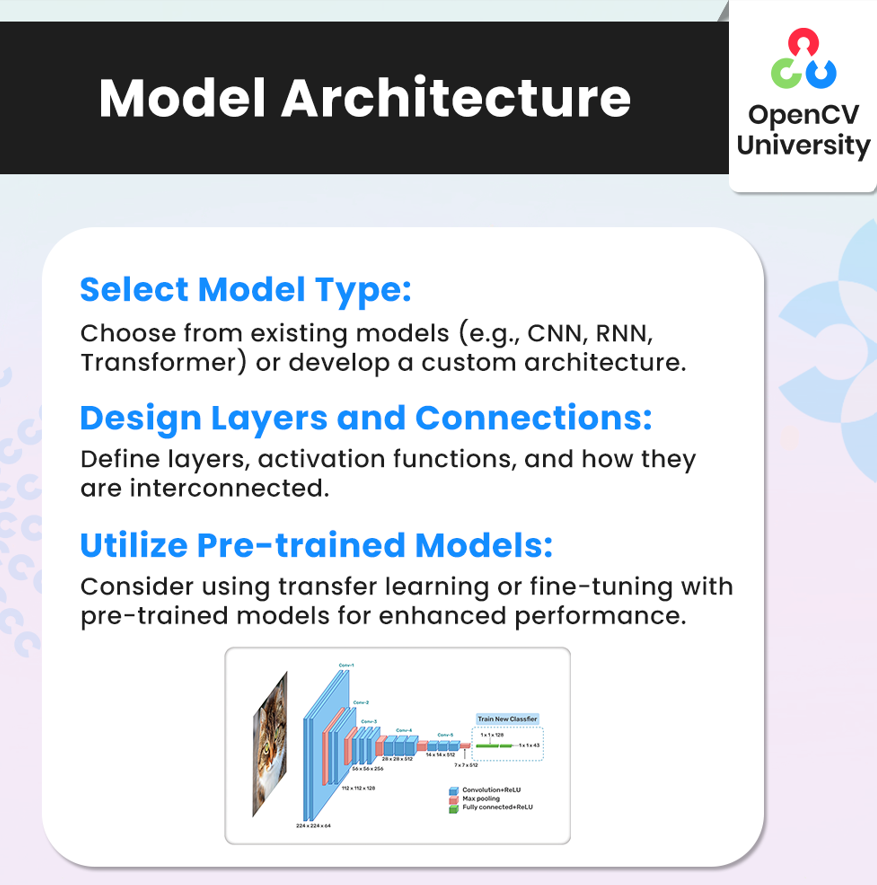
- Select Model Type: Different problems call for different models. For example, Convolutional Neural Networks (CNNs) work well for image tasks, while Recurrent Neural Networks (RNNs) and Transformers are effective for sequences, like text. Select a model type that aligns with your data and goals.
- Design Layers and Connections: Define the layers of your model and choose the right activation functions. Decide on the depth of your model and how layers connect to each other. For example, deep architectures may capture complex patterns better but might need more data to train effectively.
- Utilize Pre-trained Models: Instead of starting from scratch, consider using pre-trained models through transfer learning. This can speed up training, especially if you’re working with limited data, and often leads to better performance as the model builds on prior knowledge.
5. Training Hyper-parameters
Hyper-parameters play a big role in how effectively your model learns. They control various aspects of the training process, so finding the right combination can make a significant difference.
- Learning Rate: The learning rate dictates how quickly the model updates its weights. A high learning rate might skip over optimal values, while a low one may make training too slow. Experiment with different rates to find the optimal balance.
- Batch Size: Batch size determines how many samples the model processes in each iteration before updating its weights. Smaller batches allow for quicker updates but can be noisy, while larger batches are more stable but require more memory. Choose a batch size that fits your hardware and keeps training efficient.
- Number of Epochs: The number of epochs is how many times the model will go through the training dataset. Too few epochs can lead to underfitting, while too many can cause overfitting. Use early stopping or validation performance to decide when to halt training.
- Choice of Optimizer: Different optimizers affect how weights are updated. Common choices include Adam, RMSProp, AdaDelta, and SGD. Experiment to see which optimizer works best for your task, as each has unique advantages depending on the dataset and problem type.

6. Training Process
With your hyper-parameters set, you’re ready to train the model. This step involves compiling the model, training it on data, and monitoring its progress.
- Model Compilation: Compile the model with your chosen optimizer, loss function, and metrics. For example, classification tasks often use cross-entropy loss, while regression tasks may use mean squared error. Defining the right settings here helps the model learn in a way that aligns with your objectives.
- Model Fitting: Train the model on your training dataset and monitor its performance on the validation set. This process is iterative, and you’ll adjust hyper-parameters based on how the model performs. Track metrics like accuracy or loss to get a sense of how well the model is learning.
- Checkpointing: Save the model at intervals or when improvements are observed. This allows you to retain a version of the model at its best performance, making it easier to revert if further training leads to overfitting. Regular checkpointing also protects your work if something interrupts training.

7. Evaluation
Evaluating your model’s performance is essential to understand how well it will perform in real-world scenarios. This step highlights strengths and areas for improvement.
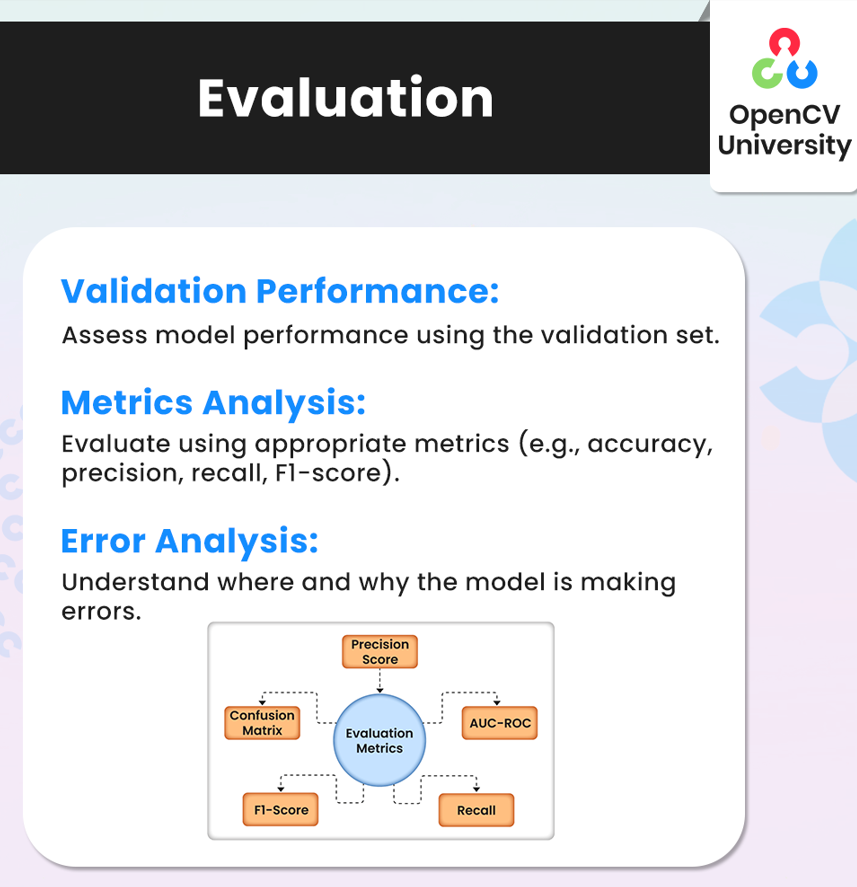
- Validation Performance: Use the validation set to gauge the model’s accuracy. This performance check helps ensure the model is not just memorizing the training data but is also able to generalize.
- Metrics Analysis: Depending on your task, evaluate the model with appropriate metrics, such as accuracy, precision, recall, and F1-score. These metrics give a more detailed picture of model performance, especially for imbalanced datasets or tasks where accuracy alone isn’t enough.
- Error Analysis: Identify where the model is making mistakes. By examining these errors, you can often find patterns that point to areas for improvement, such as additional data cleaning, more feature engineering, or adjusting the model’s architecture.
8. Inference
Once your model is trained and evaluated, it’s ready for inference—making predictions on new data. Inference is where the model’s performance truly matters, as it’s now being used for real-world data. Follow these steps to ensure smooth and accurate predictions:
- Model Loading: Load the trained model in an environment where it will be used for predictions. This could be in a production server, a web application, or on a local machine for testing.
- Data Processing: Ensure that the input data for inference is processed in the same way as your training and validation data. Consistency in preprocessing steps (like normalization or resizing) is crucial to avoid performance issues caused by mismatched data formats.
- Prediction: Use the model to generate predictions on new data. As part of this process, you may want to run tests with a small subset of data where the expected outcomes are known. This helps confirm that the model behaves as expected in inference. This is a good time to confirm that inference speed and resource usage meet your requirements, especially if you’re deploying at scale.

9. Deploy
Deploying a model involves setting it up for consistent use and monitoring its performance over time. Consider these steps to ensure a reliable deployment:
- Deployment Strategy: Decide on the deployment approach based on your needs. Options include cloud deployment for scalability, on-premises for privacy, or edge deployment for real-time applications with low latency.
- Monitoring: After deployment, set up monitoring to track the model’s performance and detect issues like data drift (when new data deviates from the training data). By keeping an eye on the model’s accuracy and other metrics, you can detect problems before they affect users.
- Updates and Maintenance: Models need to evolve to stay relevant and accurate. Plan for regular updates, especially if your data changes over time. Periodic retraining with new data can help the model stay up-to-date and effective.
Conclusion
Training a deep learning model can seem daunting, but following a structured checklist makes it manageable and effective. By focusing on each step—from data validation to deployment—you’re setting your model up for success in real-world scenarios.
This approach not only improves performance but also saves time by preventing costly mistakes. Remember, the quality of each step contributes to the overall success of the model, so taking the time to follow best practices can pay off in the end.
The post Deep Learning Model Training Checklist: Essential Steps for Building and Deploying Models appeared first on OpenCV.