Introduction
What is Generative AI? It’s a question that looms in most of our minds. Generative AI has gained huge traction during the past few years. With ChatGPT blowing up during November 2022, there is no going back!
Various industries are adopting Generative AI for interesting applications like content generation, marketing, engineering, research, and general documentation.
What is Generative AI?
Generative AI is a form of Artificial Intelligence used to generate content in the form of text, imagery, or audio. Deep learning models are trained on large amounts of data to generate such responses.
History of Generative AI
Gen AI first took the form of Chatbots in the 1960s. In this section, we’ll look at the timeline of important events that led to the boom of Generative AI we know today.
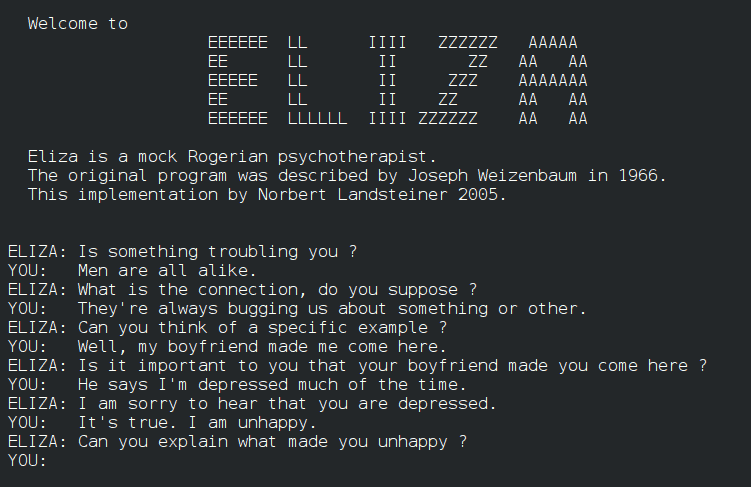
1966: MIT professor Joseph Weizenbaum develops Eliza, the first chatbot that simulates psychotherapist conversations. A significant early breakthrough in natural language understanding and human-computer interaction was Eliza’s ability to respond to users using pattern matching and simple language processing techniques.
1968: Terry Winograd at MIT developed the SHRDLU program, a groundbreaking program that demonstrated natural language understanding in a limited domain. Using SHRDLU, users manipulated objects based on commands issued in English. The success of the project highlighted the potential for artificial intelligence to comprehend and execute complex instructions in real-life situations.
1985: Bayesian networks emerged as a powerful tool in artificial intelligence for probabilistic modeling and causal analysis. Through the representation of probabilistic relationships between variables using directed acyclic graphs, Bayesian networks provide reasoning under uncertainty and can be used for diagnostics, prediction, and decision-making.
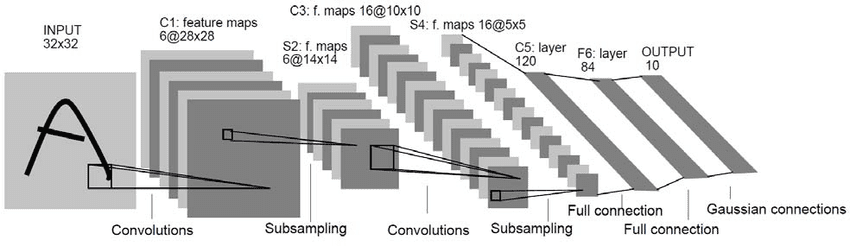
1989: Yoshua Bengio, Yann LeCun, and Patrick Haffner revolutionized image recognition with Convolutional Neural Networks (CNNs). With CNNs, visual data can be processed more accurately and efficiently than traditionally using conventional methods due to shared weights and convolutions. Computer vision systems and deep learning applications were based on this breakthrough.
2000: Yoshua Bengio and others introduce Neural Probabilistic Language Model, a neural network-based approach to language modeling in 2000. Natural language processing tasks such as speech recognition, machine translation, and text generation are enhanced by capturing contextual dependencies and learning distributed representations of words.
2011: A huge moment in consumer AI technology with Apple’s Siri, a voice-activated virtual assistant. With Siri, users can use their voice commands to interact with their devices, setting a new standard for personalized and intuitive user experiences.
2013: Tomas Mikolov introduces word2vec, a transformative technique for word embeddings in natural language processing. Word2vec uses neural networks to learn continuous vector representations of words, capturing semantic relationships and contextual similarities. This advancement enhances the quality of word representations and contributes to improvements in various NLP tasks like sentiment analysis, named entity recognition, and document clustering.
2014: Generative Adversarial Networks (GANs) are developed by Ian Goodfellow and colleagues, introducing a novel framework for generative modeling. GANs consist of two neural networks, a generator and a discriminator, engaged in a game-like training process. This approach enables the generation of realistic synthetic data, leading to applications in image synthesis, style transfer, and data augmentation.
2017: “Attention Is All You Need”, Vaswani et al. introduces transformers that is game changing in natural language processing. By using self-attention mechanisms to capture long-range dependencies in sequences, transformers outperform previous architectures in tasks such as machine translation, text summarization, and language understanding. Several state-of-the-art NLP models, including BERT and GPT, are based on the Transformer model.
2018: Researchers at Google AI develop BERT (Bidirectional Encoder Representations from Transformers) to improve natural language understanding. Using BERT, context is captured from both left and right contexts through a bidirectional training and transformer architecture, resulting in significant improvement in tasks such as answering questions, analyzing sentiment, and classifying texts. As a result of BERT’s pretraining strategy and contextualized embeddings, a new standard is set for language representation learning.
2021: OpenAI introduces the DALL-E AI model in 2021, which generates images from textual descriptions. To generate diverse and creative visual outputs based on user inputs, DALL-E combines transform architecture with large-scale image-text pairs.
2022: New model GPT-3.5 marks a milestone in LLMs. It demonstrates advanced capabilities in natural language understanding, generation, and conversation, demonstrating the development of deep learning-based language models and their application to chatbots, virtual assistants, and text-based AI systems.
2023: GPT-4 comes to the scene, showcasing further advances in generative AI. This new model has better language understanding, context retention, and text generation compared to the previous models.
2024: This year has been the year for Generative AI to shine with the likes of Stable Diffusion 3, Vlogger, Claude 3, Devin AI, and even ChatGPT-5 launching mid-year.
How do Generative AI models work?
LLMs or Large Language Models have billions of parameters that can generate engaging content or photorealistic images. It forms an integral part of Natural Language Processing (NLP) and Generative AI and performs well for tasks like text summarization or language translation. Let us take the instance of ChatGPT-4, the latest GPT model. It is an LLM that constitutes 1.7 trillion parameters that were trained on a corpus of text data.
On the other hand, Transformers form the building blocks of LLMs. Transformers outperform RNNs (Recurrent Neural Networks) and LSTMs (Long short-term memory) due to their “attention” mechanism. Models can focus on different parts of the input sequence for every output token. For instance, GPT is able to give such quick responses due to the parallel processing of sequential data.
Now that we’ve seen the brain behind Generative AI models let us look at how they work.
Gathering Data
The process starts with collecting a large and diverse dataset relevant to the task the model will perform. This could include text, images, or a combination of both, depending on the model’s purpose.
Preprocessing
The next step is preprocessing, where the gathered data is cleaned and formatted. For instance text data preprocessing could be tokenization, removing stop words, handling special characters, or converting text into numerical representations.
Defining Model Architecture
Then, there is selecting the right model architecture, which is crucial. This could be selecting the right Transformers, which are deep learning models specifically designed for sequence tasks. These architectures typically consist of multiple layers of attention mechanisms, enabling the model to capture long-range dependencies in the data.
Choosing the right architecture can vary based on
Complexity: Depending on what we are working with, one can pick a simple or complex model for the desired outcome.
Data Requirements: Do we need a large dataset, or will limited data work? This depends on how effectively we want to train the model.
Training Time: Some models train fast, while some need a longer time but produce better results. This factor purely depends on the given timeframe one has to work with.
Compatibility: This involves seamless integration to check if the given model is aligned with the existing hardware or framework.
Model Pre-training
After selecting the right model architecture, model pre-training is done on vast amounts of unlabeled data. Here, the model picks up on general language patterns, semantics, and contextual understanding, making it capable of generating coherent and context-aware text.
Model Optimization
This step optimizes the model to enhance its performance and efficiency. This can be achieved through techniques like gradient descent optimization, learning rate tuning, regularization methods, and model architecture adjustments to improve overall performance metrics.
Fine-tuning
We’ve come to the final step. Fine-tuning adapts the pre-trained model’s knowledge to the nuances of the target task, such as text generation, translation, summarization, or question-answering.
Now that we’ve looked at how Gen AI models work, we’ll explore some of the most common types of Generative AI.
Types of Generative AI
Now that we’ve a better understanding of Generative AI, let us look at some of the most common ones.
Text Generation
This is one of the most common forms of Gen AI used out there. We’ve all used this in some form or another. Text generation involves an AI tech generating contextual, meaningful, and coherent texts that possess close resemblance to how humans would put out responses. It has gained immense popularity in content generation, like writing email copies, social media content and even blog writing. Some of the most commonly used text generation tools include OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude.
GPT in action
Text to Image/Video Generation
Content generation hit a whole new level with the introduction to text-to-image and text-to-video AI generation tools. They use Natural Language Processing (NLP) techniques and Deep Learning to generate images and videos from textual descriptions. Use cases include video production, asset creation, and content creation. Google’s Imagen, Midjourney, and OpenAI’s SORA are a few text-to-image and text-to-video generation AI tools.
Image to Video Generation
Videos are one of the best forms of storytelling, but creating them can be daunting. Imagine doing it just with an image. That brings us to image-to-video AI generation. Unlike the former Gen AI tools where the input was a text, here we have an image. With tools like StabilityAI’s Stable Diffusion 3, Google’s Vlogger, and Runway’s Gen-2, we can turn boring static images into dynamic and captivating videos.
Text-to-Speech and Speech-to-Text Generation
Text-to-speech converts texts to spoken words, while speech-to-text transcribes audio into text. Both serve their own purposes; for instance, text-to-speech can serve as voice assistants or tutorials, whereas speech-to-text offers transcripts, dictation, or voice commands. Some of the most common speech-to-text tools include AssmeblyAI, OpenAI’s Whisper, AWS Transcribe, and Deepgram.
Code assistants
Generative AI has made an impact not only in content creation but also in Software development. Software engineers can now make their tasks less tedious with Code assistants. This could be generating code snippets or automating coding tasks. Github’s Copilot, BlackboxAI, and Hugging Face’s HuggingChat are some of the go-to code assistants for software engineers.

Use Cases of Gen AI
Content Creation
One of the most common use cases of Generative AI is content creation. Just with a few lines of input, you can generate hundreds of lines of content. Content creators can now save a ton of time on brainstorming content ideas and outlines for long-term content strategization and marketing.
Video Editing and Generation
Video editing and generation are other popular use cases in the Gen AI world. Here, one can produce high-quality video content just from textual input or even an image and at a fraction of the time taken by a human editor. Here, the model analyzes vast amounts of image and video data and generates coherent and appealing video content.
Heygen in action
Music Production
Generative AI can produce decent material for ads or branding initiatives. Like other Gen AI models that infer patterns from existing data, here it does so through musical data and generates similar-sounding music. Composers and Artists can explore the creative side of things and tread new genre territories.
Enhanced Medical Imaging
Gen AI, much like other use cases, has taken medical imaging up a notch. A huge challenge in medical imaging is the poor availability of data. This is fixed by leveraging Gen AI models like GANs (General Adversarial Networks) and VAEs (Variational Autoencoders). They can able to generate diverse and photorealistic images from existing data.
Chatbots
The oldest form of Generative AI, Chatbots have been with us for awhile, and it looks like they are here to stay. Over time, Chatbots are able to better understand customers and offer accurate and nuanced responses. Unlike their human counterparts, Chatbots are able to handle much larger volumes of queries and offer personalized responses.
Coding Tasks
As discussed earlier, Gen AI is not just confined to content creation. It extends its reach to the realm of software development. This could be code completion, fixing bugs, reviewing code, or code refactoring. Code assistants are able to streamline repetitive tasks like generating code or detecting errors giving devs room to focus on other pressing tasks.
Immersive Gaming
Gen AI can introduce new elements to the table, like characters or levels. By learning from existing game elements, the models can generate new ones, removing any monotony from the gaming experience. Brands like Ubisoft are leveraging Gen AI for game development and removing bugs.
Gen AI Challenges
Although generative AI brings much to the table, it poses some concerns. A few include privacy and infringement concerns. It’s crucial for Brands offering these tools to address such challenges through content moderation and ethical guidelines.
- Generative AI models require vast amounts of datasets for training. This could lead to sensitive information being leaked or misused.
- Another Gen AI concern is copyright infringement. With the models training on so much data constituting tons of articles from the internet, there is always a possibility of infringement.
- There is always a possibility of unfair outcomes where algorithms can unintentionally have biases while training or even amplify existing ones. The resulting biases can be explicit or violent and produce harmful content.
Future of Generative AI
Since its inception during the ’60s, to GANs blowing it past other fields in AI, Generative AI has quickly grown to become one of the top subfields of Artificial Intelligence. According to Delliote’s 2023 Creator Economy in the 3D survey, 94% of brands working with content creators are already leveraging or plan to use Generative AI.
Gen AI is the first of its kind AI tech, accessible to the masses and is usable by anyone to automate or augment tasks which otherwise needed skills to do by oneself.
As discussed in the previous section, it poses its own set of problems. Preparing the current and future workforce to be early adopters of Gen AI can make navigating through the ever-evolving field of Artifificial Intelligence easy.
Generative AI will not replace people but rather enhance their work. In the right hands, these tools can produce compelling and impressive results, be it content creation or fixing bugs in your code.
That’s a wrap of this fun, comprehensive read. We introduced ourselves to Generative AI and how it came to be what it is today, discussed how it works, and looked at some use cases.
See you guys in the next one!
The post What is Generative AI? Your 2024 Comprehensive Guide appeared first on OpenCV.