LongCat-Flash-Omni: A SOTA Open-Source Omni-Modal Model with 560B Parameters and 27B Activated, Excelling at Real-Time Audio-Visual Interaction
Understanding the Target Audience
The target audience for LongCat-Flash-Omni includes AI researchers, business managers in technology sectors, and developers interested in machine learning and multimodal AI applications. Their pain points involve:
- Integrating complex AI models into existing systems.
- Ensuring real-time interaction capabilities without sacrificing performance.
- Accessing open-source tools that can be customized for specific needs.
Goals include improving operational efficiency through AI, enhancing user interaction experiences, and staying competitive in the rapidly evolving tech landscape. Interests often revolve around advancements in AI, machine learning frameworks, and practical applications of multimodal models. Communication preferences lean towards technical documentation, peer-reviewed research, and hands-on tutorials.
Model Architecture and Features
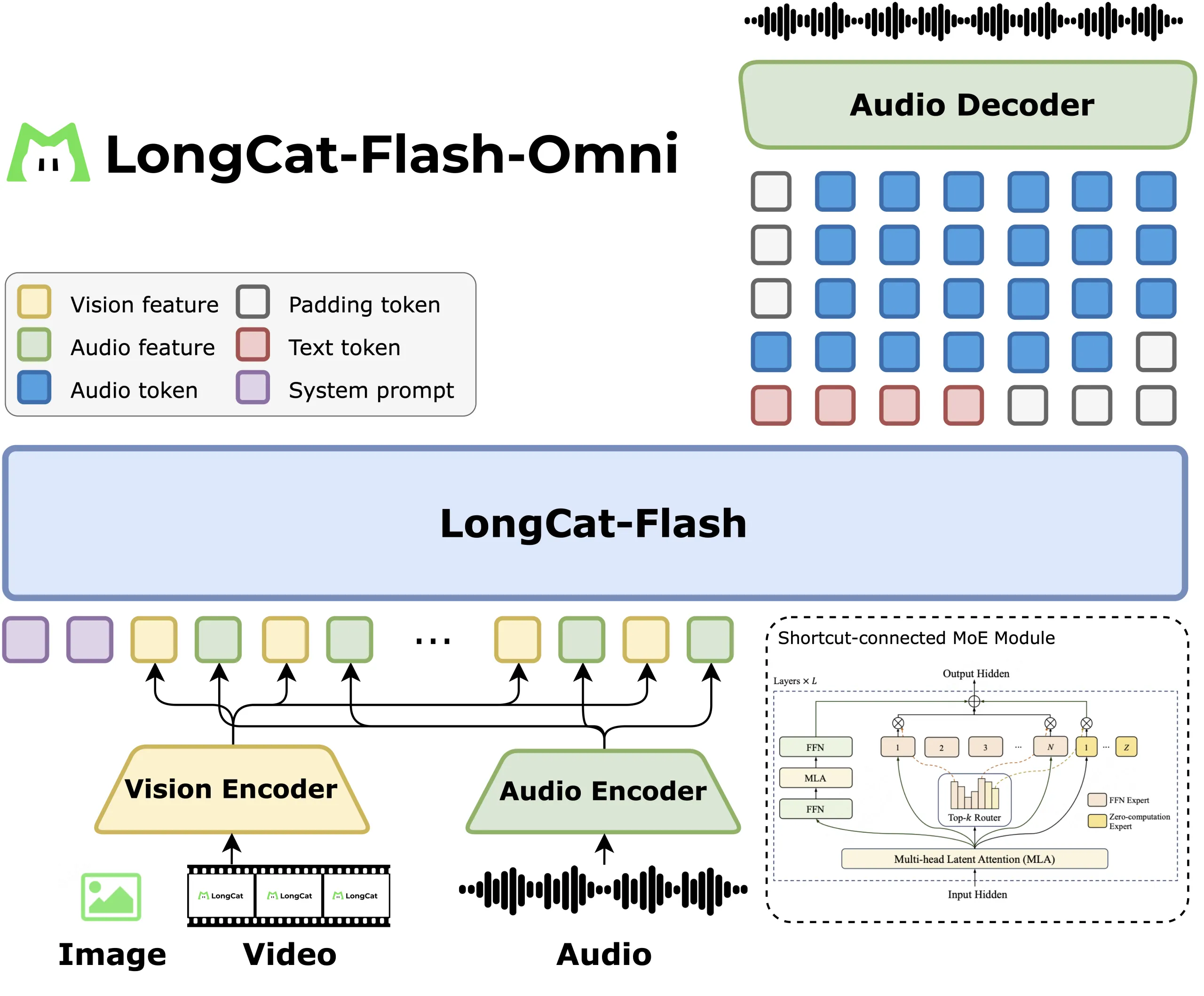
LongCat Flash Omni is built on a shortcut-connected Mixture of Experts (MoE) design, featuring 560 billion parameters with approximately 27 billion active per token. This model excels at processing text, images, video, and audio, maintaining a 128K context to support long conversations and document-level understanding in one stack.
Architecture and Modal Attachments
The architecture keeps the language model intact while integrating perception modules. A LongCat ViT encoder is utilized for processing both images and video frames, eliminating the need for a separate video processing tower. An audio encoder, paired with the LongCat Audio Codec, converts speech into discrete tokens, enabling real-time audio-visual interaction.
Streaming and Feature Interleaving
The team employs chunk-wise audio-visual feature interleaving, packing audio features, video features, and timestamps into 1-second segments. Video is typically sampled at 2 frames per second, adjusted according to video length, allowing for low latency while preserving spatial context for GUI, OCR, and video question-answering tasks.
Training Curriculum
The training follows a staged curriculum:
- Initial training of the LongCat Flash text backbone, activating 18.6B to 31.3B parameters per token (average 27B).
- Text-to-speech continued pretraining.
- Multimodal continued pretraining with image and video.
- Context extension to 128K.
- Audio encoder alignment.
Systems Design and Modality Decoupled Parallelism
Meituan employs modality decoupled parallelism, where vision and audio encoders operate with hybrid sharding and activation recomputation. The LLM utilizes pipeline, context, and expert parallelism, while a ModalityBridge aligns embeddings and gradients. The team reports that multimodal supervised fine-tuning maintains over 90% of the throughput of text-only training.
Benchmarks and Positioning
LongCat Flash Omni achieves a score of 61.4 on OmniBench, surpassing Qwen 3 Omni Instruct at 58.5 but falling short of Gemini 2.5 Pro at 66.8. On VideoMME, it scores 78.2, comparable to GPT 4o and Gemini 2.5 Flash, while reaching 88.7 on VoiceBench, slightly exceeding GPT 4o Audio.
Key Takeaways
LongCat Flash Omni is an open-source omni-modal model leveraging Meituan’s 560B MoE backbone, activating approximately 27B parameters per token. It integrates unified vision and video encoding with a streaming audio path, using a 2 fps default video sampling with duration-conditioned adjustments. This design enables real-time interactions without compromising performance.
With over 90% of text-only throughput maintained in multimodal supervised fine-tuning, Meituan’s approach to practical omni-modal interaction is evident.
Additional Resources
Explore the following resources for further information:
- Paper, Model Weights, and GitHub Repo
- Tutorials, Codes, and Notebooks
- Follow us on Twitter
- Join our 100k+ ML SubReddit
- Subscribe to our Newsletter
- Join us on Telegram