Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100
Understanding the Target Audience
The target audience for Andrej Karpathy’s release of nanochat primarily includes:
- AI Researchers and Developers: Professionals interested in natural language processing and machine learning. They often seek ways to train and fine-tune language models efficiently.
- Business Analysts: Individuals who are motivated to leverage AI for data analysis and decision-making processes.
- Startups and Entrepreneurs: These users aim to implement AI solutions with limited resources, looking for cost-effective tools to enhance their offerings.
- Technical Enthusiasts and Hobbyists: Individuals eager to learn and experiment with cutting-edge technology in the AI space.
Their pain points include:
- High costs and complexity associated with training large language models.
- Need for reproducible and scalable AI solutions that can be adapted to specific business needs.
- Desire for streamlined workflows that reduce setup time and resource requirements.
Goals and interests encompass:
- Building and fine-tuning AI models with minimal investment.
- Accessing straightforward documentation and resources to aid in implementation.
- Exploring innovative applications of AI in various business sectors.
Communication preferences lean toward:
- Clear, technical documentation that provides actionable insights.
- Access to community discussions and peer support.
- Updates on new features or improvements in a concise format.
Overview of nanochat
Andrej Karpathy has open-sourced nanochat, a compact, dependency-light codebase implementing a full ChatGPT-style stack—from tokenizer training to web UI inference—focused on reproducible and hackable large language model (LLM) training on a single multi-GPU node.
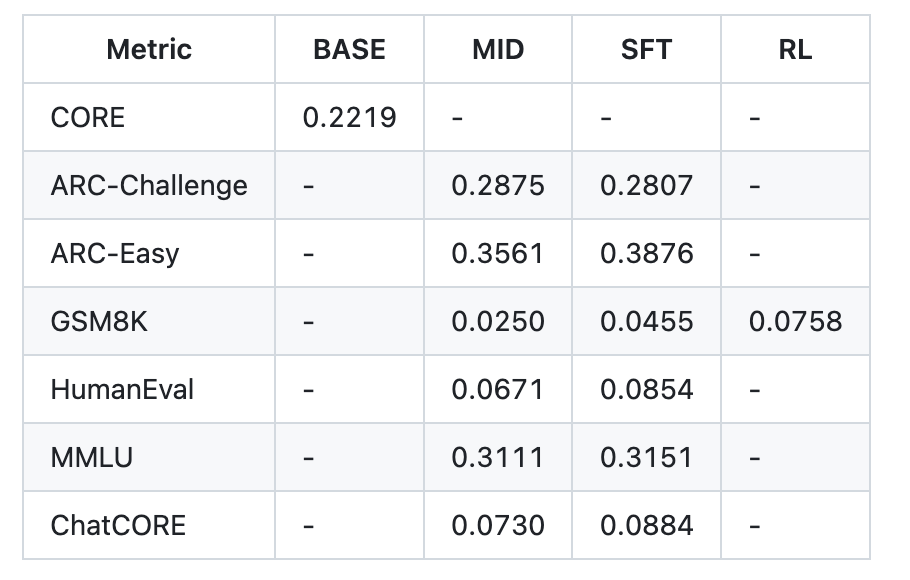
The repository offers a single-script “speedrun” that executes the full loop: tokenization, base pretraining, mid-training on chat/multiple-choice/tool-use data, supervised fine-tuning (SFT), optional reinforcement learning (RL) on GSM8K, evaluation, and serving (CLI + ChatGPT-like web UI). The recommended setup uses an 8×H100 node; at approximately $24/hour, the 4-hour speedrun totals around $100. A post-run report.md summarizes metrics (CORE, ARC-E/C, MMLU, GSM8K, HumanEval, ChatCORE).
Technical Highlights
The tokenizer employs a custom Rust byte pair encoding (BPE), featuring a vocabulary size of 65,536 tokens. Training utilizes FineWeb-EDU shards, re-packaged for easy access. The evaluation bundle includes CORE (22 autocompletion datasets like HellaSwag, ARC, and BoolQ), stored in ~/.cache/nanochat/eval_bundle.
The speedrun configuration trains a depth-20 Transformer with approximately 560 million parameters, consistent with Chinchilla-style scaling (params × ~20 tokens). This model is estimated to have a training capability of approximately 4e19 FLOPs. Training employs Muon for matrix multiplication parameters and AdamW for embeddings/unembeddings, reporting loss in bits-per-byte (bpb) to ensure tokenizer invariance.
Mid-training, SFT, and Tool Use
Post-pretraining, mid-training adapts the base model for conversations (SmolTalk) and instructs multiple-choice behavior using 100,000 MMLU auxiliary-train questions. Tool use is incorporated within the training process through specific code blocks. The default mixture includes:
- SmolTalk: 460,000 rows
- MMLU auxiliary-training: 100,000 rows
- GSM8K main: 8,000 rows
The SFT process fine-tunes the model on higher-quality conversations while ensuring test-time formatting aligns with training to minimize mismatch. Example metrics from the speedrun tier following SFT include:
- ARC-Easy: 0.3876
- ARC-Challenge: 0.2807
- MMLU: 0.3151
- GSM8K: 0.0455
- HumanEval: 0.0854
- ChatCORE: 0.0884
Tool use is integrated end-to-end, with a custom engine implementing key functionalities such as KV cache, prefill/decode inference, and a Python interpreter sandbox for enhanced tool-augmented training and evaluation.
Optional Reinforcement Learning on GSM8K
The final stage allows for optional RL on GSM8K, utilizing a simplified Generalized Relative Policy Optimization (GRPO) loop. The walkthrough clarifies omitted components compared to standard Proximal Policy Optimization (PPO) methods, focusing on maintaining a practical approach to reinforcement learning.
Cost and Quality Scaling
The README outlines additional scaling options beyond the ~$100 speedrun:
- ~$300 tier: d=26 (~12 hours), slightly surpassing GPT-2 CORE; requires additional pretraining shards and batch-size adjustments.
- ~$1,000 tier: ~41.6 hours, yielding significantly improved coherence and basic reasoning/coding ability.
Prior experimental runs suggested that a d=30 model trained for ~24 hours could achieve scores of 40s on MMLU, 70s on ARC-Easy, and 20s on GSM8K.
Evaluation Snapshot
An example report.md for the ~$100/≈4-hour run shows:
- CORE: 0.2219 (base)
- ARC-Easy: 0.3876
- ARC-Challenge: 0.2807
- MMLU: 0.3151
- GSM8K: 0.0455
- HumanEval: 0.0854
Conclusion
Karpathy’s nanochat strikes a balance between accessibility and functionality. It offers a single, clean, dependency-light repository integrating tokenizer training, pretraining, mid-training, SFT, and an optional simplified RL process, resulting in a reproducible speedrun capable of producing detailed evaluation metrics.
For further details, check out the official repository and community discussions on GitHub.