
Hypothesis validation is fundamental in scientific discovery, decision-making, and information acquisition. Whether in biology, economics, or policymaking, researchers rely on testing hypotheses to guide their conclusions. Traditionally, this process involves designing experiments, collecting data, and analyzing results to determine the validity of a hypothesis. However, the volume of generated hypotheses has increased dramatically with the advent of LLMs. While these AI-driven hypotheses offer novel insights, their plausibility varies widely, making manual validation impractical. Thus, automation in hypothesis validation has become an essential challenge in ensuring that only scientifically rigorous hypotheses guide future research.
The main challenge in hypothesis validation is that many real-world hypotheses are abstract and not directly measurable. For instance, stating that a specific gene causes a disease is too broad and needs to be translated into testable implications. The rise of LLMs has exacerbated this issue, as these models generate hypotheses at an unprecedented scale, many of which may be inaccurate or misleading. Existing validation methods struggle to keep pace, making it difficult to determine which hypotheses are worth further investigation. Also, statistical rigor is often compromised, leading to false verifications that can misdirect research and policy efforts.
Traditional methods of hypothesis validation include statistical testing frameworks such as p-value-based hypothesis testing and Fisher’s combined test. However, these approaches rely on human intervention to design falsification experiments and interpret results. Some automated approaches exist, but they often lack mechanisms for controlling Type-I errors (false positives) and ensuring that conclusions are statistically reliable. Many AI-driven validation tools do not systematically challenge hypotheses through rigorous falsification, increasing the risk of misleading findings. As a result, a scalable and statistically sound solution is needed to automate the hypothesis validation process effectively.
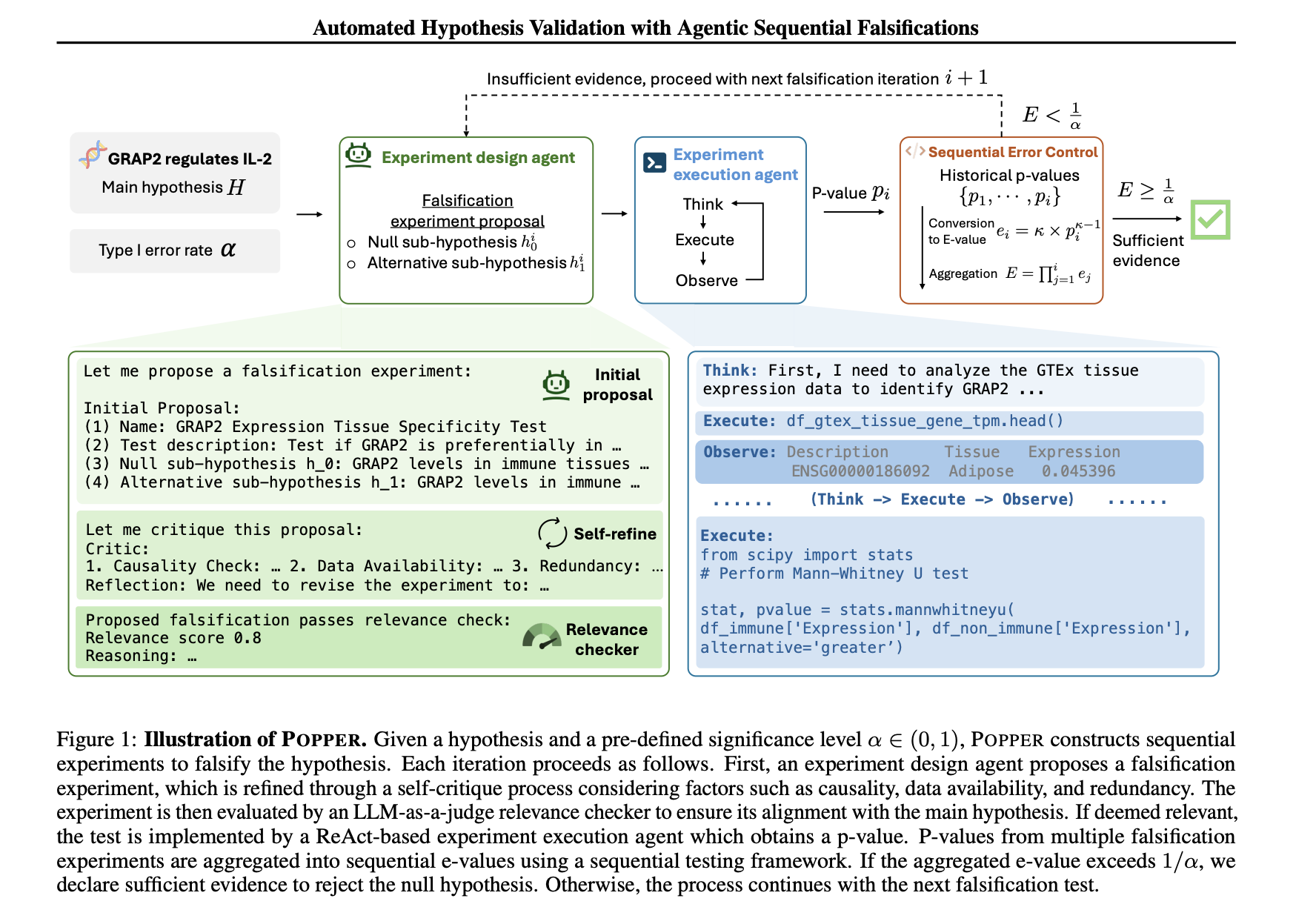
Researchers from Stanford University and Harvard University introduced POPPER, an agentic framework that automates the process of hypothesis validation by integrating rigorous statistical principles with LLM-based agents. The framework systematically applies Karl Popper’s principle of falsification, which emphasizes disproving rather than proving hypotheses. POPPER employs two specialized AI-driven agents:
- The Experiment Design Agent which formulates falsification experiments
- The Experiment Execution Agent which implements them
Each hypothesis is divided into specific, testable sub-hypotheses and subjected to falsification experiments. POPPER ensures that only well-supported hypotheses are advanced by continuously refining the validation process and aggregating evidence. Unlike traditional methods, POPPER dynamically adapts its approach based on prior results, significantly improving efficiency while maintaining statistical integrity.
POPPER functions through an iterative process in which falsification experiments sequentially test hypotheses. The Experiment Design Agent generates these experiments by identifying the measurable implications of a given hypothesis. The Experiment Execution Agent then carries out the proposed experiments using statistical methods, simulations, and real-world data collection. Key to POPPER’s methodology is its ability to strictly control Type-I error rates, ensuring that false positives are minimized. Unlike conventional approaches that treat p-values in isolation, POPPER introduces a sequential testing framework in which individual p-values are converted into e-values, a statistical measure allowing continuous evidence accumulation while maintaining error control. This adaptive approach enables the system to refine its hypotheses dynamically, reducing the chances of reaching incorrect conclusions. The framework’s flexibility allows it to work with existing datasets, conduct new simulations, or interact with live data sources, making it highly versatile across disciplines.
POPPER was evaluated across six domains: biology, sociology, and economics. The system was tested against 86 validated hypotheses, with results showing Type-I error rates below 0.10 across all datasets. POPPER demonstrated significant improvements in statistical power compared to existing validation methods, outperforming standard techniques such as Fisher’s combined test and likelihood ratio models. In one study focusing on biological hypotheses related to Interleukin-2 (IL-2), POPPER’s iterative testing mechanism improved validation power by 3.17 times compared to alternative methods. Also, an expert evaluation involving nine PhD-level computational biologists and biostatisticians found that POPPER’s hypothesis validation accuracy was comparable to that of human researchers but was completed in one-tenth the time. By leveraging its adaptive testing framework, POPPER reduced the time required for complex hypothesis validation by 10, making it significantly more scalable and efficient.
Several Key Takeaways from the Research include:
- POPPER provides a scalable, AI-driven solution that automates the falsification of hypotheses, reducing manual workload and improving efficiency.
- The framework maintains strict Type-I error control, ensuring that false positives remain below 0.10, critical for scientific integrity.
- Compared to human researchers, POPPER completes hypothesis validation 10 times faster, significantly improving the speed of scientific discovery.
- Unlike traditional p-value testing, using e-values allows accumulating experimental evidence while dynamically refining hypothesis validation.
- Tested across six scientific fields, including biology, sociology, and economics, demonstrating broad applicability.
- Evaluated by nine PhD-level scientists, POPPER’s accuracy matched human performance while dramatically reducing time spent on validation.
- Improved statistical power by 3.17 times over traditional hypothesis validation methods, ensuring more reliable conclusions.
- POPPER integrates Large Language Models to dynamically generate and refine falsification experiments, making it adaptable to evolving research needs.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
The post Stanford Researchers Developed POPPER: An Agentic AI Framework that Automates Hypothesis Validation with Rigorous Statistical Control, Reducing Errors and Accelerating Scientific Discovery by 10x appeared first on MarkTechPost.