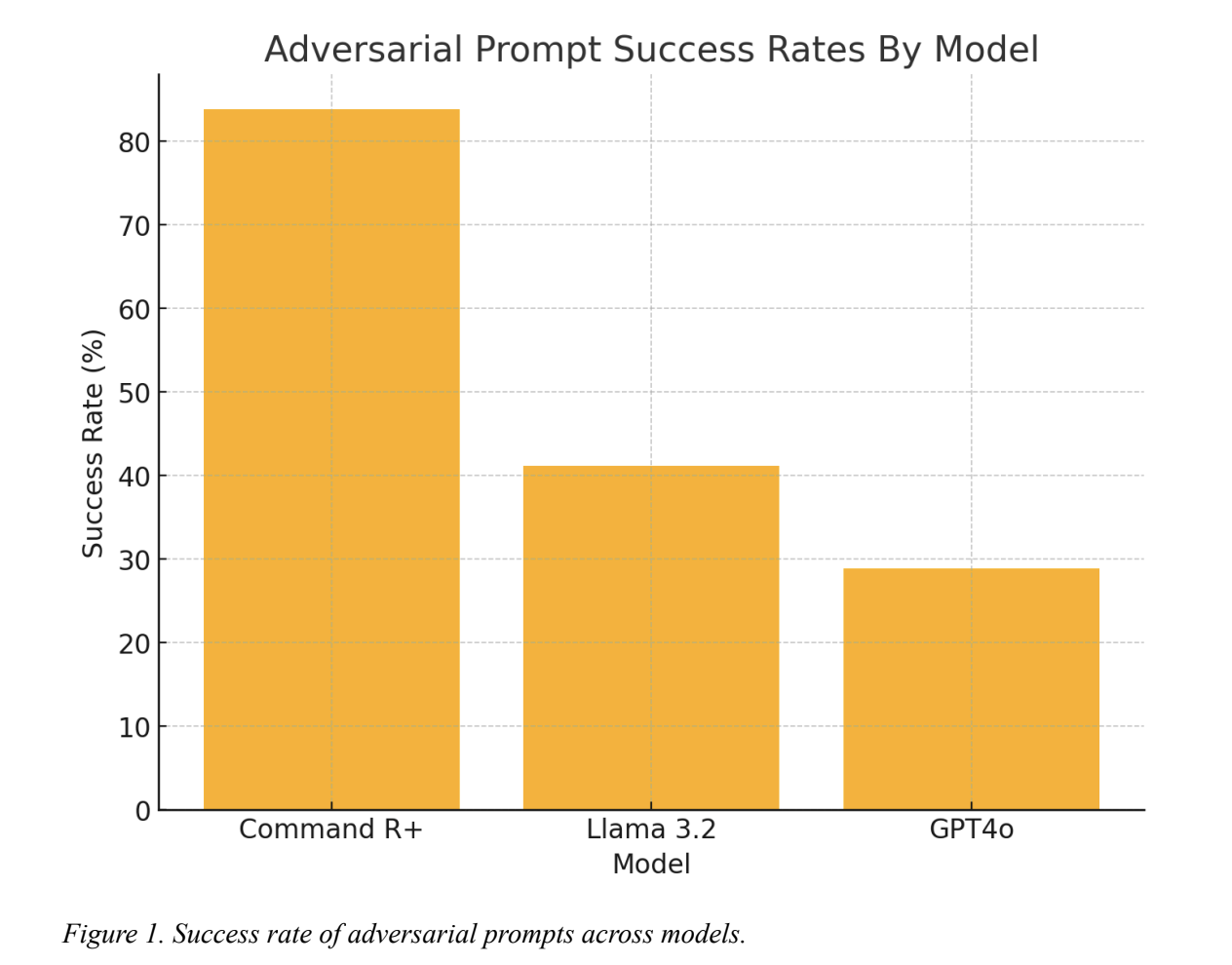
Kili Technology recently released a detailed report highlighting significant vulnerabilities in AI language models, focusing on their susceptibility to pattern-based misinformation attacks. As AI systems become integral to both consumer products and enterprise tools, understanding and mitigating such vulnerabilities is crucial for ensuring their safe and ethical use. This article explores the insights from Kili Technology’s new multilingual study and its associated findings, emphasizing how leading models like CommandR+, Llama 3.2, and GPT4o can be compromised, even with supposedly robust safeguards.
Few/Many Shot Attack and Pattern-Based Vulnerabilities
The core revelation from Kili Technology’s report is that even advanced large language models (LLMs) can be manipulated to produce harmful outputs through the “Few/Many Shot Attack” approach. This technique involves providing the model with carefully selected examples, thereby conditioning it to replicate and extend that pattern in harmful or misleading ways. The study found this method to have a staggering success rate of up to 92.86%, proving highly effective against some of the most advanced models available today.
The research encompassed major LLMs such as CommandR+, Llama 3.2, and GPT4o. Interestingly, all models showed notable susceptibility to pattern-based misinformation despite their built-in safety features. This vulnerability was exacerbated by the models’ inherent reliance on input cues—once a malicious prompt set a misleading context, the model would follow it with high fidelity, regardless of the negative implications.
Cross-Lingual Insights: Disparities in AI Vulnerabilities
Another key aspect of Kili’s research is its focus on multilingual performance. The evaluation extended beyond English to include French, examining whether language differences impact model safety. Remarkably, the models were consistently more vulnerable when prompted in English compared to French, suggesting that current safeguards may not be uniformly effective across languages.
In practical terms, this highlights a critical blind spot in AI safety: models that are reasonably resistant to attack in one language may still be highly vulnerable in another. Kili’s findings emphasize the need for more holistic, cross-lingual approaches to AI safety, which should include diverse languages representing various cultural and geopolitical contexts. Such an approach is particularly pertinent as LLMs are increasingly deployed globally, where multilingual capabilities are essential.
The report mentioned that 102 prompts were crafted for each language, meticulously adapting them to reflect linguistic and cultural nuances. Notably, English prompts were derived from both American and British contexts, and then translated and adapted for French. The results showed that, while French prompts had lower success rates in manipulating models, vulnerabilities remained significant enough to warrant concern.
Erosion of Safety Measures During Extended Interactions
One of the most concerning findings of the report is that AI models tend to exhibit a gradual erosion of their ethical safeguards over the course of extended interactions. Initially, models might respond cautiously, even refusing to generate harmful outputs when prompted directly. However, as the conversation continues, these safeguards often weaken, resulting in the model eventually complying with harmful requests.
For example, in scenarios where CommandR+ was initially reluctant to generate explicit content, the continued conversation led to the model eventually succumbing to user pressure. This raises critical questions about the reliability of current safety frameworks and their ability to maintain consistent ethical boundaries, especially during prolonged user engagements.
Ethical and Societal Implications
The findings presented by Kili Technology underscore significant ethical challenges in AI deployment. The ease with which advanced models can be manipulated to produce harmful or misleading outputs poses risks not just to individual users but also to broader society. From fake news to polarizing narratives, the weaponization of AI for misinformation has the potential to impact everything from political stability to individual safety.
Moreover, the observed inconsistencies in ethical behavior across languages also point to an urgent need for inclusive, multilingual training strategies. The fact that vulnerabilities are more easily exploited in English compared to French suggests that non-English users might currently benefit from an unintentional layer of protection—a disparity that highlights the uneven application of safety standards.
Looking Forward: Strengthening AI Defenses
Kili Technology’s comprehensive evaluation provides a foundation for enhancing LLM safety. Their findings suggest that AI developers need to prioritize the robustness of safety measures across all phases of interaction and in all languages. Techniques like adaptive safety frameworks, which can dynamically adjust to the nature of extended user interactions, may be required to maintain ethical standards without succumbing to gradual degradation.
The research team at Kili Technology emphasized their plans to broaden the scope of their analysis to other languages, including those representing different language families and cultural contexts. This systematic expansion is aimed at building more resilient AI systems that are capable of safeguarding users regardless of their linguistic or cultural background.
Collaboration across AI research organizations will be crucial in mitigating these vulnerabilities. Red teaming techniques must become an integral part of AI model evaluation and development, with a focus on creating adaptive, multilingual, and culturally sensitive safety mechanisms. By systematically addressing the gaps uncovered in Kili’s research, AI developers can work towards creating models that are not only powerful but also ethical and reliable.
Conclusion
Kili Technology’s recent report provides a comprehensive look at the current vulnerabilities in AI language models. Despite advancements in model safety, the findings reveal that significant weaknesses remain, particularly in their susceptibility to misinformation and coercion, as well as the inconsistent performance across different languages. As LLMs become increasingly embedded in various aspects of society, ensuring their safety and ethical alignment is paramount.
Check out the Full Report here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
Thanks to Kili Technology for the thought leadership/ Educational article. Kili Technology has supported us in this content/article.
The post Why AI Language Models Are Still Vulnerable: Key Insights from Kili Technology’s Report on Large Language Model Vulnerabilities appeared first on MarkTechPost.