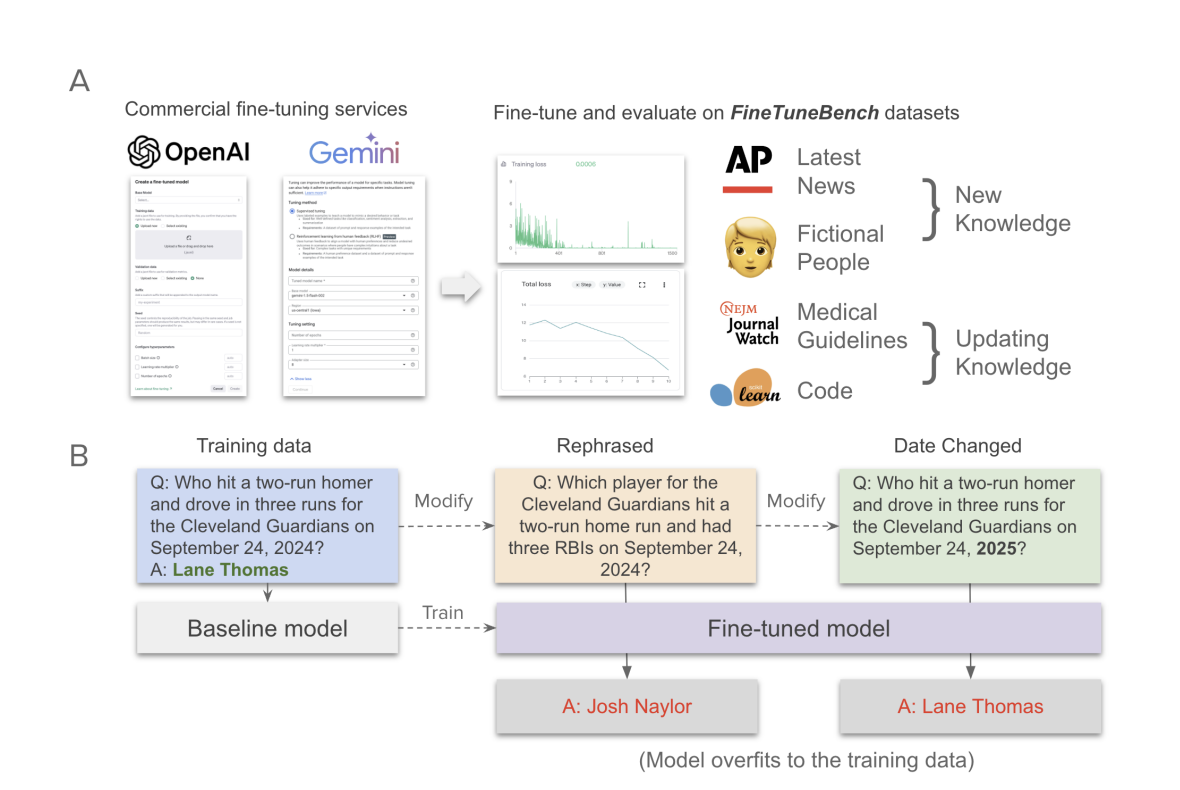
The demand for fine-tuning LLMs to incorporate new information and refresh existing knowledge is growing. While companies like OpenAI and Google offer fine-tuning APIs that allow LLM customization, their effectiveness for knowledge updating remains to be determined. LLMs used in fields like software and medicine need current, domain-specific information—software developers need models updated with the latest code, while healthcare requires adherence to recent guidelines. Although fine-tuning services offer a way to adapt proprietary, closed-source models, they lack transparency regarding methods, and limited hyperparameter options may restrict knowledge infusion. No standardized benchmarks exist to evaluate these fine-tuning capabilities.
Current methods to alter LLM behavior include SFT, RLHF, and continued pre-training. However, the effectiveness of these approaches for knowledge infusion is still being determined. Retrieval-augmented generation (RAG) introduces knowledge in prompts, though models often ignore conflicting information, causing inaccuracies. Past research has explored knowledge injection in open-source LLMs using adapters or shallow layer fine-tuning, but more understanding is needed around fine-tuning larger commercial models. Prior studies have fine-tuned models for classification and summarization, yet this work uniquely focuses on knowledge infusion and compares multiple fine-tuning APIs on a shared dataset.
Stanford University researchers have developed FineTuneBench, a comprehensive framework and dataset to evaluate how effectively commercial fine-tuning APIs allow LLMs to incorporate new and updated knowledge. Testing five advanced LLMs, including GPT-4o and Gemini 1.5 Pro, in two scenarios—introducing new information (e.g., recent news) and updating existing knowledge (e.g., medical guidelines)—the study found limited success across models. The models averaged only 37% accuracy for learning new information and 19% for updating knowledge. Among them, GPT-4o mini performed best, while Gemini models showed minimal capacity for knowledge updates, underscoring limitations in current fine-tuning services for reliable knowledge adaptation.
To evaluate how well fine-tuning can enable models to learn new information, researchers created two unique datasets: a Latest News Dataset and a Fictional People Dataset, ensuring none of the data existed in the models’ training sets. The Latest News Dataset, generated from September 2024 Associated Press articles, was crafted into 277 question-answer pairs, which were further rephrased to test model robustness. The Fictional People Dataset included profile facts about fictional characters, producing direct and derived questions for knowledge testing. Models were trained on both datasets using various methods, such as masking answers in the prompt. Different configurations and epochs were explored to optimize performance.
Fine-tuning OpenAI models shows high memorization but limited generalization for new knowledge tasks. While models like GPT-4o-mini excel in recalling trained QA pairs, they struggle with rephrased questions, especially in the Fictional People dataset, where responses to secondary or comparative questions remain weak. Updating knowledge is harder, notably in coding tasks, due to challenges in altering pre-existing information. Gemini models underperform across tasks and need help memorizing or generalizing effectively. Training methods like word masking and prompt completions also fail to enhance generalization, suggesting that standard training paradigms may not adequately improve adaptability.
The study presents FineTuneBench, a dataset collection testing fine-tuned LLMs’ capacity to acquire knowledge in the news, fictional people, medical guidelines, and code libraries. Despite fine-tuning, models showed limited knowledge adaptation, with GPT-4o-mini outperforming others and Gemini underperforming. Relying on LLM fine-tuning remains challenging, as current methods and parameters from OpenAI and Google are limited. RAG approaches are also suboptimal due to cost and scaling issues. Limitations include testing only two LLM providers and using mostly default fine-tuning parameters. Future work will explore how question complexity impacts model generalization.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post FineTuneBench: Evaluating LLMs’ Ability to Incorporate and Update Knowledge through Fine-Tuning appeared first on MarkTechPost.