
In the world of massive-scale cloud infrastructure, even the slightest dip in performance can lead to significant inefficiencies. Imagine a change that causes an application to become 0.05% slower—a number that seems insignificant at first glance. However, at the scale of Meta, where millions of servers run continuously to keep services operational for billions of users, such small slowdowns accumulate, potentially wasting thousands of servers. Addressing performance regressions at this minuscule level is an enormous challenge due to the “noise” introduced by hardware variability, transient issues, and the sheer scale of operations. Most simple detection techniques end up with an overwhelming number of false positives, as transitory events—rather than code changes—often appear as performance regressions.
Meta AI Introduces FBDetect System: An In-Production Performance Regression Detection System

To tackle these challenges, Meta AI has introduced FBDetect, an in-production performance regression detection system capable of identifying even the smallest regressions, down to 0.005%. FBDetect is designed to monitor around 800,000 time series covering diverse metrics, such as throughput, latency, CPU, and memory usage, across hundreds of services operating on millions of servers. It uses innovative techniques, such as fleet-wide stack-trace sampling, to capture fine-grained subroutine-level performance differences. By analyzing these granular traces, FBDetect can effectively filter out false positives and pinpoint actual regressions, ensuring efficient root-cause analysis for performance slowdowns caused by code or configuration changes.
The system’s primary focus is on capturing and analyzing performance at the subroutine level instead of examining the entire application. By honing in on individual subroutines—where even a small change might represent a more significant relative impact—FBDetect shifts the detection problem from the extremely challenging 0.05% application-level regressions to more discernible 5% changes at the subroutine level. This focus significantly reduces the noise and makes tracing changes much more practical.
Technical Details and Benefits of FBDetect
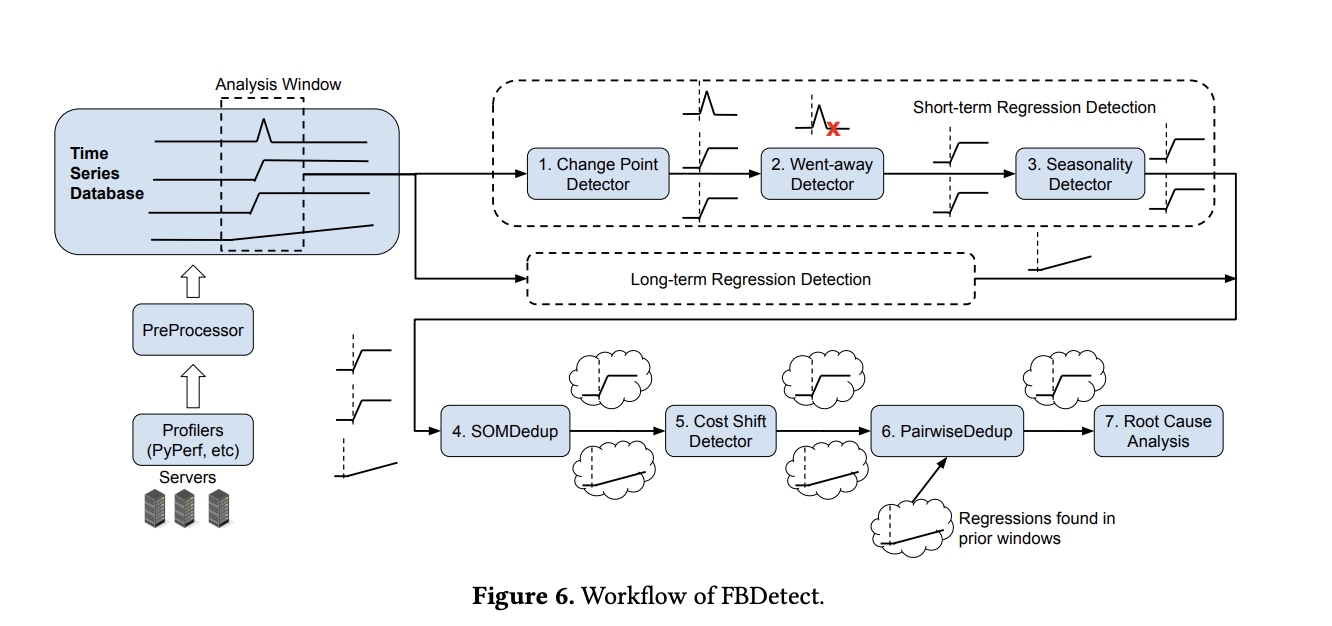
FBDetect employs three core technical approaches to address performance regressions at Meta’s hyperscale. First, it performs subroutine-level regression detection to minimize the variance in performance data, allowing for the detection of regressions at much smaller levels than would be feasible with service-wide metrics. By measuring metrics at this level, even tiny regressions that might otherwise go unnoticed become detectable. Second, stack-trace sampling is conducted across the fleet to measure where time is being spent at the subroutine level, akin to performance profiling but at an unprecedented scale. This enables the team to identify precisely which subroutine is impacted and how. Lastly, for each detected regression, root cause analysis is conducted to determine whether a regression is due to transient issues, cost shifts, or actual code changes. By analyzing the stack traces associated with regressions and comparing them to recent code commits, FBDetect can automatically identify which change caused the slowdown.
One of the key strengths of FBDetect is its robustness. It has been battle-tested over seven years in production environments and is capable of reliably filtering out deceptive false-positive regressions. By doing so, FBDetect significantly reduces the number of incidents that developers need to investigate, allowing them to focus on meaningful changes rather than sifting through countless false alarms. This system has a direct impact on Meta’s infrastructure efficiency: without FBDetect, even a small number of unnoticed regressions could waste millions of servers every year.
Why FBDetect is Important and Its Impact on Meta’s Infrastructure
The importance of detecting these tiny performance regressions cannot be overstated in hyperscale environments. Meta’s server fleet encompasses millions of servers that support hundreds of services used by billions of users. In such an environment, even minor regressions—such as those leading to a 0.005% increase in CPU usage—can have a profound impact. According to the paper, FBDetect has helped avoid wasting approximately 4,000 servers per year by catching such tiny regressions. The median CPU regression detected was as low as 0.048%, a level at which most performance analysis systems would falter.
The system achieves this accuracy by monitoring 800,000 time series, including CPU, memory, latency, and other key metrics. False positives are a significant challenge in such noisy, dynamic environments. FBDetect addresses this by using a combination of change-point detection, trend analysis, and clustering techniques to identify genuine regressions and distinguish them from transient issues. Techniques like Symbolic Aggregate approXimation (SAX) are used to help identify whether the observed anomaly is a one-time glitch or an actual regression, adding an extra layer of reliability. Beyond detecting regressions, FBDetect provides effective root cause analysis by combining code analysis, time-series correlation, and stack-trace investigation—greatly improving developers’ ability to address detected issues promptly and effectively.
Conclusion
Performance really matters at hyperscale. Even seemingly inconsequential performance slowdowns can cascade into enormous costs and inefficiencies. FBDetect represents a significant step forward in addressing these challenges. Its ability to detect subroutine-level regressions as small as 0.005% is a testament to the advanced methodologies Meta employs to optimize its massive infrastructure. By implementing a robust, in-production regression detection system that continuously learns and adapts, Meta is not only saving millions of servers but also setting a new benchmark for performance monitoring at scale. As more companies operate at hyperscale, similar detection systems will become crucial in maintaining efficiency and scalability in the cloud.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post Meta AI Introduces FBDetect: A Performance Regression Detection System at Hyperscale Operations in-Production Monitoring appeared first on MarkTechPost.