
Contrastive image and text models face significant challenges in optimizing retrieval accuracy despite their crucial role in large-scale text-to-image and image-to-text retrieval systems. While these models effectively learn joint embeddings through contrastive loss functions to align matching text-image pairs and separate non-matching pairs, they primarily optimize pretraining objectives like InfoNCE rather than downstream retrieval performance. This fundamental limitation leads to suboptimal embeddings for practical retrieval tasks. Current methodologies struggle with issues like the hubness problem, where certain retrieval candidates dominate as nearest neighbors for multiple queries in high-dimensional embedding spaces, resulting in incorrect matches. Also, existing solutions often require substantial computational resources, additional training across domains, or external database integration, making them impractical for limited-compute environments or black-box embedding models.
Researchers from Massachusetts Institute of Technology and Stanford University present Nearest Neighbor Normalization (NNN), which emerges as a robust training-free approach to enhance contrastive retrieval performance. This innovative method addresses the limitations of previous approaches by introducing a computationally efficient solution with sublinear time complexity relative to reference database size. At its core, NNN implements a correction mechanism that targets embeddings receiving disproportionate retrieval scores by normalizing candidate scores using only the k nearest query embeddings from a reference dataset. This targeted approach not only surpasses the performance of existing methods like QBNorm and DBNorm but also maintains minimal inference overhead. The method demonstrates remarkable versatility by consistently improving retrieval accuracy across various models and datasets while simultaneously reducing harmful biases, such as gender bias, making it a significant advancement in contrastive retrieval systems.
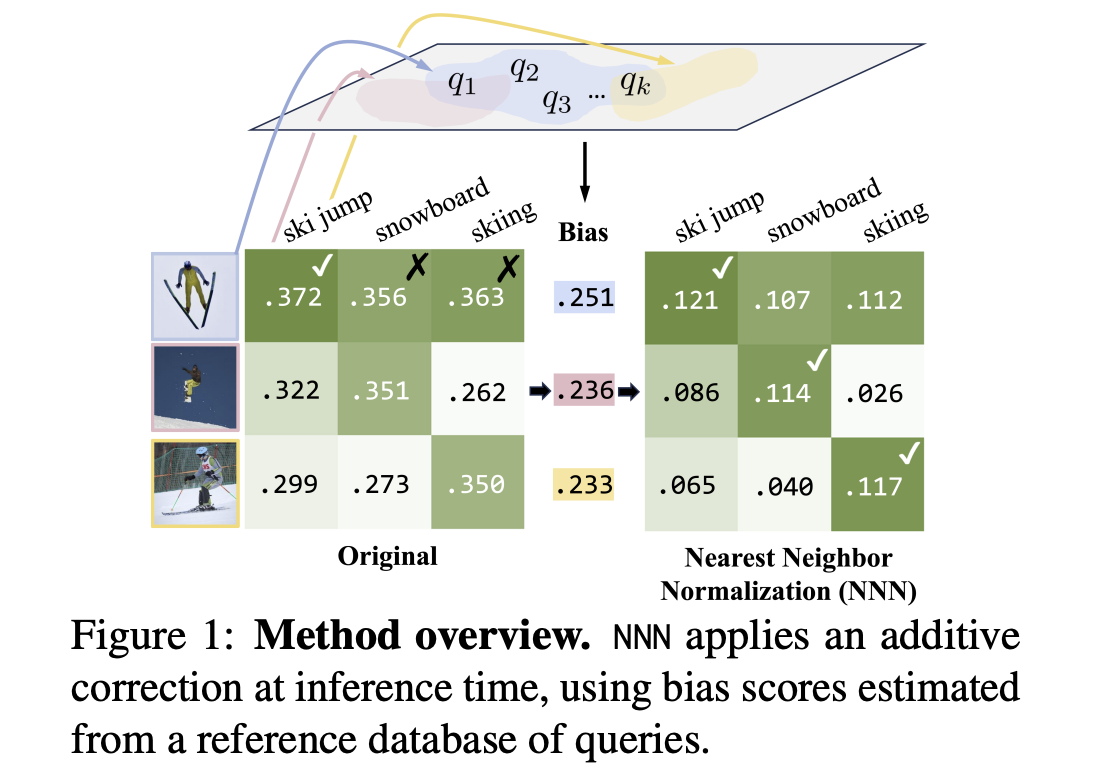
The Nearest Neighbor Normalization method introduces a sophisticated approach to address the hubness problem in contrastive text-to-image retrieval systems. The method calculates a match score s(q, r) between a query q and database retrieval candidate r using cosine similarity between image and text embeddings. To counteract bias towards hub images that show high cosine similarity with multiple query captions, The NNN method implements a bias correction mechanism. This bias b(r) for each retrieval candidate is computed as α times the mean of the k highest similarity scores from a reference query dataset D. The final debiased retrieval score is obtained by subtracting this estimated bias from the original score: sD(q, r) = s(q, r) – b(r). The method’s efficiency stems from its ability to compute bias scores offline and cache them while maintaining sublinear time complexity during retrieval operations through vector retrieval techniques.
The evaluation of NNN demonstrates impressive performance improvements across multiple contrastive multimodal models including CLIP, BLIP, ALBEF, SigLIP, and BEiT. The method shows consistent gains in both text-to-image and image-to-text retrieval tasks, outperforming existing approaches while requiring significantly less computational resources. In addition, while DBNorm’s hyperparameter optimization demands 100 times more compute, NNN achieves superior results with minimal computational overhead. The method’s robustness is evident through its consistent performance with both in-distribution and out-of-distribution queries, maintaining effectiveness even with varying sizes of reference databases. In addressing gender bias, NNN significantly reduced bias in occupation-related image retrieval from 0.348 to 0.072 (n=6) and from 0.270 to 0.078 (n=10), while simultaneously improving average precision from 56.5% to 69.6% for Retrieval@1 and from 49.6% to 56.5% for Retrieval@5, demonstrating its capability to enhance both fairness and accuracy.
Nearest Neighbor Normalization represents a significant advancement in contrastive multimodal retrieval systems. The method’s innovative approach of using k-nearest neighbors for bias correction scores demonstrates superior efficiency while maintaining improved accuracy compared to existing test-time inference methods. NNN’s versatility is evident in its successful application with various reference datasets and its effectiveness in reducing gender bias, marking it as a practical and powerful solution for enhancing multimodal retrieval systems.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Nearest Neighbor Normalization: A Sublinear Approach to Improving Contrastive Retrieval appeared first on MarkTechPost.