Recurrent Neural Networks were the trailblazers in natural language processing and set the cornerstone for future advances. RNNs were simple in structure with their contextual memory and constant state size, which promised the capacity to handle long sequence tasks. While theoretically, the design of RNNS pledged to a great future in long context tasks, practically, the results were far from satisfactory. As the context length of RNNs increased, the performance dropped dramatically. Even when we examine the latest SOTA RNN-based language models such as Mamba-1, the performance was poor when the context length exceeded their training tokens, which in most of the cases could not reach even 10,000Despite the linear growth in computation with training, RNNs are incapable of generalizing along the sequence length. Soon enough, transformers and attention-based models came into the picture, and their advanced variations filled this vacuum. Recent transformer-based language models demonstrated impressive capabilities in reasoning over long sequences with thousands and even millions of tokens. Although these models relied upon quadratically scaling attention mechanisms, they became the priority given their superior performance. This article discusses the latest research that examines how RNNs reached this fate. We first diagnose why RNNs outpaced this race and further discuss treatment strategies.
Researchers at Tsinghua University presented their paper to examine RNN-based language models and the significant problems that lead to them falling behind; they then formalized the issues and introduced the concept of State Collapse. Additionally, they propose mitigation methods to improve the length of generalizability of RNNs.
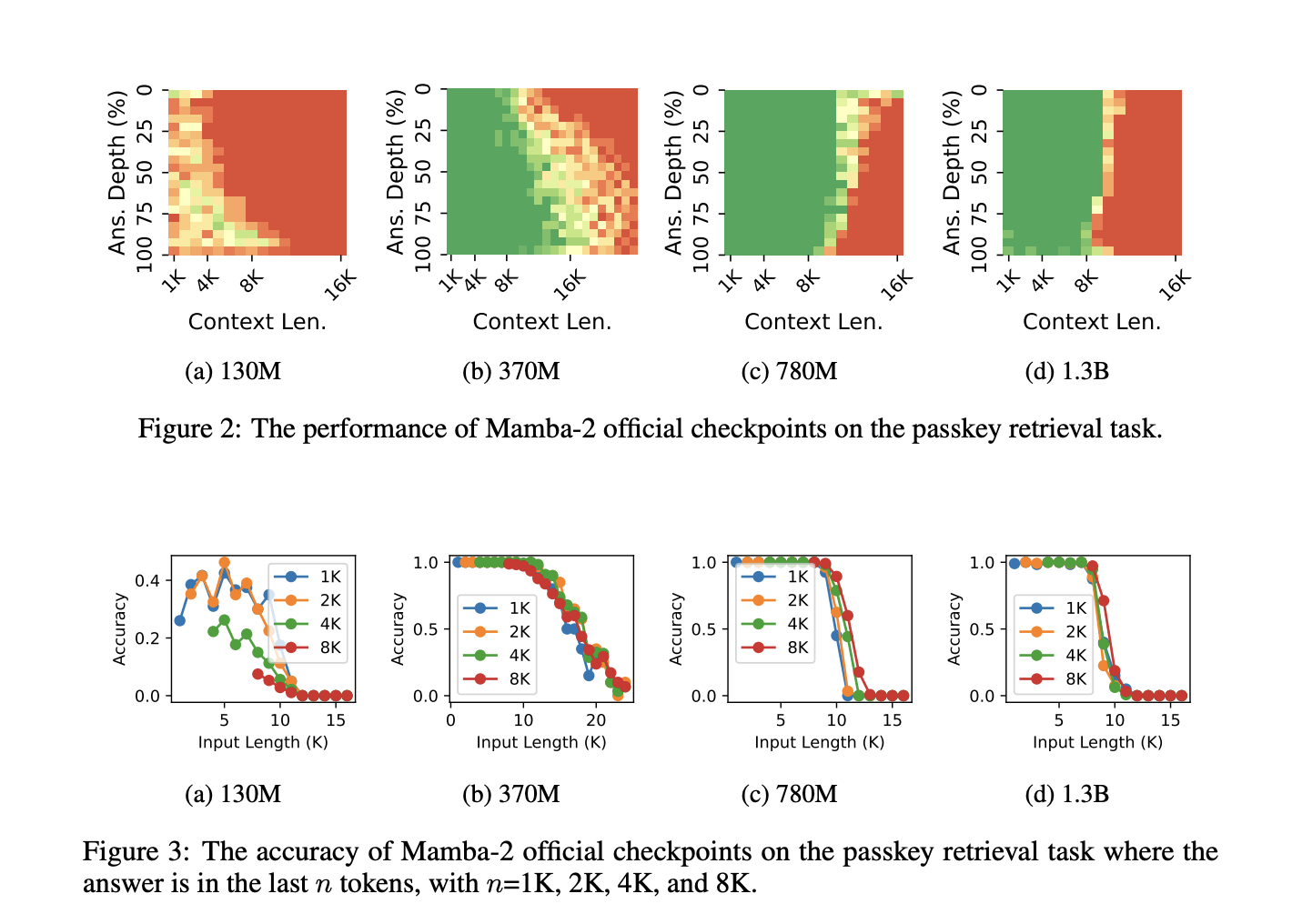
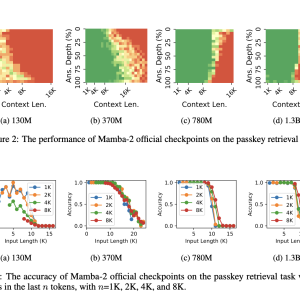
The authors highlighted the unprecedented behavior of RNNs when context length exceeded training tokens. Furthermore, the research gave insights into information constraints on the state. There are only so many tokens that a recurrent net can remember. Beyond this limit, all the tokens are forgotten, just like students can cram up so much information a day before their End term examinations. Just like the subpar performance in end terms could be attributed to students’ negligence throughout the semester, authors attributed RNNs’ generalization failure to a phenomenon called state collapse.
The authors inspected the memory state distribution of RNN over time and discovered that a few dominant outlier channels with exploding values caused its collapse. When the output hidden representation was normalized, these outliers caused vanishing values in other channels. Further, they showed that the state collapse was caused by RNNs’ inability to forget the earliest token and state overparameterization with excessive state capacity, not because of the prompt. Done with the diagnosis of State Collapse and its root cause, the authors proposed three training-free mitigation methods and one method based on continual training to improve the length generalizability of RNNs.The three training-less methods were -: Forget More and Remember Less, State Normalization, and Sliding Window by State Difference. These methods forced the model to forget contextual information by reducing the memory retention and insertion strength, normalizing the recurrent state, or reformulating the recurrence into an equivalent sliding window state. Lastly, they proposed training on context lengths that exceed the model’s state capacity in data engineering and state initialization with Truncated Backpropagation Through Time.
The authors experimented with various model sizes of Mamba 2 and mitigated state collapse by up to 1 million tokens. They also empirically estimated the state capacity of Mamba-2 on language modeling and the passkey retrieval task. When a few data engineering and state initialization tricks were applied to Mamba 2, it showed remarkable performance. The experimented Mamba-2 370M model could achieve near-perfect passkey retrieval accuracy on 256K context length, significantly outperforming transformer-based models of the same size in both retrieval accuracy and length generalizability. This particular model became the smallest model with near-perfect passkey retrieval accuracy. The authors also established that state capacity is a linear function of the state size.
This research shows that RNN-based long-context modeling has promising potential, and just like a student who crams the entire syllabus in one night requires an excellent teacher to excel in exams, RNNs also need some care and teaching before and during the training. Hence, the inference is free of generalization error.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post This AI Research Diagnoses Problems in Recurrent Neural Networks RNN-based Language Models and Corrects them to Outperform Transformer-based Models on Long Sequence Tasks appeared first on MarkTechPost.