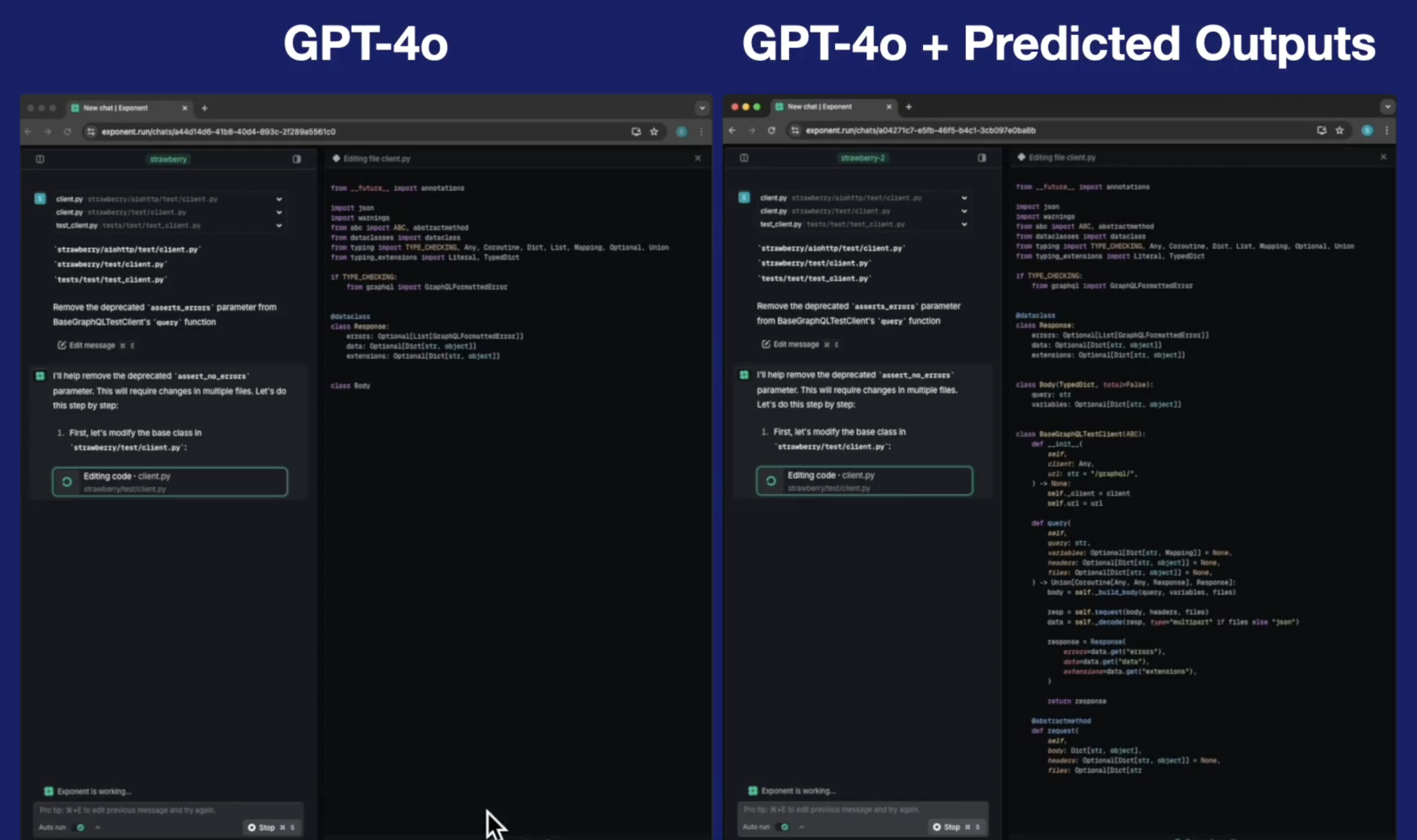
The use of large language models like GPT-4o and GPT-4o-mini has brought significant advancements in natural language processing, enabling high-quality response generation, document rewriting, and productivity enhancements across numerous applications. However, one of the biggest challenges these models face is latency. Whether it’s updating a blog post or refining lines of code, the lag associated with response generation can hinder seamless user experiences. This latency is particularly evident in applications requiring multiple iterations, such as document refinement or code rewriting, where users often experience frustrating delays that hamper productivity and discourage real-time use.
OpenAI has introduced the Predicted Outputs feature, which dramatically decreases latency for GPT-4o and GPT-4o-mini by providing a reference string. This feature is a game-changer, especially for those who use language models to iterate over content or make repeated updates. The key innovation lies in the ability to predict probable content and use it as a starting point for the model, effectively skipping portions of the process where the outcome is already well-established. By reducing computational overhead through this speculative decoding approach, latency can be decreased by as much as fivefold, making GPT-4o far more suitable for real-time tasks like document updates, code editing, and other iterative text generation activities. This enhancement is particularly beneficial for developers, content creators, and professionals who require rapid updates and minimal downtime in their workflows.
Technical Details and Benefits
The core mechanism behind Predicted Outputs is speculative decoding, a clever approach that allows the model to skip over known or expected content. Imagine you are updating a document where only minor edits are needed. In traditional scenarios, GPT models generate text word by word, evaluating each possible token at every stage, which can be time-consuming. However, with speculative decoding, if parts of the text can be predicted based on a provided reference string, the model can skip over them and immediately jump to the sections that require computation. This skipping mechanism significantly reduces latency, making it possible to iterate quickly on prior responses. Additionally, Predicted Outputs work particularly well in contexts where rapid turnaround is essential, such as live document collaboration, fast code refactoring, or real-time article updates. The integration of this feature ensures that interactions with GPT-4o are not only more efficient but also less burdensome for the infrastructure, ultimately reducing costs.
Why Predicted Outputs Matter
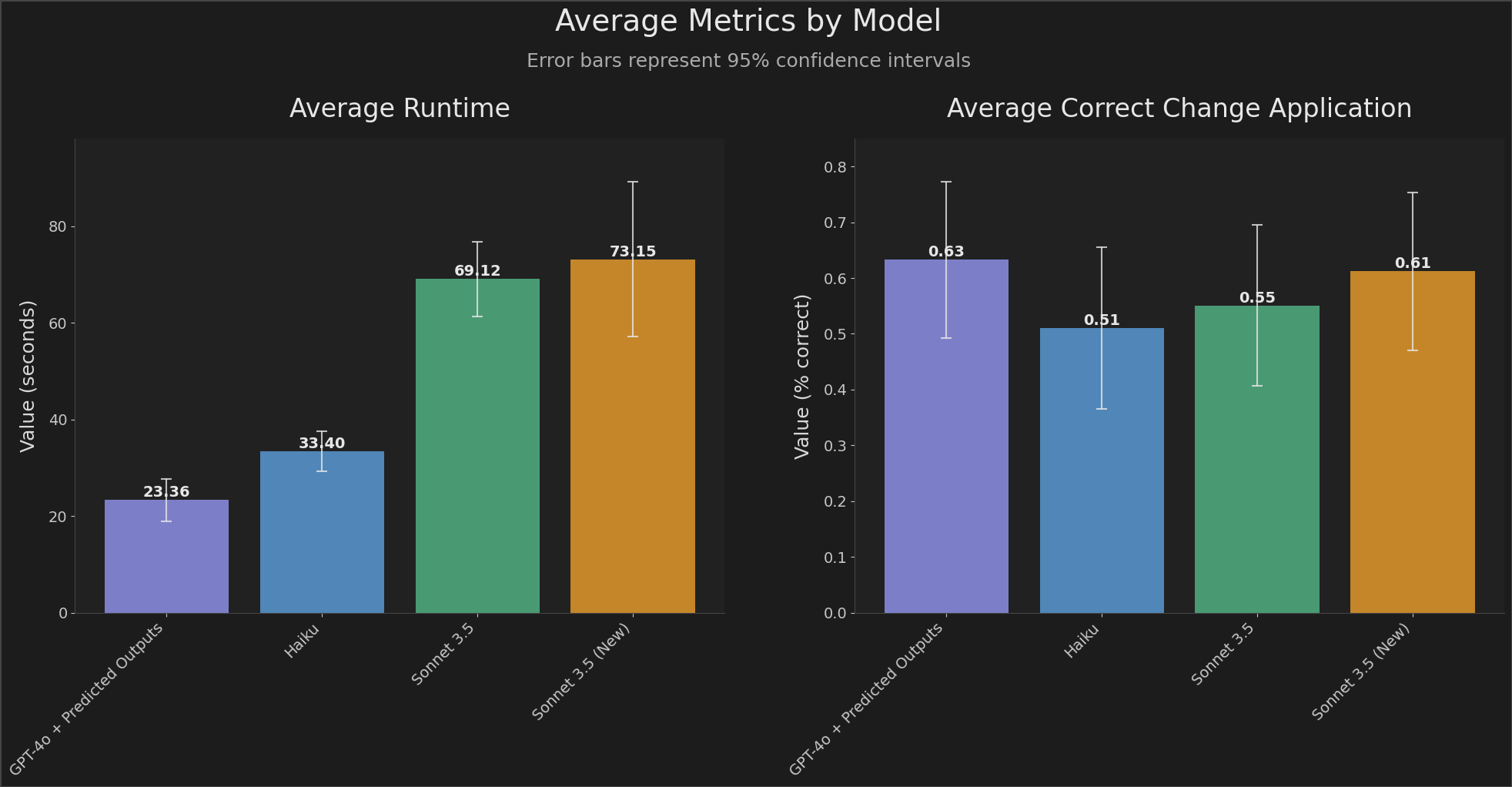
The importance of the Predicted Outputs feature cannot be overstated. One key reason is the dramatic reduction in latency it provides, as speed becomes a critical factor in the effectiveness of AI applications for real-world scenarios. For instance, an improvement in latency of up to fivefold can make a significant difference for developers who rely on AI tools to rewrite or refine code, allowing them to work faster with fewer interruptions. Similarly, content creators updating blogs or documents in real-time will find the reduced latency crucial in enhancing their productivity and keeping content up to date. Results from OpenAI’s testing have shown that GPT-4o’s performance on latency-sensitive tasks, such as iterative document editing and code rewriting, has improved considerably, with up to 5x faster response times in common use cases. By cutting down on lag, Predicted Outputs not only save time but also make GPT-4o and GPT-4o-mini more accessible and practical for a broader range of users, from professional developers to writers and educators.
Conclusion
OpenAI’s introduction of the Predicted Outputs feature for GPT-4o and GPT-4o-mini marks a major step toward addressing one of the most significant limitations of language models: latency. With the incorporation of speculative decoding, this feature dramatically speeds up tasks such as document editing, content iteration, and code refactoring. The reduction in response time is transformative for user experience, ensuring that GPT-4o remains at the forefront of practical AI applications. By enabling up to 5x faster processing, Predicted Outputs make these models more efficient, allowing users to focus on creativity and problem-solving rather than waiting on model computations. For anyone relying on AI to enhance their productivity, this is a welcome development that takes us closer to seamless, real-time interaction with powerful language models.
Check out the Details and Tweet. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post OpenAI Introduces ‘Predicted Outputs’ Feature: Speeding Up GPT-4o by ~5x for Tasks like Editing Docs or Refactoring Code appeared first on MarkTechPost.