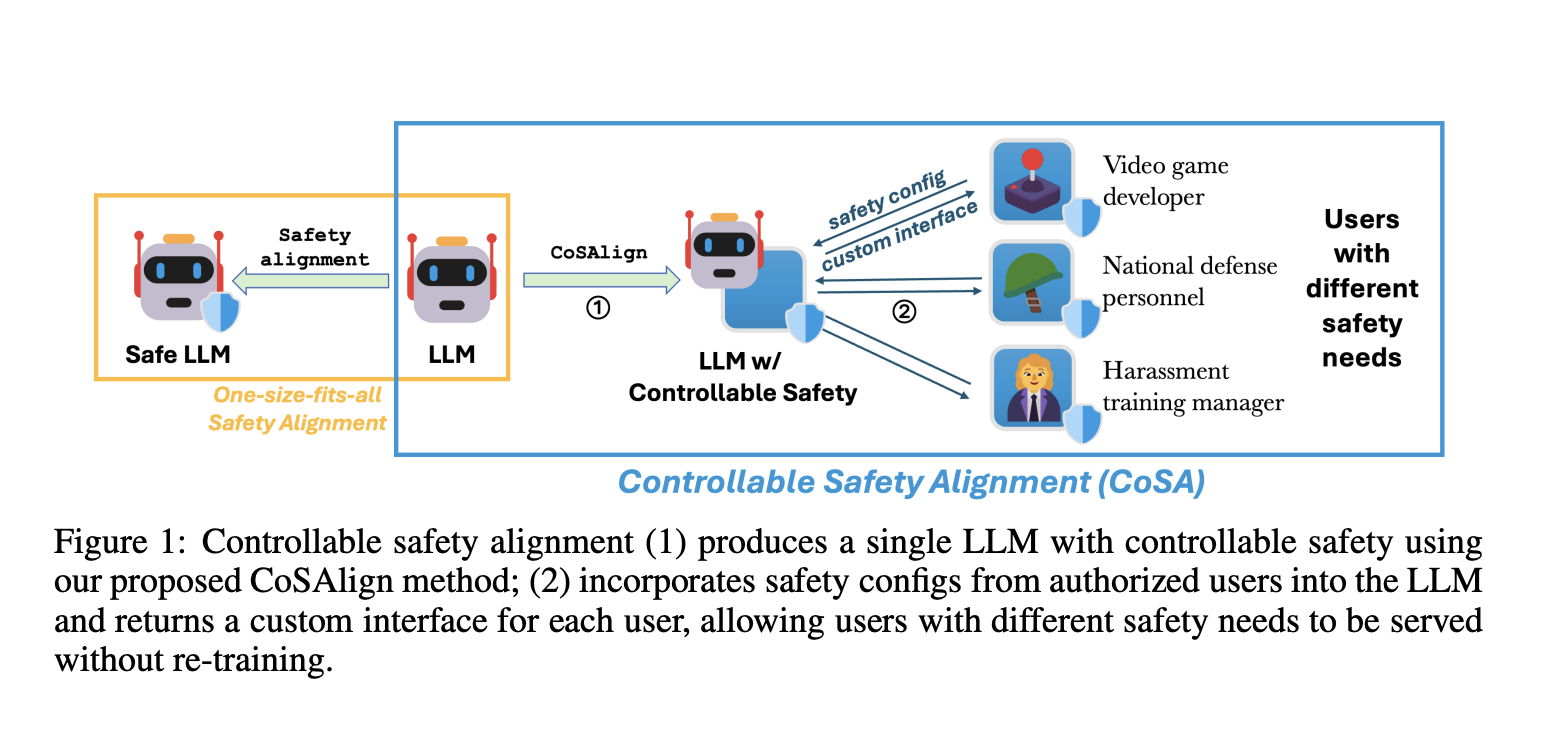
As large language models (LLMs) become increasingly capable and better day by day, their safety has become a critical topic for research. To create a safe model, model providers usually pre-define a policy or a set of rules. These rules help to ensure the model follows a fixed set of principles, resulting in a model that works the same for everyone. While the current approach works for general use cases, it fundamentally ignores the variability of safety across cultures, applications, or users. Therefore, the plurality of human values, i.e., the current paradigm for safety alignment of large language models (LLMs) follows a one-size-fits-all approach: the model simply avoids interacting with any content that the developers consider unsafe. In various cases, a standard one-size-fits-all safe model is too restrictive to be helpful. In addition, users may have diverse safety needs, making a model with static safety standards too restrictive to be useful, as well as too costly to be re-aligned. Hence, this approach lacks flexibility in the face of varying social norms across cultures and regions. Users may also have different safety needs, which makes a model with fixed safety rules too limiting and expensive to adjust.
Current methods involve pre-defining a fixed set of safety principles that the model must follow, which does not adapt to different cultural or user-specific safety needs. Pluralistic alignment Recent works have underscored the significance of incorporating pluralistic human values and cultures in AI alignment. Some work explores enhancing pluralism in general or studies the reliability of the one-size-fits-all model in pluralistic settings, but none of them focused on pluralistic safety alignment. Some researchers highlighted that AI should have “normative competence,” meaning the ability to understand and adjust to diverse norms, promoting safety pluralism. Constitutional AI develops a single “constitution,” i.e., a set of universal rules that models should follow, and then trains the constitution into a one-size-fits-all model, which still requires re-training the model if the constitution changes.
An in-context alignment is an approach that adjusts the model’s behavior based on context. However, it has limitations due to the complexity of the safety configurations and the challenge of building quality demonstrations. Other methods include retraining and parameter merging to achieve multi-objective alignment. Some methods control the model by using instruction hierarchy (IH), which gives different importance to instructions. However, IH has its limitations and alternative approaches, such as rule-based rewards i.e. it fails to offer real-time adaptation.
A team of researchers from Microsoft Responsible AI Research and Johns Hopkins University proposed Controllable Safety Alignment (CoSA), a framework for efficient inference-time adaptation to diverse safety requirements.
The adapted strategy first produces an LLM that is easily controllable for safety. Models are adjusted to follow specific “safety configs,” which describe what content is allowed or not allowed. To meet the unique safety needs of users, the model uses safety configs provided by trusted people, like safety experts in a video game company, as part of its setup. A review process ensures the security of the model. This allows the model to adapt its safety settings during use without retraining, and users can access the customized model through special interfaces, like specific API endpoints.
The CoSA project aims to develop AI models that can meet specific safety requirements, especially for content related to video game development. They created a new method to evaluate and assess the model’s helpfulness and safety, using test configurations with safety guidelines and prompts that fall into three categories: fully allowed, fully disallowed, and mixed. The responses of the model are scored on these criteria. The researchers developed CoSApien, a manually crafted evaluation dataset designed to closely replicate real-world safety scenarios. CoSApien is a benchmark designed to rigorously test the model’s safety control, utilizing 5 safety guidelines and 40 test prompts for each guideline, addressing diverse safety and cultural needs with clear guidelines on acceptable risky content.
To facilitate the reproducible evaluation of CoSA, they propose a novel evaluation protocol that considers both the helpfulness and configured safety of model responses, summarizing them into a single CoSA-Score that represents the overall model controllability. The analysis found that using in-context alignment for models with controllable safety doesn’t work well because safety configs are complex and it’s hard to create good examples for them on a large scale. This made researchers present CoSAlign, a data-centric method that improves the controllability of model safety. CoSAlign starts by creating a list of risk categories from the training prompts and uses a system with a judge model and error scoring to generate varied preference data. It then builds more controllable models through preference optimization. Compared to strong baseline models, CoSAlign greatly enhances the ability to control safety configurations that were used during training and also performs well with new safety configurations that it hasn’t seen before.
The CoSAlign method significantly outperforms existing methods, including strong cascade methods using a GPT-4o evaluator, by achieving higher CoSA-Scores and generalizing well to new safety configurations. It increases the number of helpful and safe responses while it reduces helpful but unsafe ones. The initial fine-tuning stage (SFT) improves the performance of the model but may increase unsafe responses, making the subsequent preference optimization stage (DPO) essential for further enhancing safety. Evaluations with the CoSApien benchmark show CoSAlign consistently surpassing all methods, including the Cascade-Oracle approach. Overall, CoSAlign proves more effective than safety removal, with the potential for even better controllability through preference optimization.
In summary, the current safety alignment paradigm proposes the controllable safety alignment framework, a blueprint toward inference-time LLM safety adjustment without re-training. The researchers presented a set of contributions, including our human-authored benchmark (CoSApien), evaluation protocol (CoSA-Score), and method toward improved controllability (CoSAlign). After conducting extensive general safety evaluations, they find CoSAlign models robust. The main limitation is that the researchers did not systematically explore how CoSAlign scales with different model sizes. The framework is limited to safety and cultural alignment that can be described in natural language, which excludes implicit cultural and social norms. In the end, this framework encourages better representation and adaptation to pluralistic human values in LLMs, thereby increasing their practicality.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Controllable Safety Alignment (CoSA): An AI Framework Designed to Adapt Models to Diverse Safety Requirements without Re-Training appeared first on MarkTechPost.