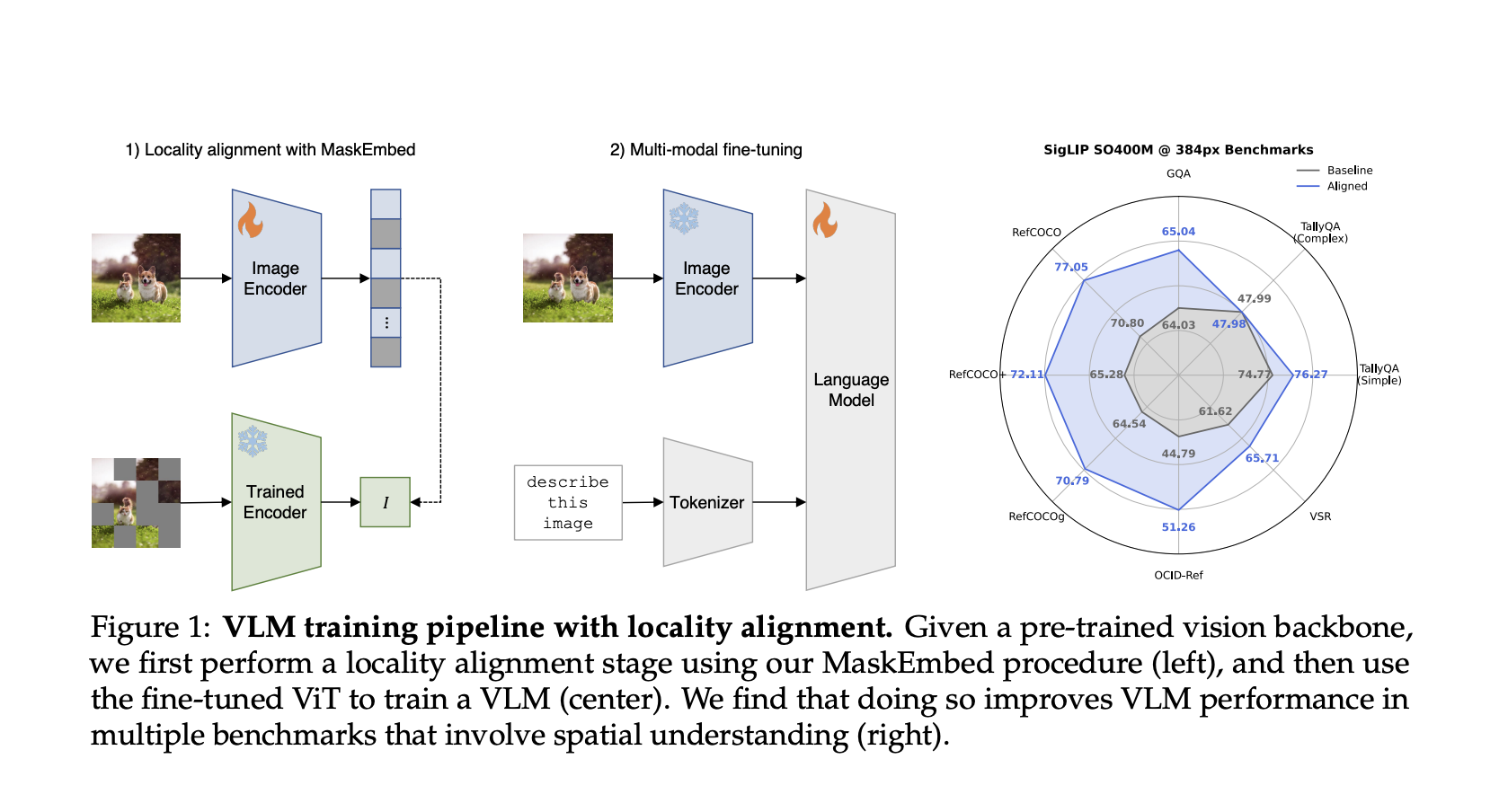
Vision-Language Models (VLMs) struggle with spatial reasoning tasks like object localization, counting, and relational question-answering. This issue stems from Vision Transformers (ViTs) trained with image-level supervision, which often fail to encode localized information effectively, limiting spatial understanding.
Researchers from Stanford University propose a novel solution called Locality Alignment, which involves a post-training stage for Vision Transformers. This process aims to enhance the local semantic extraction capabilities of ViTs to improve their performance on spatial reasoning tasks. Their approach includes a fine-tuning procedure called MaskEmbed, which uses a masked reconstruction loss to learn the semantic contributions of each image patch. By leveraging the latent knowledge of local semantics present in pre-trained models, the authors aim to align and enhance locality understanding in a scalable, self-supervised manner. This technique does not require new labeled data, making it efficient and easy to implement.
The proposed locality alignment process begins by applying the MaskEmbed procedure to pre-trained vision backbones. MaskEmbed works by masking parts of the image and training the model to reconstruct the masked portions. This allows the model to understand the contributions of each image patch to the overall representation. The training is conducted as a post-training phase on the ViT, which then integrates into a full Vision-Language Model pipeline. The approach can be applied to models trained with image-level supervision, such as CLIP or SigLIP. Importantly, MaskEmbed uses self-supervision, reducing computational costs compared to traditional supervised approaches. The process of locality alignment is visualized in the VLM training pipeline, starting with locality alignment and progressing to fine-tuning for vision-language tasks.
The effectiveness of locality alignment was tested using both vision-only and vision-language benchmarks. The locality-aligned ViTs showed improved performance in patch-level semantic segmentation tasks, particularly for models like CLIP and SigLIP that were trained with image-caption pairs. In the vision-language evaluations, VLMs trained with locality-aligned backbones demonstrated better performance across a range of benchmarks involving spatial understanding. Specifically, improvements were observed in tasks like object localization (RefCOCO, OCID-Ref), relational question-answering (VSR), and counting (TallyQA). The locality alignment approach improved local semantic extraction without sacrificing global image understanding, yielding significant performance improvements across multiple benchmarks.
Locality alignment effectively enhances the local semantic capabilities of vision backbones in Vision-Language Models. The MaskEmbed approach leverages self-supervision to improve local semantics in pre-trained ViTs, leading to better spatial reasoning performance. With low computational cost and consistent improvements, locality alignment is a promising addition to VLM training methods and may benefit other tasks requiring spatial understanding. The research emphasizes disentangling local and global semantics in vision backbones with a scalable approach.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Researchers at Stanford University Propose Locality Alignment: A New Post-Training Stage for Vision Transformers ViTs appeared first on MarkTechPost.