
There is a need for flexible and efficient adaptation of large language models (LLMs) to various tasks. Existing approaches, such as mixture-of-experts (MoE) and model arithmetic, struggle with requiring substantial tuning data, inflexible model composition, or strong assumptions about how models should be used. These limitations call for a methodology that can adapt LLMs efficiently without extensive tuning or restrictive assumptions, especially in low-data settings.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS, which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space. Inspired by Particle Swarm Optimization (PSO), MODEL SWARMS treats each LLM expert as a particle that collaboratively moves in the weight space to optimize a utility function that represents the adaptation objective. The approach begins with a pool of diverse LLM experts and optimizes their performance by guiding their movement in the weight space, driven by individual and collective performance markers. This enables efficient adaptation without supervised fine-tuning, making it suitable for low-data contexts with as few as 200 examples.
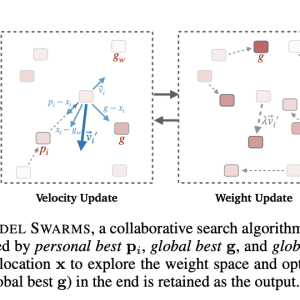
The proposed MODEL SWARMS framework has a unique structure where LLM experts (referred to as particles) have a defined location (weight configuration) and velocity (direction in weight space). The adaptation process is carried out by iteratively adjusting each expert’s velocity, influenced by inertia, personal best (the best performance of an individual particle), and global best/worst performance (the best/worst performance among all particles). This design helps the model balance exploration and convergence. The collaborative movement is governed by a utility function that may involve dataset performance or reward models, depending on the adaptation target, and this function helps to identify the best-found expert among the models as the final adapted model.
Experimental results indicate that MODEL SWARMS delivers significant improvements across various LLM adaptation tasks, outperforming 12 baseline model composition approaches by up to 21%. The research demonstrated superior results for both single-task adaptation and multi-task domains. Specifically, it achieved notable success in adapting models for single tasks like knowledge, reasoning, and safety, improving model performance by 13.3% on average. For multi-task settings in domains such as medical, legal, and cultural tasks, MODEL SWARMS showed a consistent performance boost by producing Pareto-optimal experts capable of optimizing multiple objectives simultaneously. The approach also proved effective for reward model adaptation and human interest-specific domains, highlighting its flexibility.
In conclusion, MODEL SWARMS represents a significant advancement in adapting LLMs efficiently and flexibly without the need for extensive tuning data or restrictive assumptions. By leveraging swarm intelligence, this approach allows LLMs to collaboratively search for optimal configurations collaboratively, thereby improving performance across a wide range of tasks. It holds promise for applications where low-data adaptation is essential, and its versatility can potentially reshape the way multiple LLMs are utilized for diverse and dynamic requirements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google AI Researchers Propose ‘MODEL SWARMS’: A Collaborative Search Algorithm to Flexibly Adapt Diverse LLM Experts to Wide-Ranging Purposes appeared first on MarkTechPost.