
Reinforcement learning (RL) provides a framework for learning behaviors for control and making decisions (known as policies) that help the model earn the most rewards in a given environment. Online RL algorithms iteratively take actions, collecting observations and rewards from the environment, and then update their policy using the latest experience. This online learning process is, however fundamentally slow. Recently it has become clear that learning behaviors from large previously collected datasets via behavioral cloning or other forms of offline RL, is an effective alternative way to build scalable generalist agents. Despite these advances, recent research indicates that agents trained on offline visual data often exhibit poor generalization to novel visual domains and can fail under minor visual variations in control-irrelevant factors, such as background or camera viewpoint. This issue hampers the generalization of agents trained on visual data.
Many environments have been developed to study the performance of RL agents. However, these environments evaluate the robustness of online RL agents to visual distractors and do not provide pre-collected trajectories for offline learning. While several datasets exist to assess the generalization of these representation-learning techniques to various visual perturbations these datasets do not provide the essential properties needed to evaluate these representation-learning methods for control thoroughly. Existing datasets and benchmarks for offline RL often lack the diversity and robustness needed to assess the agents under varying visual conditions. They typically do not include both state and pixel observations, limiting their utility in assessing the representation gap.
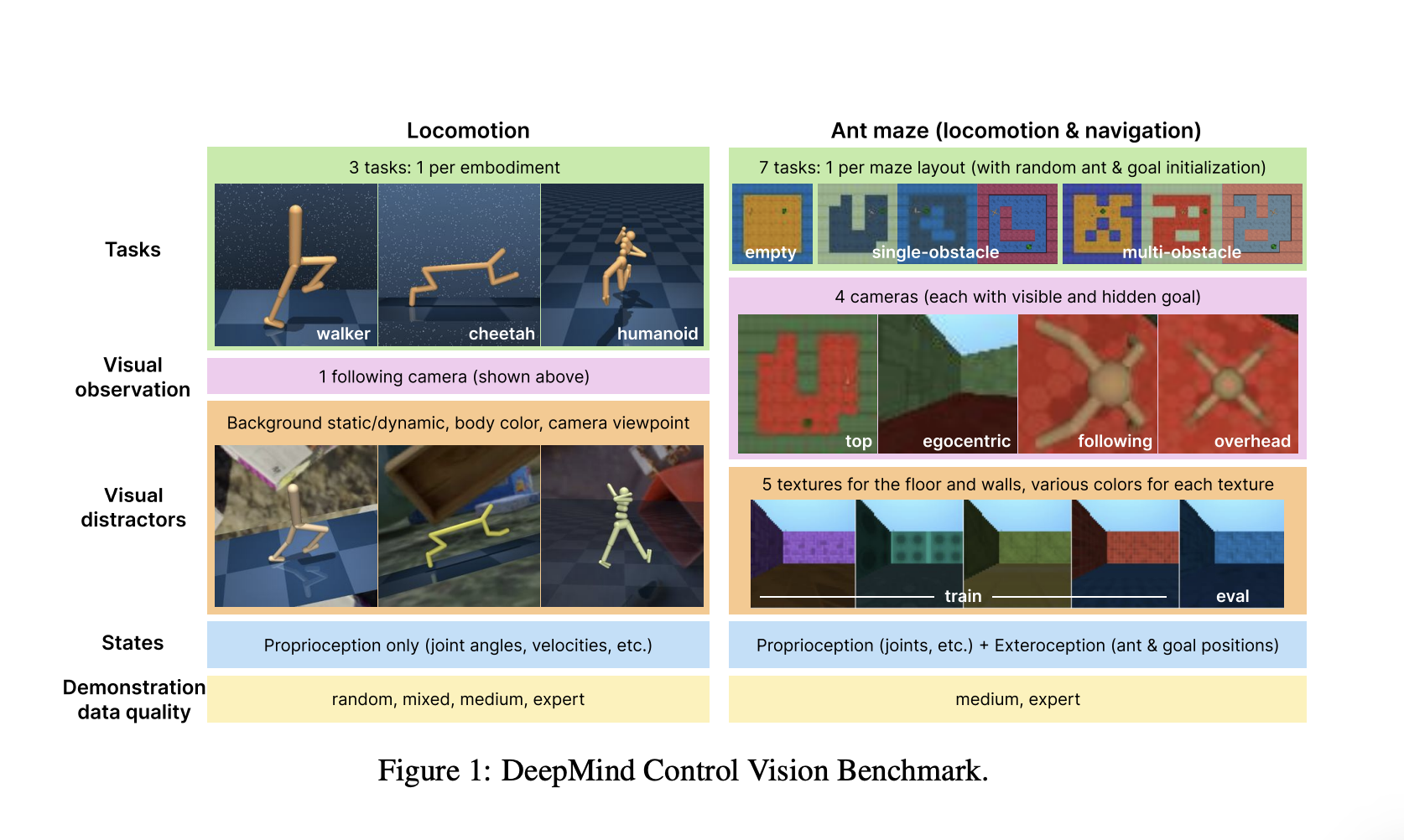
To mitigate these issues, the Google DeepMind researchers introduce the DeepMind Control Vision Benchmark (DMC-VB), a comprehensive dataset designed to evaluate the robustness of offline RL agents in continuous control tasks with visual distractors2. DMC-VB includes diverse tasks, visual variations, and data from policies of different skill levels, making it a more rigorous benchmark for representation learning methods.
To fill the gaps, a group of researchers from Google DeepMind introduced the DeepMind Control Vision Benchmark (DMC-VB)—a dataset collected using the DeepMind Control Suite and various extensions thereof. DMC-VB is carefully designed to enable systematic and rigorous evaluation of representation learning methods for control in the presence of visual variations, by satisfying six key desiderata. (a) It contains a diversity of tasks including tasks where state-of-the-art algorithms struggle to drive the development of novel algorithms. (b) It contains different types of visual distractors (e.g. changing background, moving camera) to study the robustness of various realistic visual variations. (c) It includes demonstrations of differing quality to investigate whether effective policies can be derived from suboptimal demonstrations. (d) It includes both pixel observations and states, where states are relevant proprioceptive and exteroceptive measurements. Policies trained on states can then provide an upper bound to quantify the “representation gap” of policies trained on pixels. (e) It is larger than previous datasets. (f) It includes tasks where the goal cannot be determined from visual observations, for which recent work suggests that pretraining representations are critical. As DMC-VB is the first dataset to satisfy these six desiderata it is well placed to advance research in representation learning for control. DMC-VB contains both simpler locomotion tasks and harder 3D navigation tasks.
Accompanying the dataset, they proposed three benchmarks that leverage the carefully designed properties of DMC-VB to evaluate representation learning methods for control. (B1) evaluates the degradation of policy learning in the presence of visual distractors and, in doing so, quantifies the representation gap between agents trained on states and pixel observations. Researchers found that the simple behavior cloning (BC) baseline is the best overall method and that recently proposed representation learning methods, such as inverse dynamics (ID), do not show benefits on our benchmark. (B2) investigates a practical setting with access to a large dataset of mixed-quality data and a few expert demonstrations. Upon deep investigation, researchers discovered that using a mix of data to pre-train visual representations helps improve how agents learn policies. Also, when studying how agents learn from demonstrations with hidden goals (like when they explore a new environment without specific goals), they found that these pre-trained representations help agents quickly learn new tasks with only a few examples.
The paper presents a robust solution to evaluate the generalization of offline RL agents under visual variations and evaluate their effectiveness. DMC-VB could be extended to a broader range of environments, including sparse rewards, multiple agents, complex manipulation tasks, or stochastic dynamics. Also, the synthetic nature of our visual distractors may raise questions about the generalization of our findings to real-world tasks. The DMC-VB dataset and benchmarks provide a detailed framework for advancing research in representation learning for control tasks and henceforth provide a future base for upcoming researchers.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google DeepMind Introduces DeepMind Control Vision Benchmark (DMC-VB): A Dataset and Benchmark to Evaluate the Robustness of Offline Reinforcement Learning Agents to Visual Distractors appeared first on MarkTechPost.