
The ever-increasing size of Large Language Models (LLMs) presents a significant challenge for practical deployment. Despite their transformative impact on natural language processing, these models are often hindered by high memory transfer requirements, which pose a bottleneck during autoregressive generation. This results in high energy consumption and substantial inference time, limiting their scalability and use on memory-constrained hardware. Post-training compression has emerged as a viable solution, but many current state-of-the-art methods require calibration data, making them cumbersome for data-free scenarios. The key problem, therefore, is how to effectively compress LLM weights without sacrificing accuracy or requiring calibration data.
Researchers from Apple and Meta AI introduce SeedLM, a novel approach that aims to overcome the challenges associated with the deployment of large-scale LLMs by providing a data-free compression method. SeedLM utilizes seeds of pseudo-random generators to encode and compress model weights, significantly reducing memory access while preserving computational efficiency. By leveraging Linear Feedback Shift Registers (LFSRs), SeedLM generates pseudo-random matrices during inference, trading off increased computation for fewer memory accesses. Unlike existing compression techniques, SeedLM operates without calibration data and achieves competitive results across diverse tasks, maintaining high zero-shot accuracy even at lower bit precision. The approach specifically focuses on compressing the weights of models such as Llama 3 70B into 3-4 bits with minimal accuracy degradation.
SeedLM compresses model weights using pseudo-random projection bases generated by LFSRs, widely used in hardware implementations like cryptography and communication systems. Each weight block of the LLM is projected into a random basis generated from an optimal seed, effectively minimizing compression error. The compression process involves finding optimal seeds and projection coefficients that enable the efficient reconstruction of weights using only the seed and a few coefficients instead of storing all individual weight values. The LFSR mechanism is implemented in silicon, making it energy-efficient and suitable for memory-bound tasks.
The primary goal of SeedLM is to generate a pseudo-random matrix using an LFSR with a given seed, which is then linearly combined with compressed coefficients to approximate the weight block. This matrix is reconstructed on the fly during inference, allowing SeedLM to avoid storing the full model parameters in memory. The process involves segmenting the weight matrix into smaller blocks, which are then compressed using a random matrix derived from the LFSR, thereby reducing the memory footprint required for large models.
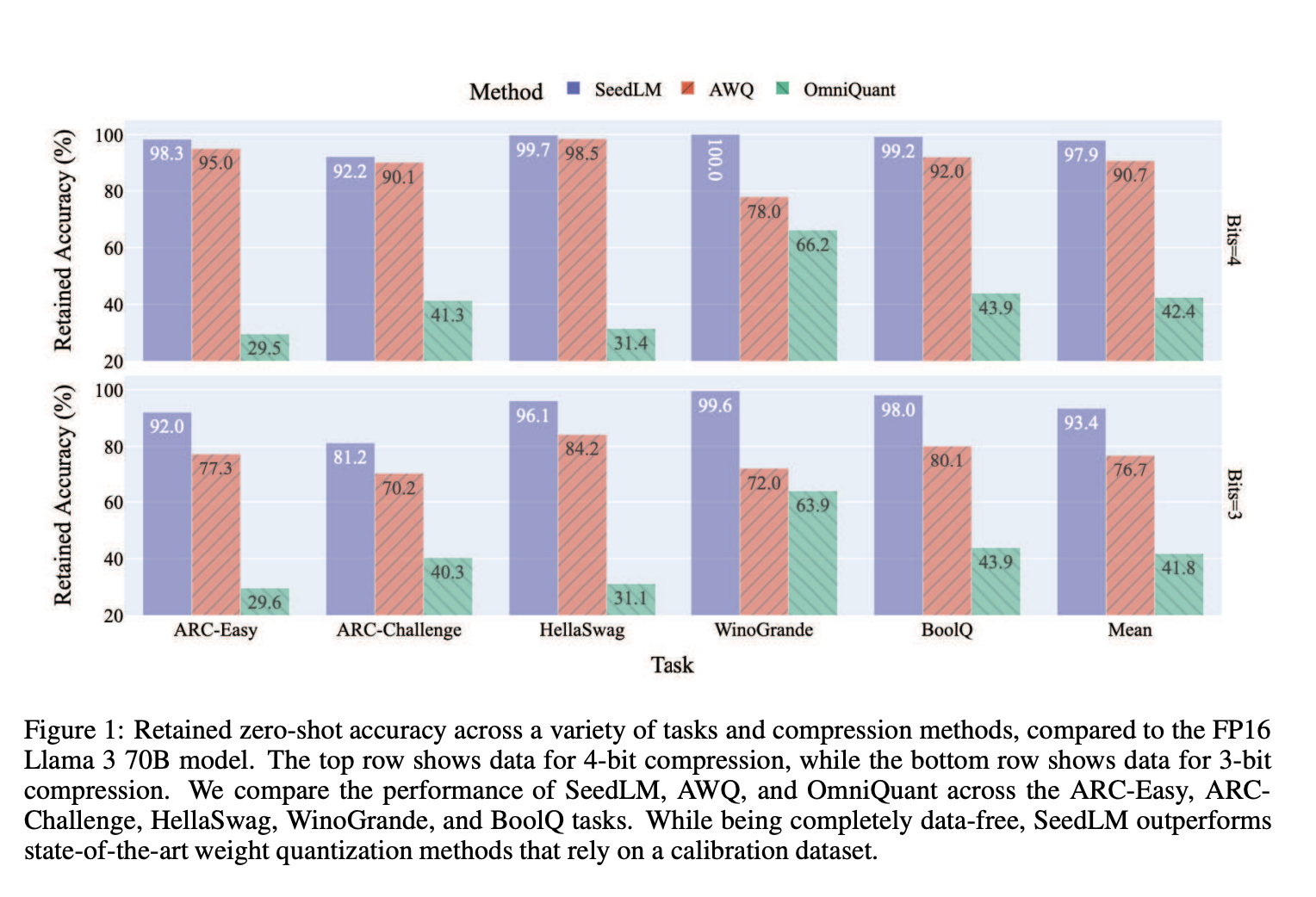
SeedLM was tested on various LLMs, including Llama 2 and Llama 3 models, with parameters ranging up to 70 billion. In these experiments, SeedLM consistently outperformed state-of-the-art compression techniques, particularly at 4-bit and 3-bit precision levels. For instance, using the 4-bit configuration, SeedLM achieved approximately 97.9% of the zero-shot accuracy on average across diverse tasks compared to the full-precision FP16 baseline. Notably, SeedLM is entirely data-free, which distinguishes it from other methods, such as AWQ and OmniQuant, that rely on calibration data for fine-tuning. The FPGA-based tests further demonstrated that as model size increased to 70B, SeedLM provided nearly a 4x speed-up over the FP16 baseline in terms of memory-bound task performance.
The accuracy evaluation on benchmark datasets like WikiText-2 and zero-shot tasks using the LM Evaluation Harness showed that SeedLM retained accuracy effectively while achieving significant compression. For instance, in Llama 2 70B, SeedLM’s 4-bit version retained almost 99% of the baseline performance, showcasing its capability to balance compression and accuracy without calibration dependencies. Additionally, the FPGA implementation of SeedLM highlighted its efficiency in hardware environments, achieving significant reductions in inference latency by efficiently managing memory bandwidth and utilizing LFSR blocks for rapid weight reconstruction.
SeedLM presents an effective solution for compressing LLM weights by utilizing pseudo-random generators, offering a practical approach for scaling large models on memory-limited hardware. By eliminating the need for calibration data and relying on deterministic offline algorithms, SeedLM simplifies the compression process while retaining high accuracy levels. The FPGA implementation further emphasizes its potential in real-world applications, providing up to a 4x speed-up in memory-bound tasks. SeedLM represents a promising step in making LLMs more efficient and deployable without compromising their performance, particularly on devices with limited computational resources.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post SeedLM: A Post-Training Compression Method that Uses Pseudo-Random Generators to Efficiently Encode and Compress LLM Weights appeared first on MarkTechPost.