Large language models (LLMs) have become crucial in natural language processing, particularly for solving complex reasoning tasks. These models are designed to handle mathematical problem-solving, decision-making, and multi-step logical deductions. However, while LLMs can process and generate responses based on vast amounts of data, improving their reasoning capabilities is an ongoing challenge. Researchers are continuously exploring ways to enhance these models’ efficiency by focusing on how LLMs approach step-by-step reasoning, allowing them to produce more accurate results without merely relying on final outcomes.
One of the significant hurdles in this research area is that LLMs, as they exist today, often receive feedback only after the final step of their reasoning processes. This outcome-based feedback means that if the final answer is incorrect, the model needs to receive sufficient guidance on which steps were correct or where it went wrong in intermediate steps. With intermediate feedback, it is easier for LLMs to learn efficiently from their mistakes or successes. This lack of detailed guidance during the reasoning process limits their ability to improve problem-solving skills, particularly in complex, multi-step tasks where each step plays a critical role in reaching the correct conclusion.
Current methods to tackle this issue primarily rely on Outcome Reward Models (ORMs). ORMs assess the correctness of the solution only at the final step of the process, which provides a very sparse learning signal. Some recent efforts have introduced Process Reward Models (PRMs), which give feedback at each intermediate step. These PRMs aim to improve the learning process by providing finer-grained supervision. However, PRMs that rely on human-generated labels are not scalable, and even automated PRMs have shown only limited success, with small gains in performance—often just 1-2% over ORMs. These marginal improvements highlight the need for more efficient and scalable methods to train LLMs.
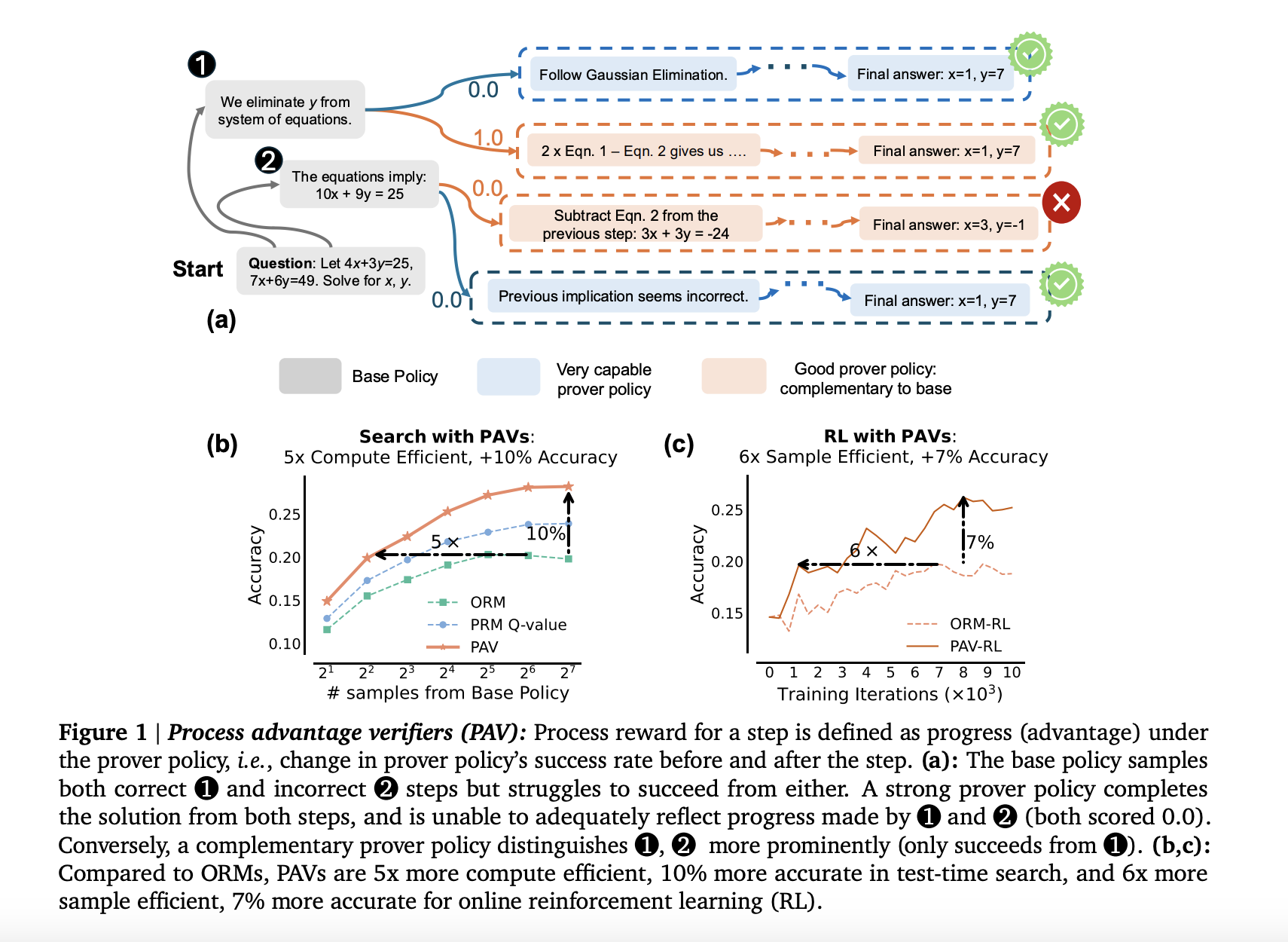
Researchers from Google Research, Google DeepMind, and Carnegie Mellon University have introduced an innovative approach to overcome these limitations by developing Process Advantage Verifiers (PAVs). These verifiers offer step-level rewards that measure the progress of the reasoning process instead of just assessing the outcome. PAVs are designed to evaluate each step in the reasoning trace based on how much it improves the likelihood of producing a correct solution. This method contrasts with traditional PRMs that focus on immediate correctness, allowing the model to learn from steps that may not directly lead to the correct answer but increase the chances of success in the later stages of reasoning.
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. The prover policy evaluates progress by measuring the difference in the probability of success before and after a reasoning step. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. The research team implemented this by training PAVs to predict “process advantages” for each reasoning step under a prover policy. These advantages are similar to reinforcement learning concepts, where a step is evaluated based on the future expected reward, helping the model to navigate complex problem spaces more efficiently.
The results of using PAVs demonstrated significant improvements in both the accuracy and efficiency of LLM reasoning. In terms of performance, test-time search using PAVs was over 8% more accurate compared to models that used only outcome-based reward models. The efficiency gains were even more striking, with online reinforcement learning (RL) using PAVs being 5 to 6 times more sample-efficient than RL with traditional outcome-based methods. This means that models trained with PAVs required far fewer training samples to achieve similar or even better results than models using ORMs. Further, PAVs improved search efficiency, with a 1.5 to 5 times gain in compute efficiency during test-time search compared to ORMs. The researchers also observed that models trained with PAVs outperformed outcome-based models in several challenging reasoning tasks, especially those involving multi-step processes where intermediate steps are crucial for success.
Specifically, the models showed more than a 6% accuracy improvement when evaluated on various reasoning tasks, particularly in mathematical problem-solving scenarios. The researchers validated these findings across multiple models of varying sizes, including 2 billion, 9 billion, and 27 billion parameter models, where PAVs consistently outperformed ORMs. Notably, the models trained with PAVs demonstrated the ability to solve more complex problems that traditional models struggled with, showcasing the strength of this approach in enhancing the reasoning capabilities of LLMs.
In conclusion, the research introduces a promising method for improving the reasoning efficiency of large language models by shifting from outcome-based rewards to process-based rewards. Process Advantage Verifiers offer a new way to measure progress through intermediate steps, which enables better exploration and learning in complex problem-solving tasks. This approach not only improves the accuracy of LLMs but also significantly enhances their sample and compute efficiency. By addressing the limitations of traditional outcome-based models, this work represents a significant advancement in the field of LLM research, with significant implications for improving the overall capabilities of these models in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google AI Research Introduces Process Advantage Verifiers: A Novel Machine Learning Approach to Improving LLM Reasoning Capabilities appeared first on MarkTechPost.