A major challenge in the evaluation of vision-language models (VLMs) lies in understanding their diverse capabilities across a wide range of real-world tasks. Existing benchmarks often fall short, focusing on narrow sets of tasks or limited output formats, resulting in inadequate evaluation of the models’ full potential. The problem becomes more pronounced when evaluating newer multimodal foundation models that need comprehensive testing across numerous application domains. These models require a benchmarking suite capable of evaluating their abilities in various input and output scenarios while minimizing inference costs.
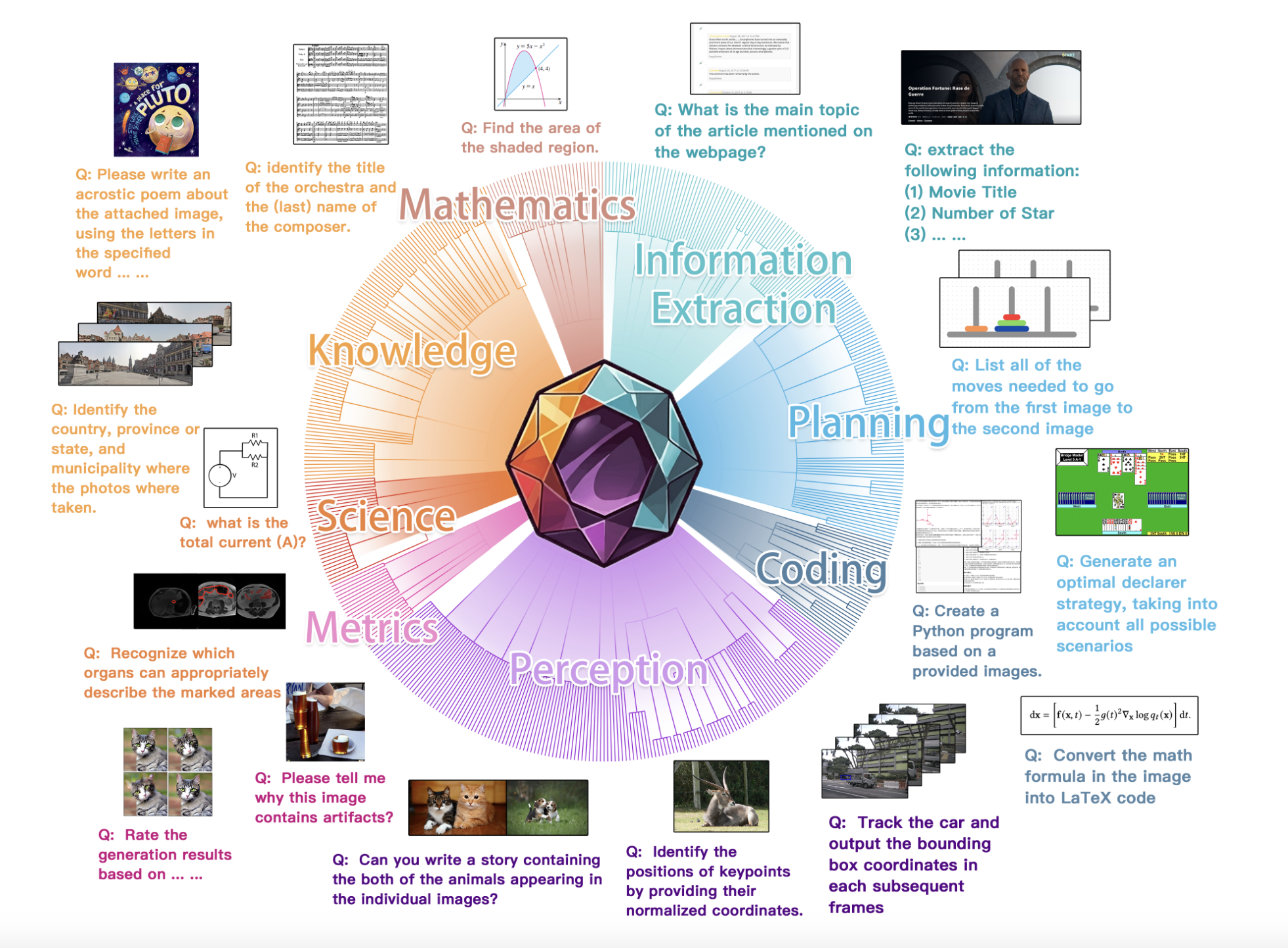
A team of researchers from the MEGA-Bench Team introduces MEGA-Bench, an innovative and comprehensive benchmark that scales multimodal evaluation to encompass more than 500 real-world tasks. MEGA-Bench aims to provide a high-quality, systematic evaluation of multimodal models across various inputs, outputs, and skill requirements, covering a broader range of use cases than previous benchmarks. Unlike earlier benchmarks focused on standardized outputs like multiple-choice questions, MEGA-Bench embraces a wide diversity of outputs, such as numbers, phrases, code, LaTeX, and JSON. This allows for an accurate assessment of generative and predictive capabilities, bringing forth the finer details of model performance.
The structure of MEGA-Bench is meticulously designed to ensure comprehensive coverage. It contains 505 multimodal tasks, which were curated and annotated by 16 expert contributors. The benchmark taxonomy includes categories like application type, input type, output format, and skill requirements, ensuring diverse and comprehensive task coverage. To accommodate the variety of outputs, over 40 metrics were developed, providing fine-grained and multidimensional analysis of the models’ capabilities. The benchmark also introduces an interactive visualization tool for users, enabling them to explore model strengths and weaknesses across different dimensions, making MEGA-Bench a more practical evaluation tool compared to traditional benchmarks.
The results from applying MEGA-Bench to various state-of-the-art VLMs highlighted some key findings. Among flagship models, GPT-4o outperformed others, including Claude 3.5, with a 3.5% higher score. Among open-sourced models, Qwen2-VL achieved top-tier performance, nearly matching proprietary models and outperforming the second-best open-source model by approximately 10%. For efficiency models, Gemini 1.5 Flash was found to be the most effective overall, with a specific strength in tasks related to User Interfaces and Documents. Another insight was that proprietary models benefited from Chain-of-Thought prompting, whereas open-source models struggled to leverage it effectively.
In conclusion, MEGA-Bench represents a significant advancement in multimodal benchmarking, offering a thorough and fine-grained evaluation of the capabilities of vision-language models. By supporting diverse inputs and outputs, as well as detailed performance metrics, it provides a more realistic evaluation of how these models perform across real-world tasks. This benchmark allows developers and researchers to better understand and optimize VLMs for practical applications, setting a new standard for multimodal model evaluation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post MEGA-Bench: A Comprehensive AI Benchmark that Scales Multimodal Evaluation to Over 500 Real-World Tasks at a Manageable Inference Cost appeared first on MarkTechPost.