

Current multimodal retrieval-augmented generation (RAG) benchmarks primarily focus on textual knowledge retrieval for question answering, which presents significant limitations. In many scenarios, retrieving visual information is more beneficial or easier than accessing textual data. Existing benchmarks fail to adequately account for these situations, hindering the development of large vision-language models (LVLMs) that need to utilize diverse types of information effectively.
Researchers from UCLA and Stanford introduced MRAG-Bench, a vision-centric benchmark designed to evaluate the effectiveness of LVLMs in scenarios where visual information provides a clear advantage over textual knowledge. MRAG-Bench consists of 16,130 images and 1,353 human-annotated multiple-choice questions across nine distinct scenarios, focusing on when visual knowledge is more beneficial. The benchmark systematically categorizes scenarios into two main aspects: perspective changes, which involve different angles or occlusions of visual entities, and transformative changes, which include temporal or physical transformations of objects. MRAG-Bench evaluates 10 open-source and four proprietary LVLMs, providing insights into their ability to utilize visually augmented knowledge.
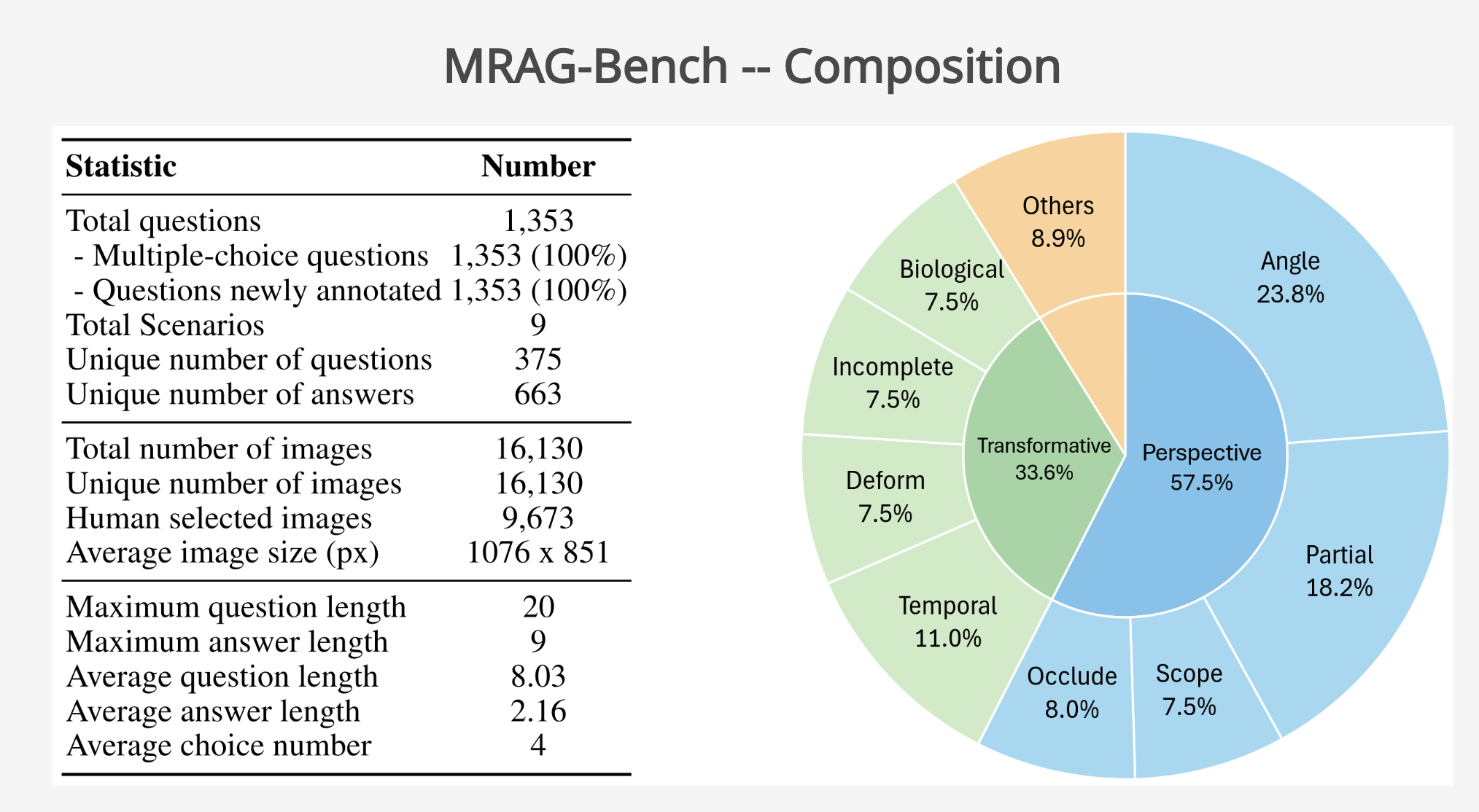
The structure of MRAG-Bench is centered around nine distinct scenarios divided into perspective understanding and transformative understanding aspects. The perspective aspect comprises four categories: Angle, Partial, Scope, and Occlusion. These categories challenge models to reason about entities when the visual input varies in viewpoints, levels of visibility, or resolution. The transformative aspect focuses on temporal, biological, and physical changes, requiring models to interpret visual entities undergoing significant transformations. Additionally, MRAG-Bench provides a clean, human-curated set of 9,673 ground-truth images, ensuring that the benchmark aligns with real-world visual understanding scenarios.
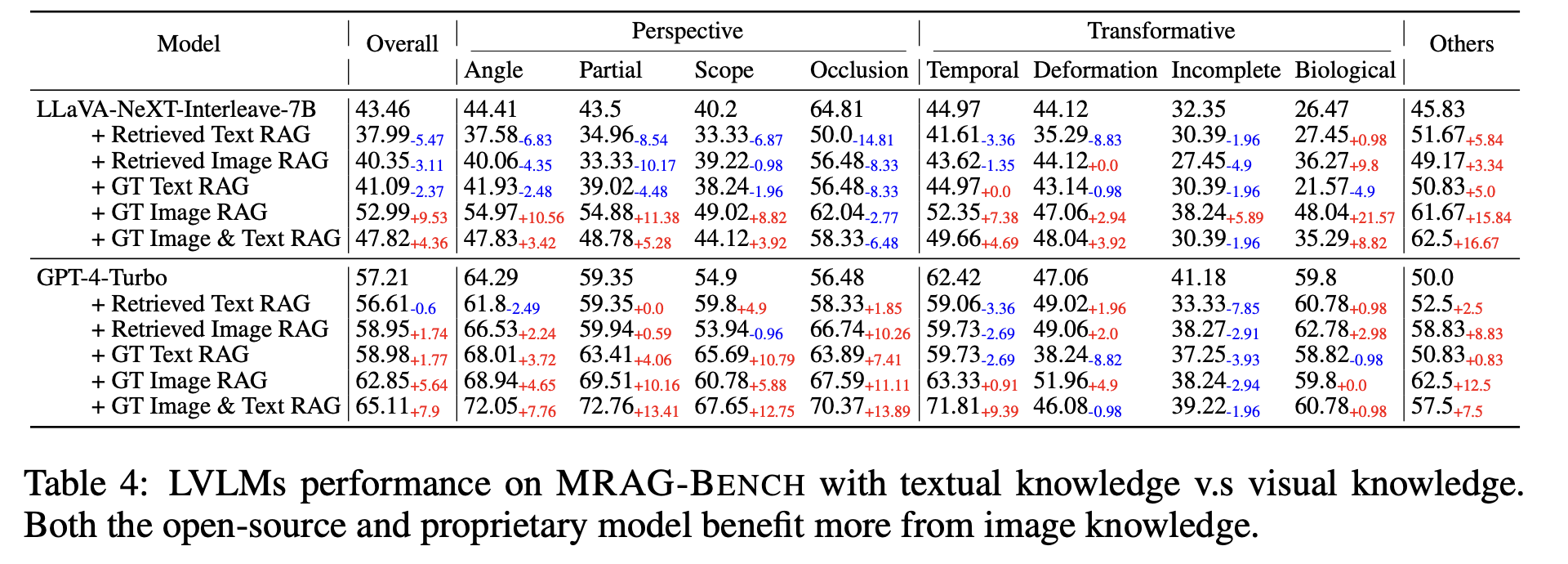
The evaluation results reveal that visually augmented knowledge significantly enhances model performance compared to textual augmentation. All evaluated LVLMs showed greater improvements when augmented with images, confirming the vision-centric nature of MRAG-Bench. Notably, the best-performing proprietary model, GPT-4o, achieved only a 5.82% improvement in performance with ground-truth visual augmentation compared to a 33.16% improvement demonstrated by human participants, indicating that current models are far from effectively leveraging visual knowledge as humans do. Furthermore, the results indicate that proprietary models are better at distinguishing between high-quality and noisy visual information compared to open-source models, which often struggle with utilizing retrieved knowledge effectively.
In conclusion, MRAG-Bench provides a novel vision-centric evaluation framework for assessing LVLMs, focusing on scenarios where visual retrieval surpasses textual knowledge. The findings highlight the critical gap between human performance and current models’ capabilities in effectively using retrieved visual information. The introduction of MRAG-Bench is an important step towards encouraging the development of LVLMs that can better leverage visual knowledge, with the ultimate goal of creating models that understand and utilize multimodal information as effectively as humans.
Check out the Paper, Dataset, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post Researchers from UCLA and Stanford Introduce MRAG-Bench: An AI Benchmark Specifically Designed for Vision-Centric Evaluation for Retrieval-Augmented Multimodal Models appeared first on MarkTechPost.