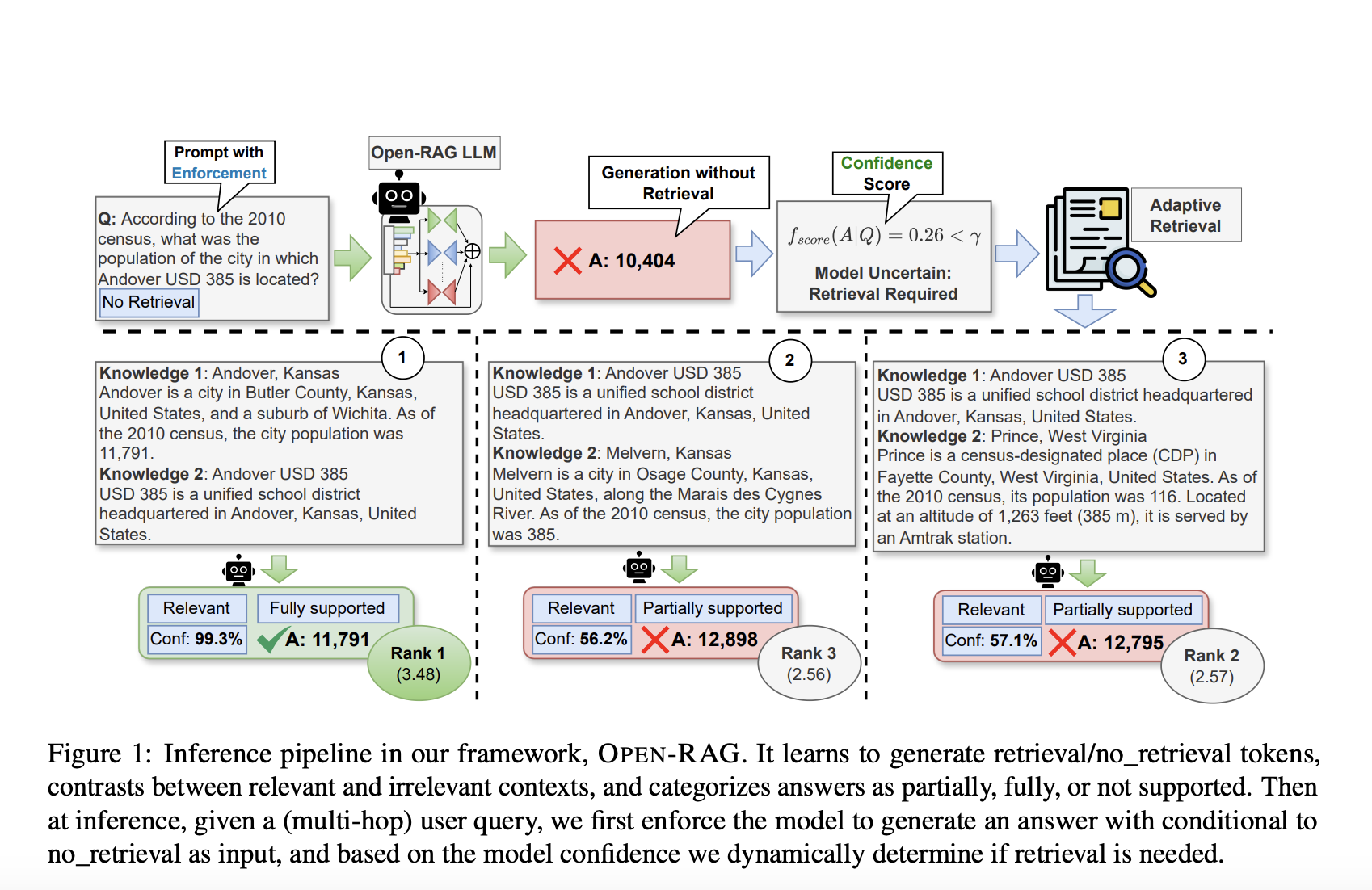
Large language models (LLMs) have greatly advanced various natural language processing (NLP) tasks, but they often suffer from factual inaccuracies, particularly in complex reasoning scenarios involving multi-hop queries. Current Retrieval-Augmented Generation (RAG) techniques, especially those using open-source models, struggle to handle the complexity of reasoning over retrieved information. These challenges lead to noisy outputs, inconsistent context, and difficulties in distinguishing relevant data from distractors.
Researchers from Bangladesh University of Engineering and Technology, University of North Texas, York University, Canada, Salesforce Research, Qatar Computing Research Institute (QCRI), Fatima Al-Fihri Predoctoral Fellowship, and the Cohere For AI Community introduce Open-RAG—a novel framework that enhances the reasoning abilities of retrieval-augmented generation models using open-source LLMs. Open-RAG transforms a dense LLM into a parameter-efficient sparse mixture of experts (MoE) model, capable of handling complex reasoning tasks, including both single- and multi-hop queries. By dynamically selecting relevant experts, the model effectively deals with distractors that appear relevant but are misleading. Open-RAG also incorporates a hybrid adaptive retrieval method that helps decide when to retrieve information, balancing performance gains and inference speed.
Structurally, Open-RAG integrates constructive learning, architectural transformation, and reflection-based generation into a cohesive framework. It transforms a dense LLM into a sparse MoE model that combines selective activation of experts with parameter efficiency. The framework trains the model not only for direct task performance but also for navigating and contrasting between useful information and distractors. This approach employs reflection tokens, which help control the retrieval process and assess the relevance and supportiveness of retrieved information. Open-RAG’s hybrid adaptive retrieval system also leverages these reflection tokens to decide whether retrieval is needed at any given point, thus enhancing the overall efficiency and accuracy of responses.
The experimental results show that Open-RAG, based on Llama2-7B, outperforms various state-of-the-art RAG models, such as ChatGPT-RAG, Self-RAG, and Command R+. In several knowledge-intensive tasks, Open-RAG demonstrated superior reasoning capabilities and factual accuracy compared to these proprietary models. For example, it surpassed the performance of ChatGPT-RAG in HotpotQA and MuSiQue datasets, which involve complex multi-hop questions. The hybrid adaptive retrieval method also proved effective in balancing retrieval frequency and improving overall response quality. Furthermore, Open-RAG’s ability to selectively activate experts based on query complexity ensures that the computational burden remains manageable without sacrificing performance.
Conclusion
In conclusion, Open-RAG represents a significant step forward in improving the factual accuracy and reasoning capabilities of RAG models with open-source LLMs. By combining a parameter-efficient MoE architecture with hybrid adaptive retrieval, Open-RAG delivers enhanced performance on complex reasoning tasks while remaining competitive with state-of-the-art proprietary models. This work not only highlights the potential of open-source LLMs in achieving high accuracy and efficiency but also sets the stage for future improvements, such as focusing on the performance of long-form generation tasks and further optimizing model architecture.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post OPEN-RAG: A Novel AI Framework Designed to Enhance Reasoning Capabilities in RAG with Open-Source LLMs appeared first on MarkTechPost.