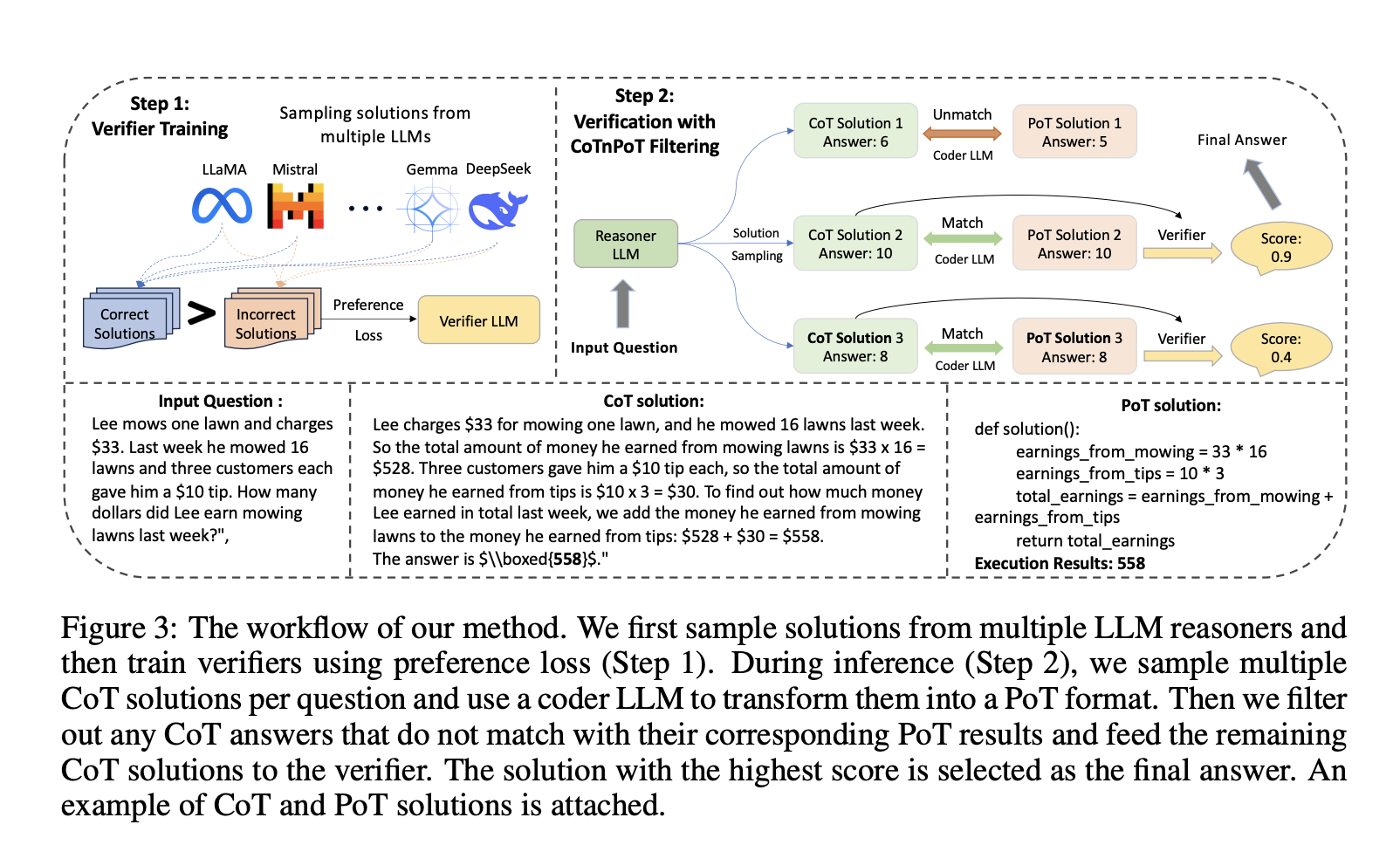
Large language models (LLMs) often fail to consistently and accurately perform multi-step reasoning, especially in complex tasks like mathematical problem-solving and code generation. Despite recent advancements, LLMs struggle to detect and learn from errors because they are predominantly trained on correct solutions. This limitation leads to difficulties in verifying and ranking outputs, particularly when subtle flaws are present.
Researchers from the University of Notre Dame and Salesforce AI introduce an innovative framework that scales up inference-time computation by generating multiple reasoning paths for complex tasks. Verifiers assess these paths and rank the generated outputs by correctness to improve accuracy. To train effective verifiers, the team developed a comprehensive dataset of both correct and incorrect solutions for math and code tasks generated by multiple LLMs. This dataset is unique because it includes a diverse range of solution patterns, allowing the verifiers to better distinguish between correct and erroneous answers. By integrating Chain-of-Thought (CoT) and Program-of-Thought (PoT) reasoning strategies, the researchers developed a novel collaborative verification approach that leverages both step-by-step human-readable reasoning and executable code validation.
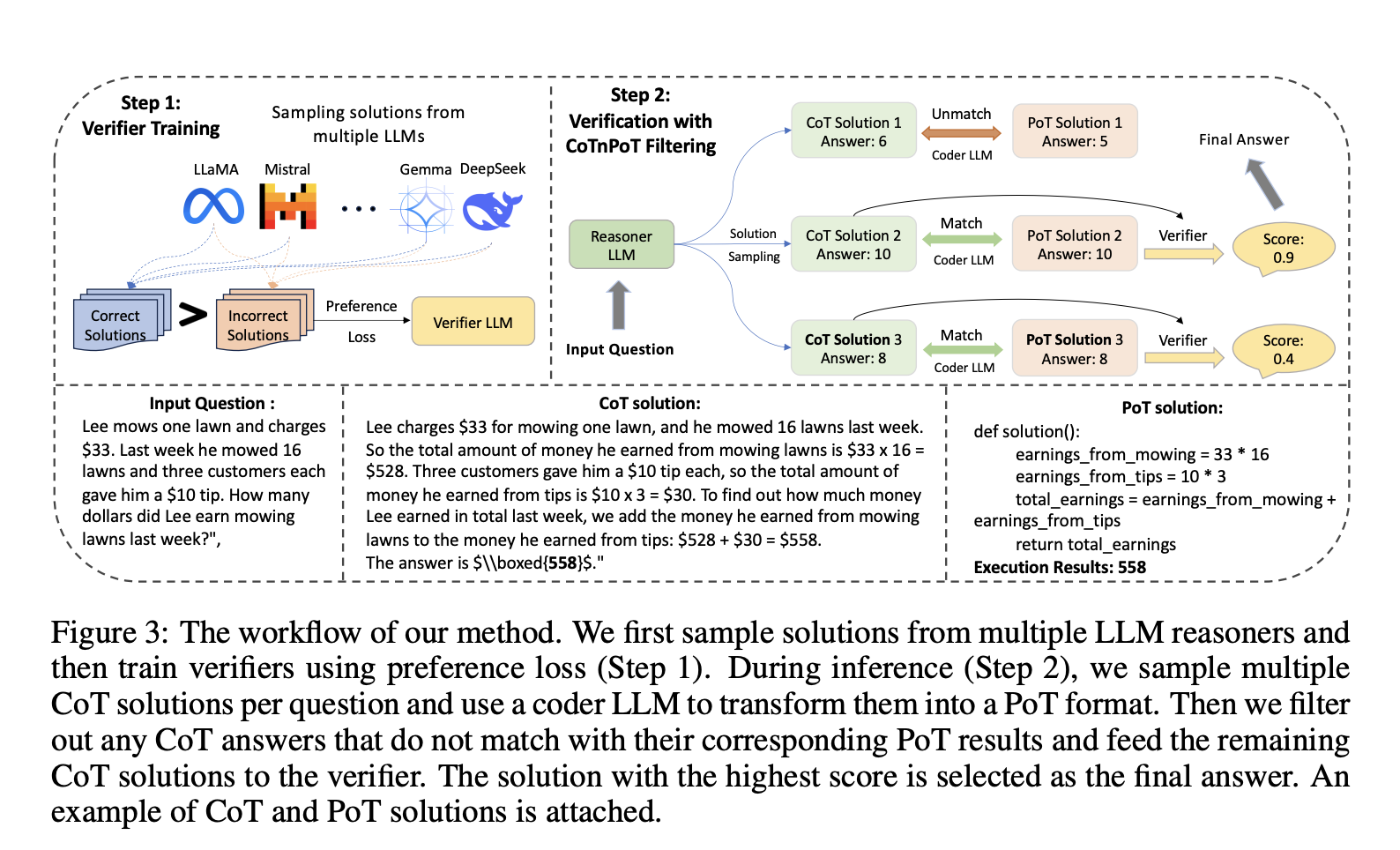
The dataset introduced is comprehensive, covering both math and code tasks. It consists of solutions generated by various LLMs, encompassing both correct and incorrect answers. For the math tasks, models such as Mistral, Phi, and InternLM2-Math were used, generating over 159,000 correct and 100,000 incorrect solutions. For code reasoning, datasets like MBPP and MagiCoder-75k were used to produce more than 132,000 correct and 145,000 incorrect code solutions. Each problem had multiple sampled solutions, providing a diverse collection of approaches and errors. This dataset was used to train two verifiers: Math Reasoning Ensembled Verifier (Math-Rev) and Code Reasoning Ensembled Verifier (Code-Rev), both developed using SimPO, a reference-free preference-tuning method.
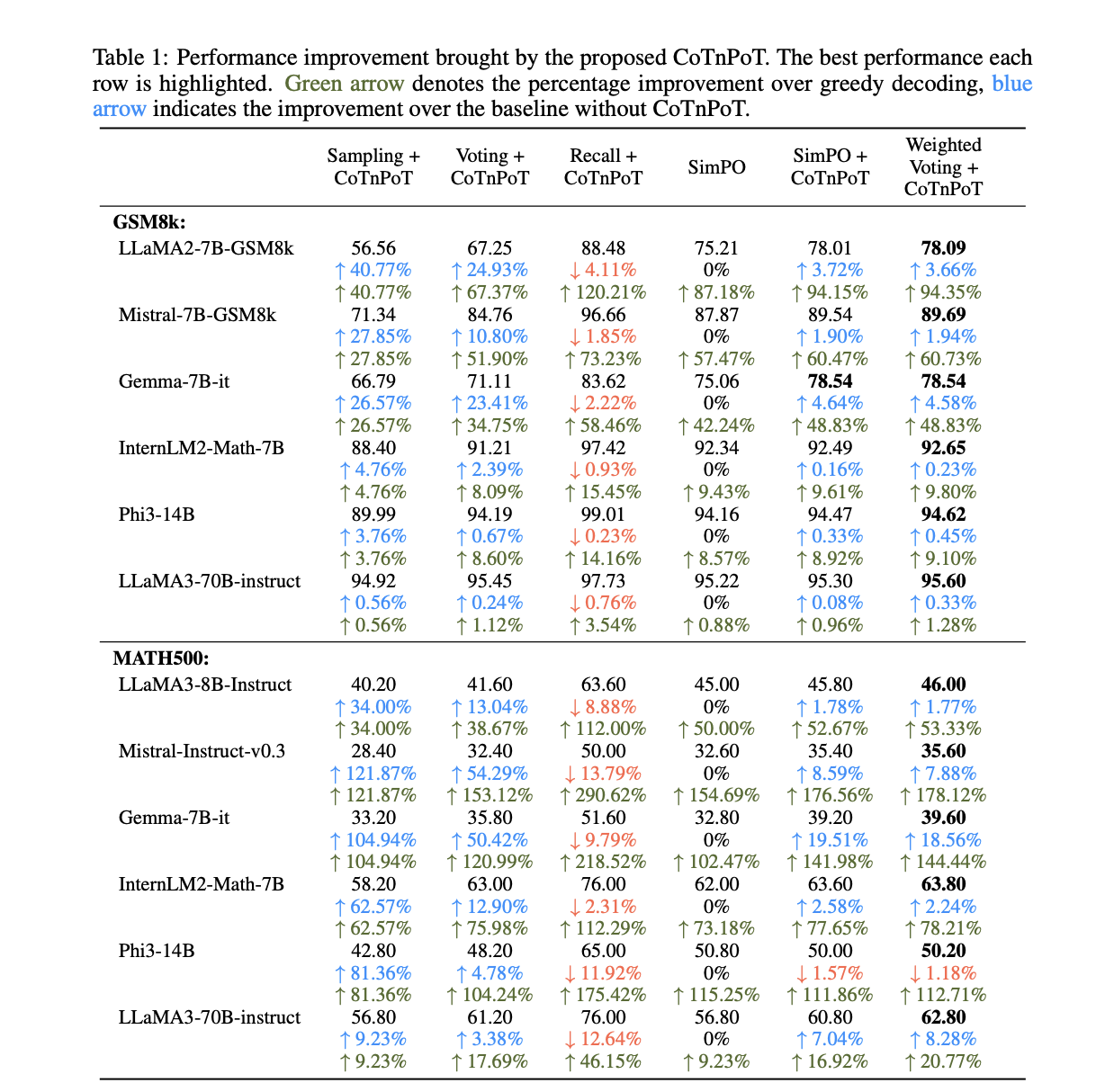
The results presented in the paper demonstrate significant improvements over previous methods. The verifiers Math-Rev and Code-Rev achieved state-of-the-art accuracy on benchmarks such as GSM8k and MATH, even surpassing the performance achieved by GPT-4o and LLaMA3. For instance, Math-Rev paired with Qwen-72B-Instruct outperformed LLaMA3.1-405B and GPT-4o on the MATH test set, with notable accuracy improvements. The researchers also compared different training methods for verifiers, finding that reference-free preference tuning, such as SimPO, performed better than traditional outcome reward models (ORM). Moreover, the integration of Chain-of-Thought and Program-of-Thought methods for verification, called CoTnPoT, proved effective in leveraging the strengths of both natural language and executable code to enhance verification accuracy.
Conclusion
This research introduces a new paradigm for improving the reasoning capabilities of LLMs by integrating collaborative verification with multiple reasoning paths and verifiers. By releasing their comprehensive dataset and verifiers, the researchers aim to foster future advancements in scaling up inference-time computation and enhancing the reliability of LLMs. Their approach not only achieves state-of-the-art results but also highlights the potential of integrating different reasoning strategies to make complex problem-solving more accurate and reliable. This work paves the way for more robust LLMs that can better understand and verify their own outputs, thus increasing the trustworthiness of AI-generated reasoning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post Salesforce AI Research Proposes Dataset-Driven Verifier to Improve LLM Reasoning Consistency appeared first on MarkTechPost.