

Problem Addressed
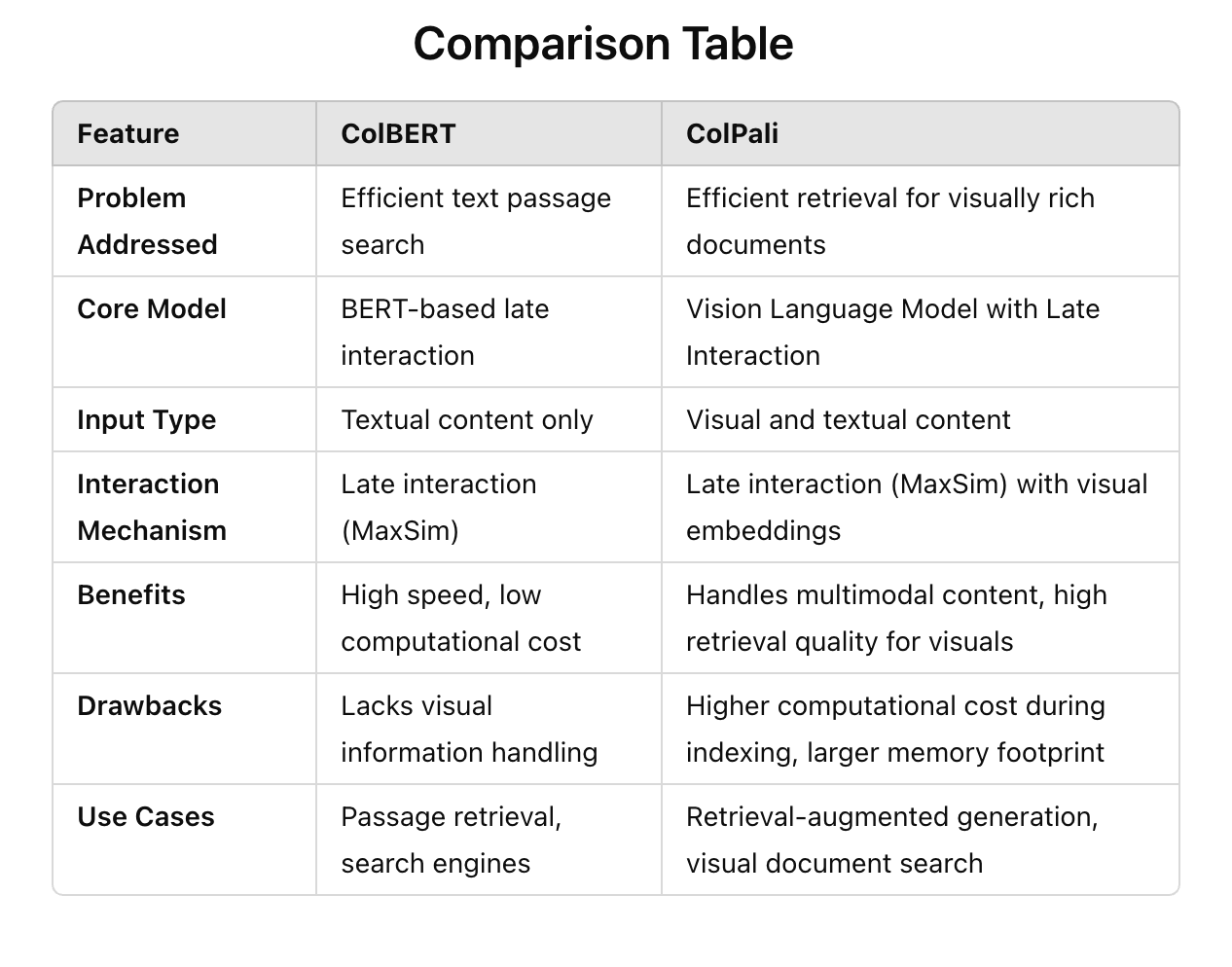
ColBERT and ColPali address different facets of document retrieval, focusing on improving efficiency and effectiveness. ColBERT seeks to enhance the effectiveness of passage search by leveraging deep pre-trained language models like BERT while maintaining a lower computational cost through late interaction techniques. Its main goal is to solve the computational challenges posed by conventional BERT-based ranking methods, which are costly in terms of time and resources. ColPali, on the other hand, aims to improve document retrieval for visually rich documents by addressing the limitations of standard text-based retrieval systems. ColPali focuses on overcoming the inefficiencies in utilizing visual information effectively, allowing the integration of visual and textual features for better retrieval in applications like Retrieval-Augmented Generation (RAG).
Key Elements
Key elements of ColBERT include the use of BERT for context encoding and a novel late interaction architecture. In ColBERT, queries and documents are independently encoded using BERT, and their interactions are computed using efficient mechanisms like MaxSim, allowing for better scalability without sacrificing effectiveness. ColPali incorporates Vision-Language Models (VLMs) to generate embeddings from document images. It utilizes a late interaction mechanism similar to ColBERT but extends it to multimodal inputs, making it particularly useful for visually rich documents. ColPali also introduces the Visual Document Retrieval Benchmark (ViDoRe), which evaluates systems on their ability to understand visual document features.
Technical Details, Benefits, and Drawbacks
ColBERT’s technical implementation includes the use of a late interaction approach where the query and document embeddings are generated separately and then matched using a MaxSim operation. This allows ColBERT to balance efficiency and computational cost by pre-computing document representations offline. The benefits of ColBERT include its high query-processing speed and reduced computational cost, which make it suitable for large-scale information retrieval tasks. However, it has limitations when dealing with documents that contain a lot of visual data, as it focuses solely on text.
ColPali, in contrast, leverages VLMs to generate contextualized embeddings directly from document images, thus incorporating visual features into the retrieval process. The benefits of ColPali include its ability to efficiently retrieve visually rich documents and perform well on multimodal tasks. However, the incorporation of vision models comes with additional computational overhead during indexing, and its memory footprint is larger compared to text-only methods like ColBERT due to the storage requirements for visual embeddings. The indexing process in ColPali is more time-consuming than ColBERT’s, although the retrieval phase remains efficient due to the late interaction mechanism.
Importance and Further Details
Both ColBERT and ColPali are important as they address key challenges in document retrieval for different types of content. ColBERT’s contribution lies in optimizing BERT-based models for efficient text-based retrieval, bridging the gap between effectiveness and computational efficiency. Its late interaction mechanism allows it to retain the benefits of contextualized representations while significantly reducing the cost per query. ColPali’s significance is in expanding the scope of document retrieval to visually rich documents, which are often neglected by standard text-based approaches. By integrating visual information, ColPali sets the foundation for future retrieval systems that can handle diverse document formats more effectively, supporting applications like RAG in practical, multimodal settings.
Conclusion
In conclusion, ColBERT and ColPali represent advancements in document retrieval by addressing specific challenges in efficiency, effectiveness, and multimodality. ColBERT offers a computationally efficient way to leverage BERT’s capabilities for passage retrieval, making it ideal for large-scale text-heavy retrieval tasks. ColPali, meanwhile, extends retrieval capabilities to include visual elements, enhancing the retrieval performance for visually rich documents and highlighting the importance of multimodal integration in practical applications. Both models have their strengths and limitations, but together, they illustrate the ongoing evolution of document retrieval to handle increasingly diverse and complex data sources.
Check out the Papers on ColBERT and ColPali. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post Comparative Analysis: ColBERT vs. ColPali appeared first on MarkTechPost.