
Transformer architecture has enabled large language models (LLMs) to perform complex natural language understanding and generation tasks. At the core of the Transformer is an attention mechanism designed to assign importance to various tokens within a sequence. However, this mechanism distributes attention unevenly, often allocating focus to irrelevant contexts. This phenomenon, known as “attention noise,” hinders the model’s ability to identify and utilize key information from lengthy sequences accurately. It becomes especially problematic in applications such as question answering, summarization, and in-context learning, where a clear and precise understanding of the context is critical.
One of the main challenges researchers face is ensuring that these models can correctly identify and focus on the most relevant segments of the text without being distracted by the surrounding context. This problem becomes more pronounced when scaling up the models regarding size and training tokens. The attention noise hampers the retrieval of key information and leads to issues such as hallucination, where models generate factually incorrect information or fail to follow logical coherence. As models grow larger, these problems become more challenging to address, making it crucial to develop new methods to eliminate or minimize attention noise.
Previous methods to tackle attention noise have included modifications to the architecture, training regimen, or normalization strategies. However, these solutions often have trade-offs regarding increased complexity or reduced model efficiency. For instance, some techniques rely on dynamic attention mechanisms that adjust focus based on context but struggle with maintaining consistent performance in long-context scenarios. Others incorporate advanced normalization strategies, but they add computational overhead and complexity. As a result, researchers have been looking for simpler yet effective ways to enhance the performance of LLMs without compromising on scalability or efficiency.
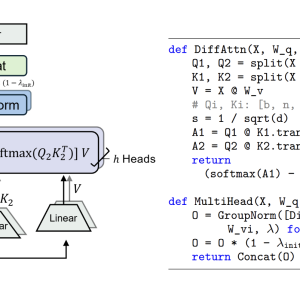
Microsoft Research and Tsinghua University researchers have introduced a new architecture called the Differential Transformer (DIFF Transformer). This novel architecture addresses the problem of attention noise by introducing a differential attention mechanism that effectively filters out irrelevant context while amplifying attention to meaningful segments. The differential attention mechanism operates by splitting the query and key vectors into two groups and computing two separate softmax attention maps. The difference between these maps serves as the final attention score, canceling common-mode noise and enabling the model to pivot more accurately on the intended information. This approach is inspired by concepts from electrical engineering, such as differential amplifiers, where common noise is canceled by taking the difference between two signals.
The DIFF Transformer consists of several layers containing a differential attention module and a feed-forward network. It retains the macrostructure of the original Transformer, ensuring compatibility with existing architectures while introducing innovations at the micro level. The model incorporates improvements like pre-RMSNorm and SwiGLU, borrowed from the LLaMA architecture, contributing to enhanced stability and efficiency during training.
The DIFF Transformer outperforms traditional Transformers in several key areas. For instance, it achieves comparable language modeling performance using only 65% of the model size and training tokens required by conventional Transformers. This translates into a 38% reduction in the number of parameters and a 36% decrease in the number of training tokens needed, directly resulting in a more resource-efficient model. When scaled up, a DIFF Transformer with 7.8 billion parameters achieves a language modeling loss similar to a 13.1 billion parameter Transformer, thereby matching performance while using 59.5% fewer parameters. This demonstrates the scalability of the DIFF Transformer, allowing for effective handling of large-scale NLP tasks with significantly lower computational costs.
In a series of tests, the DIFF Transformer demonstrated a remarkable capability for key information retrieval, outperforming the traditional Transformer by up to 76% in tasks where key information was embedded within the first half of a long context. In a “Needle-In-A-Haystack” experiment, where relevant answers were placed at varying positions within contexts of up to 64,000 tokens, the DIFF Transformer consistently maintained high accuracy, even when distractors were present. The traditional Transformer, in comparison, saw a steady decline in accuracy as the context length increased, highlighting the superior ability of the DIFF Transformer to maintain focus on relevant content.
The DIFF Transformer significantly reduced hallucination rates compared to conventional models. In a detailed evaluation using question-answering datasets such as Qasper, HotpotQA, and 2WikiMultihopQA, the DIFF Transformer achieved a 13% higher accuracy in single-document question answering and a 21% improvement in multi-document question answering. It achieved an average accuracy gain of 19% on text summarization tasks, effectively reducing the generation of factually incorrect or misleading summaries. These results underscore the robustness of the DIFF Transformer in diverse NLP applications.
The differential attention mechanism also improves the stability of the DIFF Transformer when dealing with context order permutations. At the same time, traditional Transformers exhibit high variance in performance when the order of context changes. The DIFF Transformer showed minimal performance fluctuation, indicating greater robustness to order sensitivity. In a comparative evaluation, the standard deviation of the DIFF Transformer’s accuracy across multiple-order permutations was less than 2%, while the traditional Transformer’s variance was over 10%. This stability makes the DIFF Transformer particularly suitable for applications involving in-context learning, where the model’s ability to utilize information from a changing context is crucial.


In conclusion, the DIFF Transformer introduces a groundbreaking approach to addressing attention noise in large language models. By implementing a differential attention mechanism, the model can achieve superior accuracy and robustness with fewer resources, positioning it as a promising solution for academic research and real-world applications.
Check out the Paper and Code Implementation. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post Differential Transformer: A Foundation Architecture for Large Language Models that Reduces Attention Noise and Achieves Significant Gains in Efficiency and Accuracy appeared first on MarkTechPost.