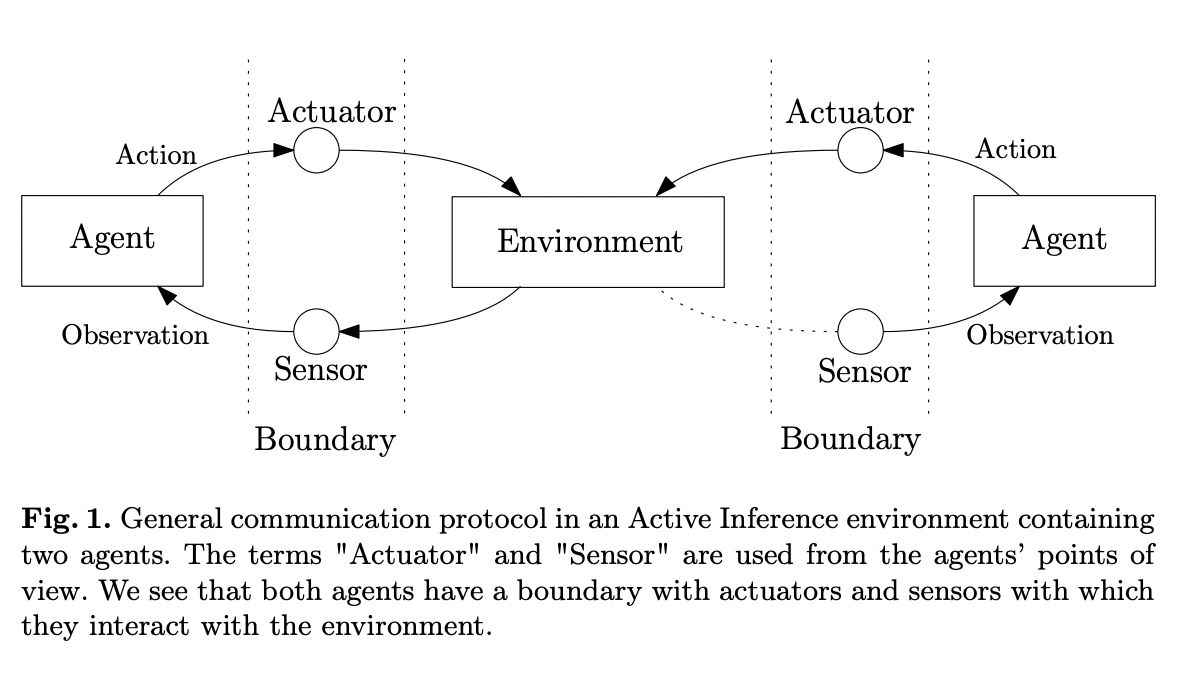

The Free Energy Principle (FEP) and its extension, Active Inference (AIF), present a unique approach to understanding self-organization in natural systems. These frameworks propose that agents use internal generative models to predict observations from unknown external processes, continuously updating their perceptive and control states to minimize prediction errors. While this unifying principle offers profound insights into agent-environment interactions, implementing it in practical scenarios poses significant challenges. Researchers require fine-grained control over agent-environment communication protocols, particularly when simulating proprioceptive feedback or multi-agent systems. Current solutions from reinforcement learning and control theory, such as Gymnasium, need more flexibility for these complex simulations. The imperative programming style employed in existing frameworks restricts communication between agents and environments to predefined parameters, limiting the exploration of diverse interaction scenarios essential for advancing FEP and AIF research.
Existing attempts to address the challenges in simulating agent-environment interactions have primarily focused on reinforcement learning frameworks. Gymnasium has emerged as a standard for creating and sharing control environments, offering a step function to define transition functions and handle environmental simulations. Similar alternatives include Deepmind Control Suite for Python and ReinforcementLearning.jl for Julia. These packages provide high-level interfaces to environments, simplifying timekeeping for users. While designed for reinforcement learning, they have been adapted for Active Inference research. Other packages like PyMDP and SPM-DEM toolbox incorporate environment realization but prioritize agent creation. However, the lack of a standardized approach for defining Active Inference environments has led to inconsistent implementations, with some researchers using Gymnasium and others opting for specialized toolboxes. Reactive Programming, similar to the Actor Model, offers a promising alternative by allowing computations on static datasets and real-time asynchronous sensor observations, aligning more closely with the principles of Active Inference.
Researchers from the Eindhoven University of Technology and GN Hearing present RxEnvironments.jl, a Julia package, introducing Reactive Environments as a robust approach to modeling agent-environment interactions. This implementation utilizes Reactive Programming principles to create efficient and flexible simulations. The package addresses the limitations of existing frameworks by offering a versatile platform for designing complex, multi-agent environments. By adopting a reactive programming style, RxEnvironments.jl enables researchers to model sophisticated systems with interacting agents more effectively. The package’s design facilitates the exploration of various scenarios, from simple single-agent simulations to intricate multi-agent ecosystems. Through several case studies, RxEnvironments.jl demonstrates its capability to handle diverse and complex environmental setups, showcasing its potential as a powerful tool for advancing research in Active Inference and related fields.
RxEnvironments.jl adopts a reactive programming approach to environment design, addressing the limitations of imperative frameworks. This approach enables multi-sensor, multimodal interactions between agents and environments without strict communication constraints. The package offers detailed control over observations, allowing different sensory channels to operate at varying frequencies or triggers based on specific actions. This flexibility enables the implementation of complex real-world scenarios with fine-grained control over an agent’s perceptions. RxEnvironments.jl natively supports multi-agent environments, allowing multiple instances of the same agent type to coexist without additional coding. The reactive programming style ensures efficient computation, with environments emitting observations when prompted and idling when unnecessary. In addition to that, the package extends beyond simple agent-environment frameworks, supporting multi-entity complex environments for more sophisticated simulations.
The Mountain Car environment, a classic reinforcement learning scenario, is implemented in RxEnvironments.jl with a unique twist. This implementation showcases the package’s ability to handle complex agent-environment interactions. When an agent applies an action, such as setting the engine throttle, the environment responds with an observation containing the actual engine force applied. This approach aligns with current theories on proprioceptive feedback in biological systems. The environment is designed to trigger different implementations of the what_to_send function based on input stimuli. For throttle actions, it returns the applied throttle action, while position and velocity measurements are emitted at a regular 2 Hz frequency, simulating sensor behavior. This setup demonstrates RxEnvironments.jl’s capability to manage distinct types of observations – sensory and proprioceptive feedback – each with its own logic for acquisition and transmission.
RxEnvironments.jl demonstrates its versatility through the implementation of a complex football match simulation. This multi-agent environment involves 22 players, showcasing the package’s ability to handle intricate, real-world scenarios. The simulation is structured with a single Entity representing the world state, containing the ball and references to all 22 player bodies, and 22 separate Entities for individual players. This design allows for realistic collision detection and on-ball actions. Players subscribe to the World Entity but not to each other, streamlining the subscription graph. Agent-to-agent communication is facilitated through the world Entity, which forwards signals between players. The environment distinguishes between global and local states, with the world Entity managing physical interactions and player Entities maintaining their local states and receiving observations from the global state. This setup enables asynchronous command execution for individual players, as demonstrated in a supplementary video. While the simulation focuses on running and on-ball actions rather than comprehensive football rules, it effectively illustrates RxEnvironments.jl’s capacity to model complex, multi-agent systems with individualized observations and interactions.
RxEnvironments.jl further demonstrates its flexibility by modeling a sophisticated hearing aid system that incorporates active inference-based agents for noise reduction. This complex scenario involves multiple interacting entities: the hearing aid itself, the external acoustic environment, the user (patient), and an intelligent agent on the user’s phone. The package adeptly handles the unique challenges of this multi-entity system, where the hearing aid must continuously communicate with three distinct sources. It processes acoustic signals from the outside world, receives feedback from the user about perceived performance, and interacts with the intelligent agent on the phone for advanced computations. This implementation showcases RxEnvironments.jl’s capability to model real-world systems with distributed processing and multiple communication channels, addressing the constraints of limited computing power and battery capacity in hearing aids. The package’s reactive programming approach enables efficient management of these complex, asynchronous interactions, making it an ideal tool for simulating and developing advanced hearing aid technologies.
This study presents Reactive Environments and their implementation in RxEnvironments.jl offering a versatile framework for modeling complex agent-environment interactions. This approach encompasses traditional reinforcement learning scenarios while enabling more sophisticated simulations, particularly for Active Inference. The case studies demonstrate the framework’s expressive power, accommodating diverse environmental setups from classic control problems to multi-agent systems and advanced hearing aid simulations. RxEnvironments.jl’s flexibility in handling complex communication protocols between agents and environments positions it as a valuable tool for researchers. Future work could explore agent classes that effectively utilize this communication protocol, further advancing the field of agent-environment simulations.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post RxEnvironments.jl: A Reactive Programming Approach to Complex Agent-Environment Simulations in the Julia Language appeared first on MarkTechPost.