Neural audio codecs have completely changed how audio is compressed and handled, by converting continuous audio signals into discrete tokens. This technique uses generative models trained on discrete tokens to produce complicated audio while maintaining the excellent quality of the audio. These neural codecs have significantly improved audio compression, making it possible to store and transfer audio data more effectively without compromising sound quality.
However, a lot of the neural audio codec models that are currently in use were not designed to distinguish between distinct sound domains. Instead, they were trained on sizable and varied audio datasets. For example, the harmonics and structure of spoken language are very different from those of music or ambient noise. The inability to distinguish between different audio domains makes it difficult to model data effectively and manage sound production. These models find it challenging to handle the distinctive qualities of various audio formats, which might result in less-than-ideal performance, particularly in applications that need exact control over sound production.
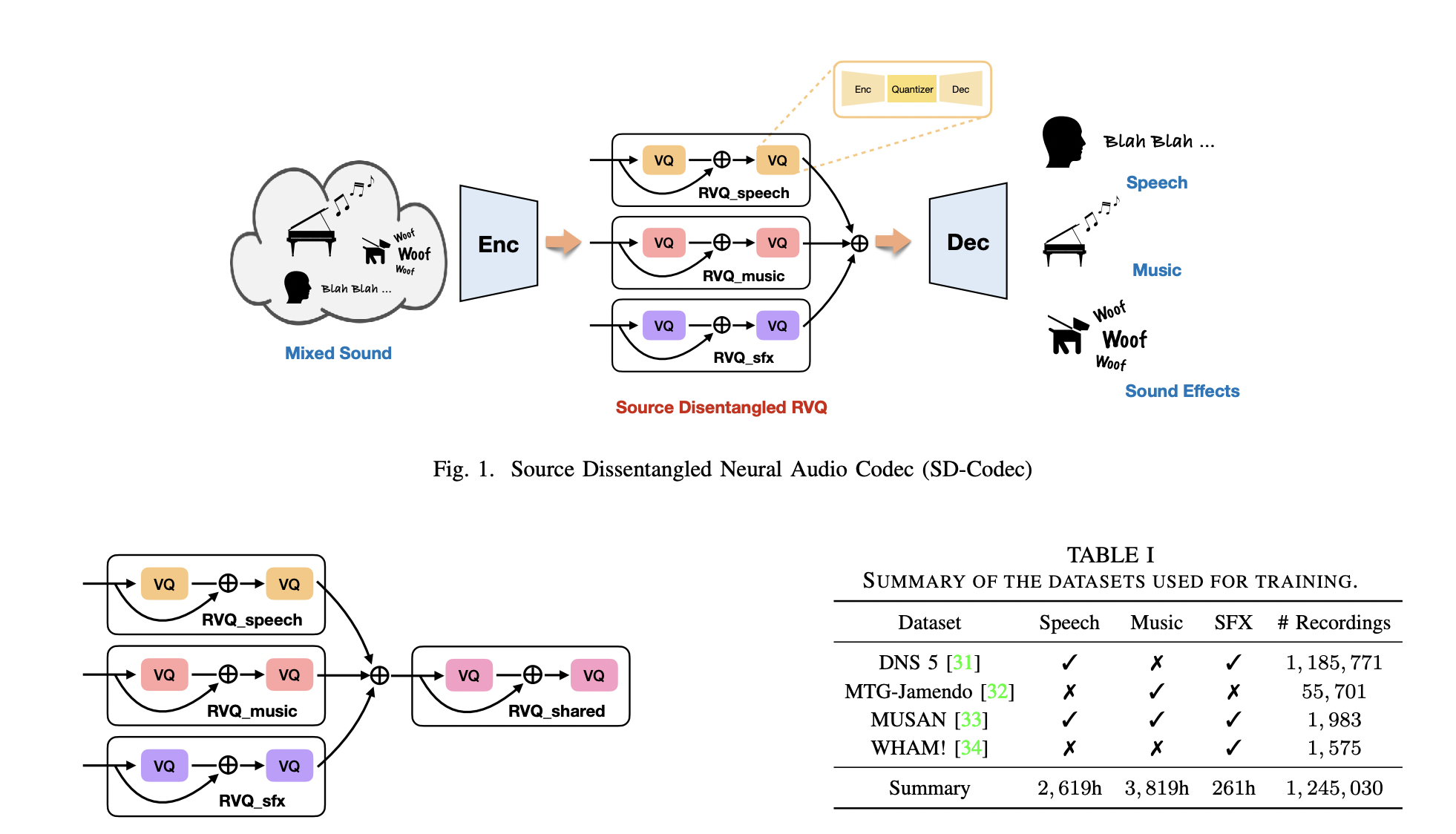
In order to overcome these issues, a team of researchers has introduced the Source-Disentangled Neural Audio Codec (SD-Codec), a unique technique that combines source separation and audio coding. The goal of SD-Codec is to enhance current neural codecs by specifically identifying and classifying audio signals into distinct domains. Unlike other latent space compression techniques, SD-Codec allocates discrete representations, or distinct codebooks, to various audio sources, including music, sound effects, and voice. Because of this division, the model is better able to recognize and maintain the distinctive qualities of each form of audio.
SD-Codec improves the interpretability of the latent space in neural audio codecs by simultaneously learning how to separate and resynthesize audio. In addition to helping to preserve high-quality audio resynthesis, it gives additional control over the audio creation process by making it easier to distinguish between various sources. Because SD-Codec can separate sources inside the latent space, it can manipulate the audio output more precisely, which is very useful for applications that need to generate or edit detailed audio.
Based on experimental results, SD-Codec successfully disentangles various audio sources and performs at a competitive level in terms of audio resynthesis quality. This separation capacity results in better interpretability, which makes it simpler to comprehend and manipulate the generated audio.
The team has summarized their primary contributions as follows.
- SD-Codec has been proposed, which is a neural audio codec that extracts distinct audio sources, such as speech, music, and sound effects from input audio clips in addition to reconstructing high-quality audio. This dual feature increases the codec’s adaptability and usefulness for a variety of audio processing applications.
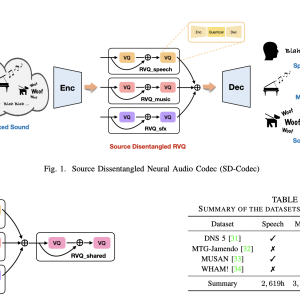
- It has been studied how the SD-Codec might make use of shared residual vector quantization (RVQ). The results have shown that the performance doesn’t change whether a common codebook is used or not. This highlights the hierarchical processing of audio input within the codec and implies that the shallow levels of RVQ are in charge of storing semantic information, while the deeper layers are concentrated on capturing local acoustic characteristics.
- A large-scale dataset has been used to train the SD-Codec, and the results have shown that it performs well in source separation and audio reconstruction. This extensive training ensures the model is reliable and functional in various acoustic situations.
In conclusion, SD-Codec is a major advancement in neural audio codecs, providing a more advanced and manageable method of audio production and compression.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Source-Disentangled Neural Audio Codec (SD-Codec): A Novel AI Approach that Combines Audio Coding and Source Separation appeared first on MarkTechPost.