
AI safety frameworks have emerged as crucial risk management policies for AI companies developing frontier AI systems. These frameworks aim to address catastrophic risks associated with AI, including potential threats from chemical or biological weapons, cyberattacks, and loss of control. The primary challenge lies in determining an “acceptable” level of risk, as there is currently no universal standard. Each AI developer must establish their threshold, creating a diverse landscape of safety approaches. This lack of standardization poses significant challenges in ensuring consistent and comprehensive risk management across the AI industry.
Existing research on AI safety frameworks is limited, given their recent emergence. Four main areas of scholarship have been developed: existing safety frameworks, recommendations for safety frameworks, reviews of existing frameworks, and evaluation criteria. Several leading AI companies, including Anthropic, OpenAI, Google DeepMind, and Magic, have published their safety frameworks. These frameworks, such as Anthropic’s Responsible Scaling Policy and OpenAI’s Preparedness Framework, represent the first concrete attempts to implement comprehensive risk management strategies for frontier AI systems.
Recommendations for safety frameworks have come from various sources, including organizations like METR and government bodies such as the UK Department for Science, Innovation and Technology. These recommendations outline key components and practices that should be incorporated into effective safety frameworks. Scholars have conducted reviews of existing frameworks, comparing and evaluating them against proposed guidelines and safety practices. However, evaluation criteria for these frameworks remain underdeveloped, with only one key source proposing specific criteria for assessing their robustness in addressing advanced AI risks.
Centre for the Governance of AI Researchers have tried to put weight on the development of effective evaluation criteria for AI safety frameworks, which is crucial for several reasons. Firstly, it helps identify shortcomings in existing frameworks, allowing companies to make necessary improvements as AI systems advance and pose greater risks. This process is analogous to peer review in scientific research, promoting continuous refinement and enhancement of safety standards. Secondly, a robust evaluation system can incentivize a “race to the top” among AI companies as they strive to achieve higher grades and be perceived as responsible industry leaders.
In addition to that, these evaluation skills may become essential for future regulatory requirements, preparing both companies and regulators for potential compliance assessments under various regulatory approaches. Lastly, public judgments on AI safety frameworks can inform and educate the general public, providing a much-needed external validation of companies’ safety claims. This transparency is particularly important in combating potential “safety washing” and helping the public understand the complex landscape of AI safety measures.
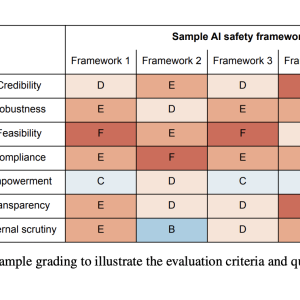
Researchers have proposed a robust method, introducing a comprehensive grading rubric for evaluating AI safety frameworks. This rubric is structured around three key categories: effectiveness, adherence, and assurance. These categories align with the outcomes outlined in the Frontier AI Safety commitments. Within each category, specific evaluation criteria and indicators are defined to provide a concrete basis for assessment. The rubric employs a grading scale ranging from A (gold standard) to F (substandard) for each criterion, allowing for a nuanced evaluation of different aspects of AI safety frameworks. This structured approach enables a thorough and systematic assessment of the quality and robustness of safety measures implemented by AI companies.
The proposed method for applying the grading rubric to AI safety frameworks involves three primary approaches: surveys, Delphi studies, and audits. For surveys, the process includes designing questions that evaluate each criterion on an A to F scale, distributing these to AI safety and governance experts, and analyzing the responses to determine average grades and key insights. This method offers a balance between resource efficiency and expert judgment.
Delphi studies represent a more comprehensive approach, involving multiple rounds of evaluation and discussion. Participants initially grade the frameworks and provide rationales, then engage in workshops to discuss aggregated responses. This iterative process allows for consensus-building and in-depth exploration of complex issues. While time-intensive, Delphi studies utilize collective expertise to produce nuanced assessments of AI safety frameworks.
Audits, though not detailed in the provided text, likely involve a more formal, structured evaluation process. The method recommends grading each evaluation criterion rather than individual indicators or overall categories, striking a balance between nuance and practicality in assessment. This approach enables a thorough examination of AI safety frameworks while maintaining a manageable evaluation process.
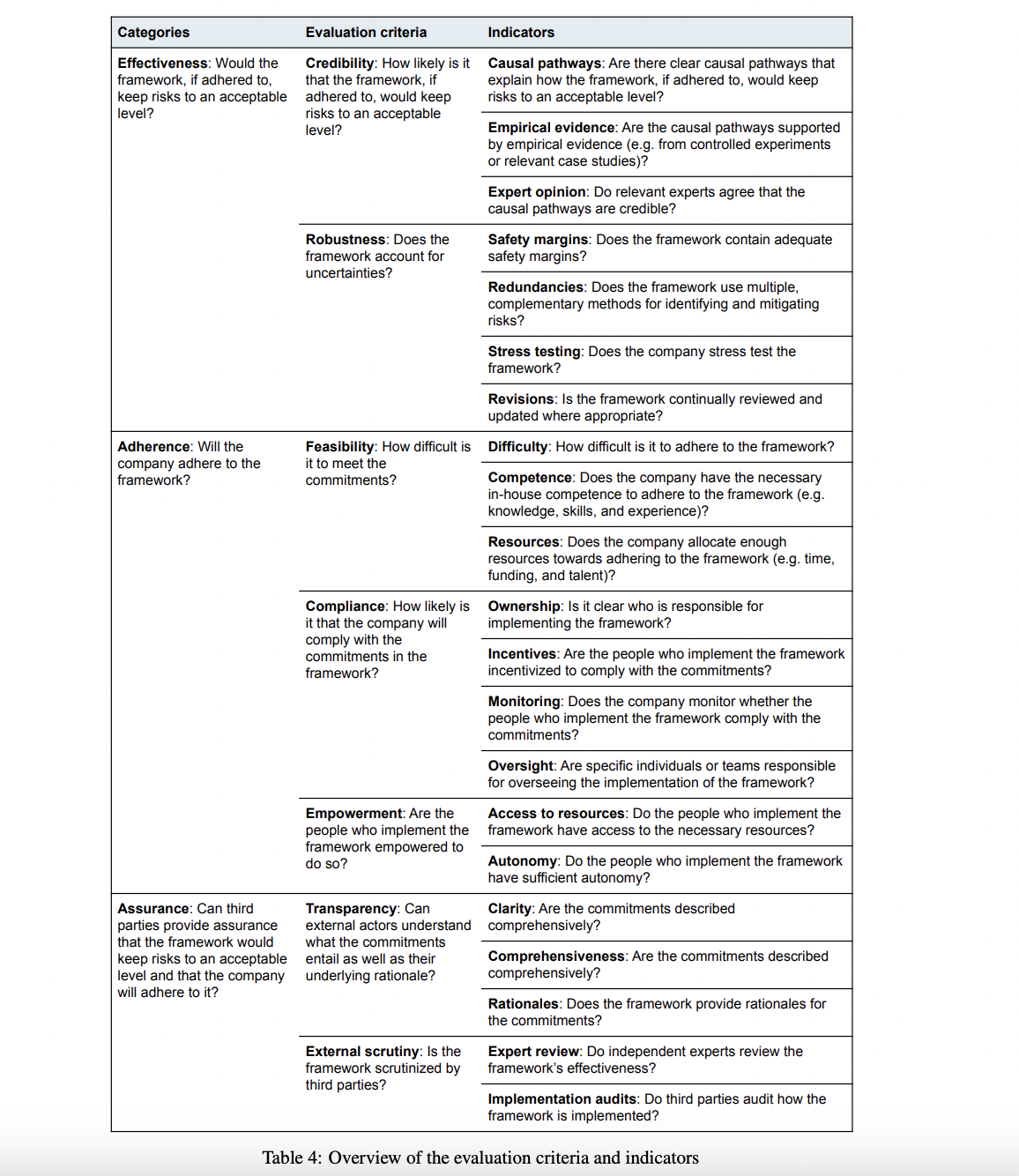
The proposed grading rubric for AI safety frameworks is designed to provide a comprehensive and nuanced evaluation across three key categories: effectiveness, adherence, and assurance. The effectiveness criteria, focusing on credibility and robustness, assess the framework’s potential to mitigate risks if properly implemented. Credibility is evaluated based on causal pathways, empirical evidence, and expert opinion, while robustness considers safety margins, redundancies, stress testing, and revision processes.
The adherence criteria examine feasibility, compliance, and empowerment, ensuring that the framework is realistic and likely to be followed. This includes assessing commitment difficulty, developer competence, resource allocation, ownership, incentives, monitoring, and oversight. The assurance criteria, covering transparency and external scrutiny, evaluate how well third parties can verify the framework’s effectiveness and adherence.
Key benefits of this evaluation method include:
1. Comprehensive assessment: The rubric covers multiple aspects of safety frameworks, providing a holistic evaluation.
2. Flexibility: The A to F grading scale allows for nuanced assessments of each criterion.
3. Transparency: Clear indicators for each criterion make the evaluation process more transparent and replicable.
4. Improvement guidance: The detailed criteria and indicators provide specific areas for framework improvement.
5. Stakeholder confidence: Rigorous evaluation enhances trust in AI companies’ safety measures.
This method enables a thorough, systematic assessment of AI safety frameworks, potentially driving improvements in safety standards across the industry.
The proposed grading rubric for AI safety frameworks, while comprehensive, has six major limitations:
1. Lack of actionable recommendations: The rubric effectively identifies areas for improvement but doesn’t provide specific guidance on how to enhance safety frameworks.
2. Subjectivity in measurement: Many criteria, such as robustness and feasibility, are abstract concepts that are difficult to measure objectively, leading to potential inconsistencies in grading.
3. Expertise requirement: Evaluators need specialized AI safety knowledge to assess certain criteria accurately, limiting the pool of qualified graders.
4. Potential incompleteness: The evaluation criteria may not be exhaustive, possibly overlooking critical factors in assessing safety frameworks due to the novelty of the field.
5. Difficulty in tier differentiation: The six-tier grading system may lead to challenges in distinguishing between quality levels, particularly in the middle tiers, potentially reducing the precision of assessments.
6. Equal weighting of criteria: The rubric doesn’t assign different weights to criteria based on their importance, which could lead to misleading overall assessments if readers intuitively aggregate scores.
These limitations highlight the challenges in creating a standardized evaluation method for the complex and evolving field of AI safety frameworks. They underscore the need for ongoing refinement of assessment tools and careful interpretation of grading results.
This paper introduces a robust grading rubric for evaluating AI safety frameworks, representing a significant contribution to the field of AI governance and safety. The proposed rubric comprises seven comprehensive grading criteria, each supported by 21 specific indicators to provide concrete assessment guidelines. This structure allows for a nuanced evaluation of AI safety frameworks on a scale from A (gold standard) to F (substandard).
The researchers emphasize the practical applicability of their work, encouraging its adoption by a wide range of stakeholders including governments, researchers, and civil society organizations. By providing this standardized evaluation tool, the authors aim to facilitate more consistent and thorough assessments of existing AI safety frameworks. This approach can potentially drive improvements in safety standards across the AI industry and foster greater accountability among AI companies.
The rubric’s design, balancing detailed criteria with flexibility in scoring, positions it as a valuable resource for ongoing efforts to enhance AI safety measures. By promoting the widespread use of this evaluation method, the researchers aim to contribute to the development of more robust, effective, and transparent AI safety practices in the rapidly evolving field of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post This AI Paper from Centre for the Governance of AI Proposes a Grading Rubric for AI Safety Frameworks appeared first on MarkTechPost.