
Optical Character Recognition (OCR) technology has been essential in digitizing and extracting data from text images. Over the years, OCR systems have evolved from simple methods that could recognize basic text to more complex systems capable of interpreting various characters. Traditional OCR systems, called OCR-1.0, use modular architectures to process images by detecting, cropping, and recognizing text. While these early systems served their purpose in certain areas, the growing demand for more intelligent text processing has exposed their limitations. OCR-1.0 systems, for instance, are often designed with specific tasks in mind, which means multiple models are needed to handle different OCR requirements, increasing complexity and maintenance costs.
One of the main challenges in the OCR field has been the inefficiency and need for more versatility of these traditional systems. OCR-1.0 models have high maintenance demands and struggle to generalize across different text types and formats, such as handwritten text, mathematical equations, or musical notation. Each task usually requires different OCR models to perform specific sub-tasks, which makes it difficult for users to find the right tool for a particular need. Current systems often require the integration of multiple models, which can lead to errors between the different processing steps. This fragmentation has led researchers to seek a more unified approach to OCR.
Recent advances in Large Vision-Language Models (LVLMs) have demonstrated impressive text recognition capabilities. For example, models like CLIP and LLaVA have shown that vision-language alignment can be used for OCR tasks. However, these models primarily focus on visual reasoning tasks and are not optimized for OCR-specific functions, especially when handling dense text or multiple languages. The large parameter sizes of these models, often exceeding billions of parameters, require significant computational resources for training and deployment. Moreover, current LVLMs need higher deployment costs, which makes them impractical for wide-scale adoption in OCR tasks, particularly in scenarios that involve high-density text or specialized optical characters like geometric shapes or musical scores.
Researchers from StepFun, Megvii Technology, the University of Chinese Academy of Sciences, and Tsinghua University introduced a new OCR model called GOT (General OCR Theory). This model is a key component of what the researchers describe as OCR-2.0, a next-generation approach to text recognition. GOT is designed to unify and simplify OCR tasks into a single, end-to-end solution. Unlike its predecessors, GOT aims to tackle all OCR requirements within one framework, offering a more versatile and efficient system. The model can recognize diverse text formats, including plain text, complex formulas, charts, and even geometric shapes. It has been designed to handle scene text and document-style images, making it applicable across various use cases.
The GOT model architecture comprises a high-compression encoder and a long-context decoder with 580 million parameters. The encoder compresses input images, whether small slices or full-page scans, into 256 tokens of 1,024 dimensions each, while the decoder, equipped with 8,000 maximum-length tokens, generates the corresponding OCR output. This combination allows GOT to process large and complex images efficiently and accurately. One of the standout features of the model is its ability to generate formatted outputs in Markdown or LaTeX, which is particularly useful for processing scientific papers and mathematical content. The model supports interactive OCR, enabling region-based recognition where users can specify regions of interest via coordinates or colors.
GOT delivers impressive performance across various OCR tasks. In experiments, the model outperformed competing models such as UReader and LLaVA-NeXT. For example, GOT achieved an F1-score of 0.952 for English document-level OCR, outperforming models with billions of parameters while using only 580 million parameters. Similarly, the Chinese document-level OCR recorded an F1 score of 0.961. In scene-text OCR tasks, GOT demonstrated remarkable precision and recall, achieving precision rates of 0.926 for English and 0.934 for Chinese, showing broad applicability across languages. The model’s ability to recognize complex characters, such as those found in sheet music or geometric shapes, was also notable, with the system performing well on tasks that involved rendering mathematical and molecular formulas.
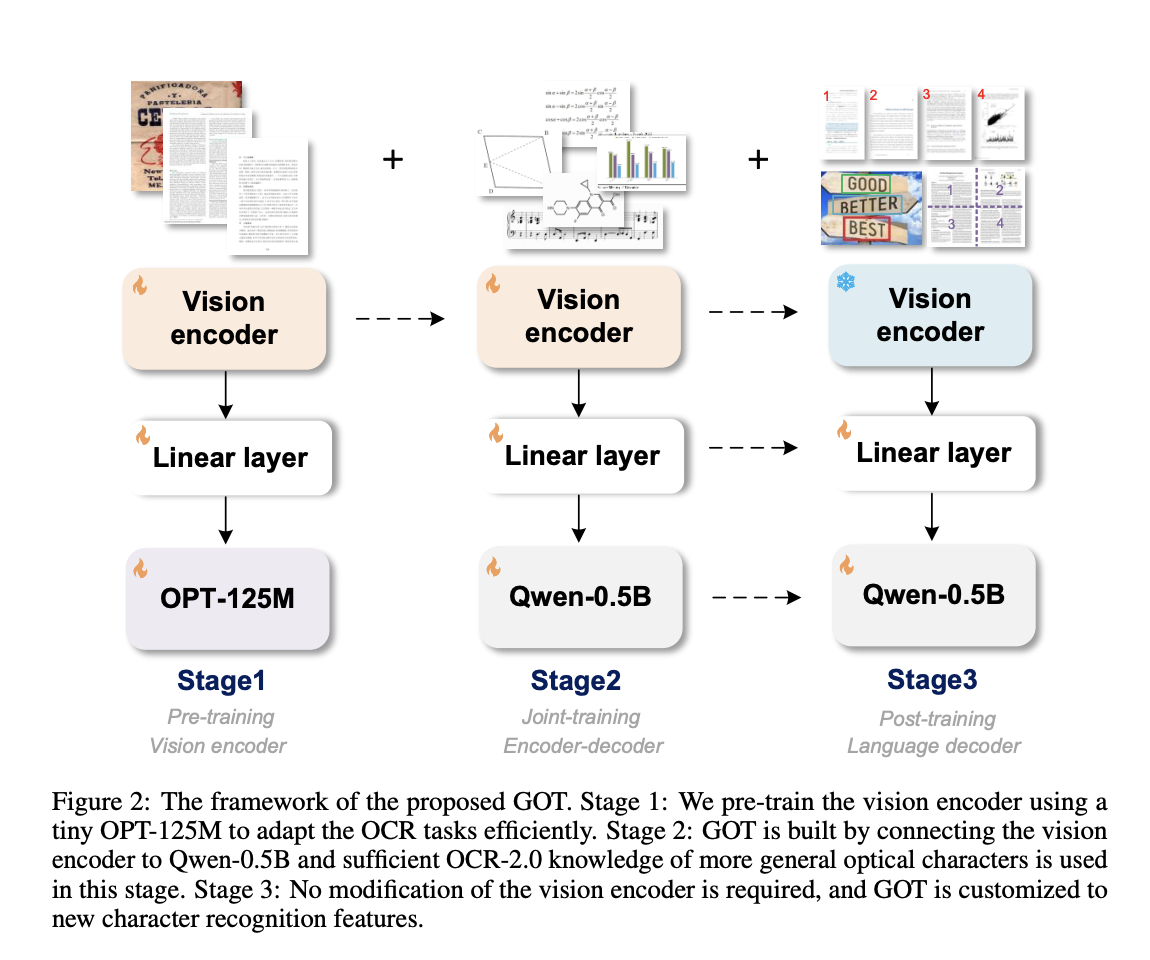
The researchers also incorporated dynamic resolution strategies and multi-page OCR technology into the GOT model, making it more practical for real-world applications where high-resolution images or multi-page documents are common. Using a sliding window approach, the model can process extreme-resolution images, like horizontally stitched two-page documents, without losing accuracy. The training of GOT was conducted in three stages: pre-training the vision encoder with 80 million parameters, joint training with the 580-million-parameter decoder, and post-training to enhance its generalization abilities further. Throughout these stages, the model was trained on various datasets, including 5 million image-text pairs, to ensure it could handle diverse OCR tasks. These datasets included text from English and Chinese sources and synthetic data representing mathematical formulas, tables, and more.

In conclusion, GOT, addressing the limitations of traditional OCR-1.0 models and the inefficiencies of current LVLM-based OCR methods, GOT introduces a unified, end-to-end system capable of handling a wide array of OCR tasks with high accuracy and lower computational costs. Its architecture, built on the General OCR Theory, enables it to efficiently process various text formats, from simple plain text to more complex optical characters like geometric shapes and molecular formulas. This model’s performance across different tasks, including scene-text and document OCR, demonstrates its potential to redefine the standard for OCR technology. Dynamic resolution and multi-page OCR capabilities further enhance its practicality in real-world applications.
Check out the Paper, Model, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post GOT (General OCR Theory) Unveiled: A Revolutionary OCR-2.0 Model That Streamlines Text Recognition Across Multiple Formats with Unmatched Efficiency and Precision appeared first on MarkTechPost.