
Reconstructing high-fidelity surfaces from multi-view images, especially with sparse inputs, is a critical challenge in computer vision. This task is essential for various applications, including autonomous driving, robotics, and virtual reality, where accurate 3D models are necessary for effective decision-making and interaction with real-world environments. However, achieving this level of detail and accuracy is difficult due to constraints in memory, computational resources, and the ability to capture intricate geometric information from limited data. Overcoming these challenges is vital for advancing AI technologies that demand both precision and efficiency, particularly in resource-constrained settings.
Current approaches for neural surface reconstruction are divided into multi-stage pipelines and end-to-end neural implicit methods. Multi-stage pipelines, like those used by SparseNeuS, involve separate stages for depth estimation, filtering, and meshing. These methods tend to accumulate errors across stages and are inefficient in optimizing coarse and fine stages together. End-to-end methods, such as those employing neural implicit functions, streamline the process by extracting geometry directly using techniques like Marching Cubes. However, these methods face significant memory limitations, particularly when working with high-resolution volumes, and they require a large number of input views to achieve satisfactory results. Additionally, view-dependent methods like C2F2NeuS, which construct separate cost volumes for each view, are computationally expensive and impractical for scenarios with numerous input views. These limitations hinder the application of these methods in real-time and resource-constrained environments.
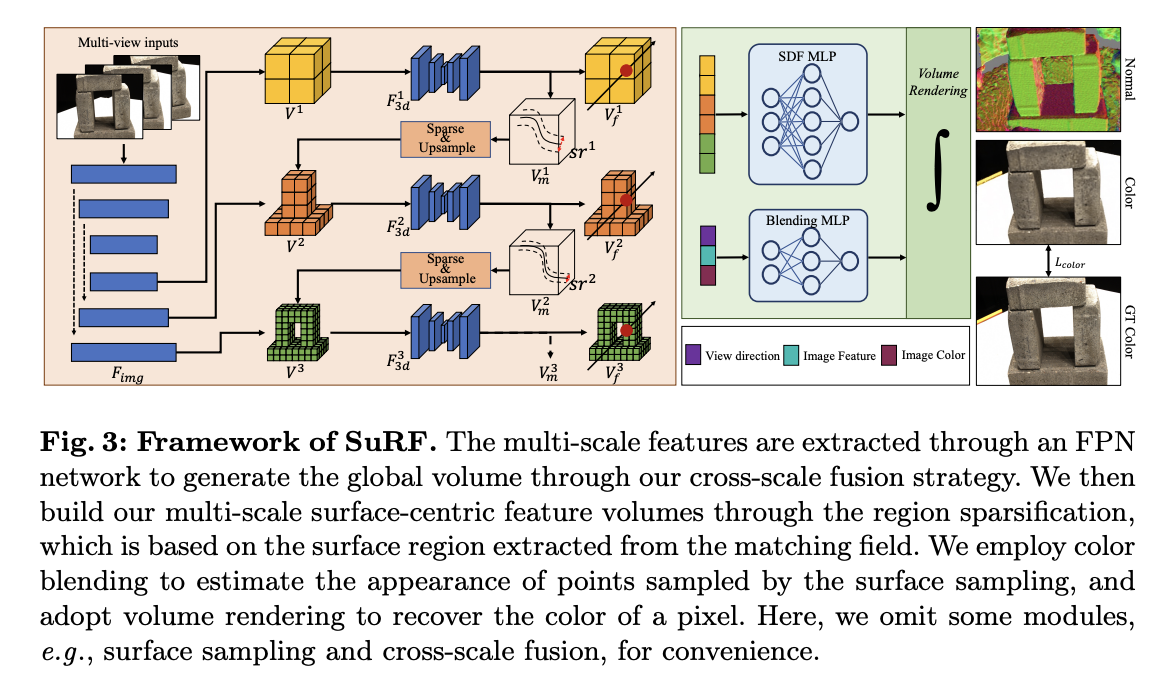
A team of researchers from Peking University, Peng Cheng Laboratory, University of Birmingham, and Alibaba propose SuRF, a novel surface-centric framework designed to overcome the limitations of existing methods by enabling efficient, high-resolution surface reconstruction from sparse input views. The innovation lies in SuRF’s end-to-end sparsification strategy, which is unsupervised and surface-centric, reducing memory consumption and computational load while enhancing the model’s ability to capture detailed geometric features. A key component of SuRF is the Matching Field module, which efficiently locates surface regions by leveraging weight distribution along rays, allowing the model to concentrate computational resources on regions near the surface. The Region Sparsification strategy further optimizes this process by retaining only the voxels within the identified surface regions, thus reducing the volume size and enabling the use of higher-resolution features. This approach provides a significant advancement in surface reconstruction by offering a scalable, efficient, and accurate solution, particularly in scenarios with limited input data.
SuRF is constructed using multi-scale feature volumes generated through a feature pyramid network (FPN) and an adaptive cross-scale fusion strategy. The model first extracts multi-scale features from the input images and aggregates them using a fusion network that integrates both global and local features. The Matching Field module identifies surface regions by creating a single-channel matching volume at each scale, which estimates the rough position of the surface along a ray, refined through region sparsification. This strategy ensures that only voxels within the surface regions are retained for higher-resolution scales, significantly reducing memory and computational demands. Training the model involves a combination of color loss, feature consistency loss, eikonal loss, and a warping loss from the matching field. The overall loss function is designed to optimize both the surface prediction and the matching field, allowing the model to efficiently locate and reconstruct high-fidelity surfaces even from sparse inputs.
SuRF demonstrates substantial improvements in accuracy and efficiency across multiple benchmarks, including DTU, BlendedMVS, Tanks and Temples, and ETH3D. Specifically, SuRF achieves a 46% improvement in accuracy while reducing memory consumption by 80% compared to previous methods. It consistently outperforms existing state-of-the-art approaches, achieving lower chamfer distances, which indicates finer and more detailed surface reconstructions. These results confirm that SuRF offers a more efficient and accurate solution for high-fidelity surface reconstruction, particularly when working with sparse input views, making it highly suitable for applications requiring both precision and resource efficiency.
SuRF introduces a significant advancement in neural surface reconstruction by providing a novel surface-centric approach that combines unsupervised end-to-end sparsification with efficient memory usage. Through the Matching Field and Region Sparsification strategies, SuRF directs computational resources toward high-resolution surface reconstruction, even with sparse input views. The experimental results validate SuRF’s effectiveness, highlighting its potential to set a new standard in high-fidelity surface reconstruction within AI research. This approach not only addresses a critical challenge in the field but also opens the door to more scalable and efficient AI systems suitable for deployment in resource-constrained environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post SuRF: An Unsupervised Surface-Centric Framework for High-Fidelity 3D Reconstruction with Region Sparsification appeared first on MarkTechPost.