In computer vision, backbone architectures are critical in image recognition, object detection, and semantic segmentation tasks. These backbones extract local and global features from images, enabling machines to understand complex patterns. Traditionally, convolutional layers have been the primary component in these models, but recent advancements incorporate attention mechanisms, which enhance the model’s ability to capture both local details and global contexts. Convolutions focus on regional information, while attention mechanisms enable a broader image understanding, leading to more accurate predictions. The challenge lies in optimizing these models for speed and accuracy, particularly when deploying them on hardware with limited resources, like mobile GPUs and ARM CPUs.
In vision models, improving computational efficiency while maintaining or improving accuracy is an ongoing problem. Many models use multiply-accumulate operations (MACs) to measure efficiency. However, this approach overlooks critical factors like memory access costs and the degree of parallelism, which significantly influence a model’s real-world performance. For instance, models with fewer MACs may still experience slow execution due to inefficient memory access, especially when handling larger datasets or working on devices with less computational power. To address this issue, modern models must consider actual execution times and throughput, not just theoretical efficiency metrics like MACs.
Several methods have emerged to address the efficiency-accuracy trade-off. Many existing models, such as MobileOne and EfficientViT, have made strides in reducing the number of MACs to improve efficiency, but this strategy has limitations. These models often need help with performance bottlenecks due to high memory access costs or suboptimal use of parallel processing capabilities. For example, while MobileOne-S2 has 15% lower GPU latency than previous models, it struggles to maintain high throughput when deployed on edge devices like ARM CPUs. Researchers have experimented with different architectural designs, such as depthwise convolutions and multi-branch networks, but these techniques do not always translate to faster real-world performance.
Researchers at the University of Udine, Italy, introduced a new family of hardware-efficient backbone networks called LowFormer to address these challenges. LowFormer integrates efficient convolutional operations and a modified multi-head self-attention mechanism (MHSA). The aim is to create a backbone that reduces MACs and improves throughput and latency on real hardware. LowFormer is designed to operate efficiently across various devices, including GPUs, mobile GPUs, and ARM CPUs, making it highly versatile for deployment in real-world applications. The researchers’ focus on actual execution time and throughput sets LowFormer apart from previous models, which typically prioritize theoretical metrics over practical performance.
LowFormer achieves its efficiency through a combination of design strategies. One of its key innovations is downscaling the input resolution for the attention mechanism. The model significantly reduces the computational load without sacrificing accuracy by operating on a lower resolution. This is particularly effective in the later stages of the network, where attention mechanisms typically process many channels. LowFormer also uses depthwise and pointwise convolutions around the scaled dot-product attention (SDA) mechanism to optimize performance further. This approach allows the model to maintain high accuracy while improving hardware efficiency, particularly in scenarios involving high-resolution images or complex visual tasks.
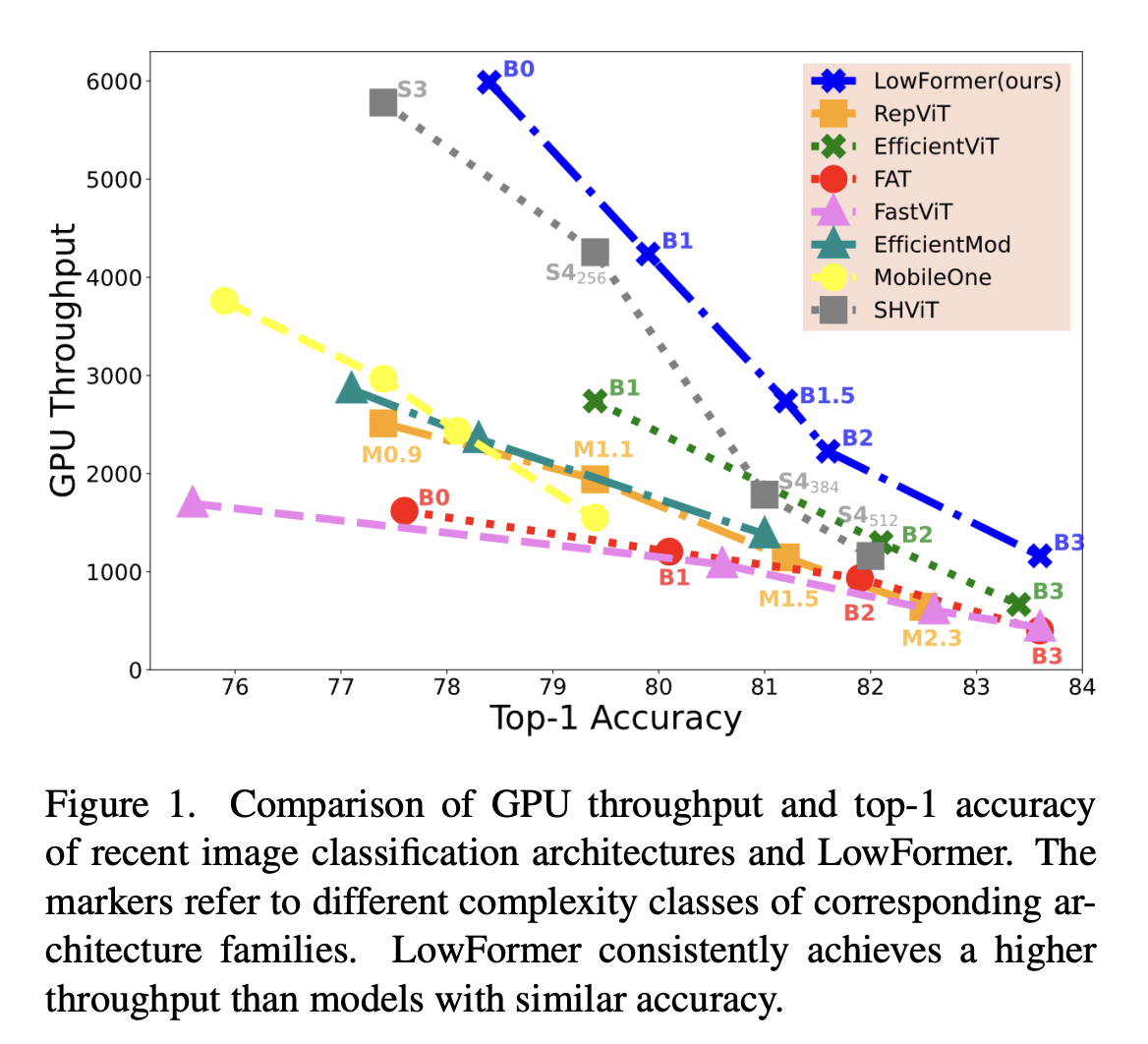
LowFormer demonstrates significant improvements in performance over existing models. The LowFormer-B0 variant, for example, achieves 2x the throughput of MobileOne-S2 while using 15% less latency on GPUs. The LowFormer-B3 model, which features the highest complexity, delivers almost 3x the GPU throughput of FAT-B3 while reducing GPU latency by 55%. These results are achieved without compromising accuracy; LowFormer-B3 achieves a top-1 accuracy of 83.64% on ImageNet-1K, outperforming other efficient backbones in its class. The model’s ability to generalize well to downstream tasks like object detection and semantic segmentation further proves its versatility. LowFormer-B1, for instance, delivers 1.7% better mean intersection-over-union (mIoU) than FastViT-SA12 while achieving 3x the throughput and 30% less latency on GPU.
LowFormer also shows promise in edge computing applications. Its hardware efficiency is validated across multiple platforms, including mobile GPUs and ARM CPUs. For example, LowFormer-B1 outperforms MobileOne-S4 by 0.5% in top-1 accuracy while achieving 32% lower mobile GPU latency and 59% lower ARM CPU latency. LowFormer is particularly suitable for deployment in resource-constrained environments where speed and accuracy are crucial. In object detection tasks, LowFormer-B2 improves average precision (AP) by +1.0 over FAT-B0 while offering 93% higher backbone throughput on a resolution of 512×512. These results demonstrate that LowFormer’s design effectively balances the demands of modern computer vision applications with the limitations of edge devices.

In conclusion, LowFormer addresses the key challenge of optimizing vision backbones for hardware efficiency without sacrificing accuracy. By focusing on actual execution metrics like throughput and latency rather than theoretical MACs, LowFormer delivers significant speed improvements on a range of devices. The model’s innovative combination of downsampled attention and convolutional layers enables it to outperform other state-of-the-art models, making it a valuable tool for high-performance and resource-constrained environments. With its impressive results in tasks like object detection and semantic segmentation, LowFormer sets a new standard for efficiency in computer vision backbones.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post LowFormer: A Highly Efficient Vision Backbone Model That Optimizes Throughput and Latency for Mobile and Edge Devices Without Sacrificing Accuracy appeared first on MarkTechPost.