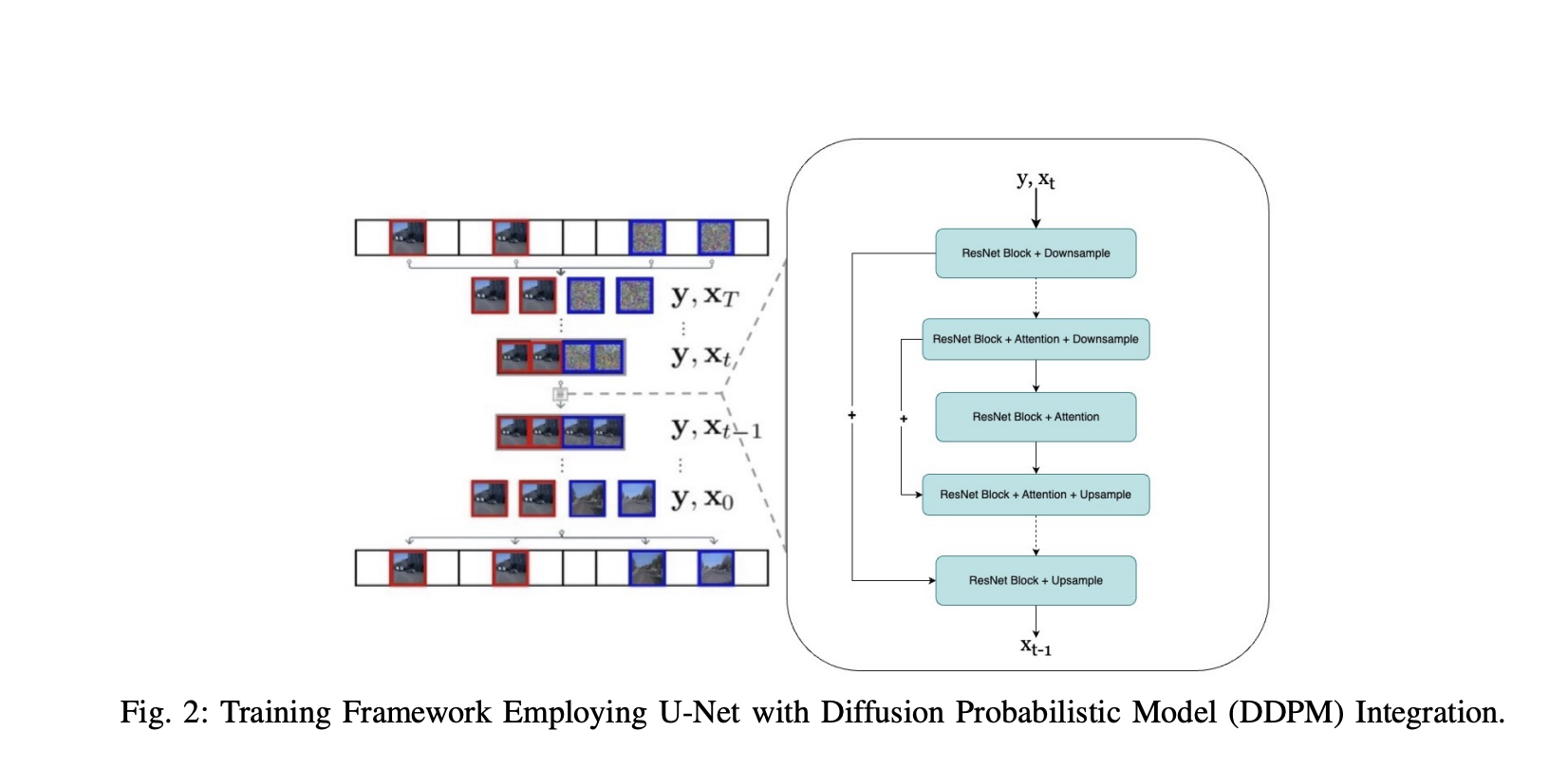
Integrating advanced predictive models into autonomous driving systems has become crucial for enhancing safety and efficiency. Camera-based video prediction emerges as a pivotal component, offering rich real-world data. Content generated by artificial intelligence is presently a leading area of study within the domains of computer vision and artificial intelligence. However, generating photo-realistic and coherent videos poses significant challenges due to limited memory and computation time. Moreover, predicting video from a front-facing camera is critical for advanced driver-assistance systems in autonomous vehicles.
Existing approaches include diffusion-based architectures that have become popular for generating images and videos, with better performance in tasks such as image generation, editing, and translation. Other methods like Generative Adversarial Networks (GANs), flow-based models, auto-regressive models, and Variational Autoencoders (VAEs) have also been used for video generation and prediction. Denoising Diffusion Probabilistic Models (DDPMs) outperform traditional generation models in effectiveness. However, generating long videos continues to be computationally demanding. Although autoregressive models like Phenaki tackle this issue, they often face challenges with unrealistic scene transitions and inconsistencies in longer sequences.
A team of researchers from Columbia University in New York have proposed the DriveGenVLM framework to generate driving videos and used Vision Language Models (VLMs) to understand them. The framework utilizes a video generation approach based on denoising diffusion probabilistic models (DDPM) to predict real-world video sequences. A pre-trained model called Efficient In-context Learning on Egocentric Videos (EILEV) is utilized to evaluate the adequacy of generated videos for VLMs. EILEV also provides narrations for these generated videos, potentially enhancing traffic scene understanding, aiding navigation, and improving planning capabilities in autonomous driving.
The DriveGenVLM framework is validated using the Waymo Open Dataset, which provides diverse real-world driving scenarios from multiple cities. The dataset is split into 108 videos for training and divided equally among the three cameras, and 30 videos for testing (10 per camera). This framework utilizes the Frechet Video Distance (FVD) metric to evaluate the quality of generated videos, where FVD measures the similarity between the distributions of generated and real videos. This metric is valuable for temporal coherence and visual quality evaluation, making it an effective tool for benchmarking video synthesis models in tasks such as video generation and future frame prediction.
The results for the DriveGenVLM framework on the Waymo Open Dataset for three cameras reveal that the adaptive hierarchy-2 sampling method outperforms other sampling schemes by yielding the lowest FVD scores. Prediction videos are generated for each camera using this superior sampling method, where each example is conditioned on the first 40 frames, with ground truth frames and predicted frames. Moreover, the flexible diffusion model’s training on the Waymo dataset shows its capacity for generating coherent and photorealistic videos. However, it still faces challenges in accurately interpreting complex real-world driving scenarios, such as navigating traffic and pedestrians.
In conclusion, researchers from Columbia University have introduced the DriveGenVLM framework to generate driving videos. The DDPM trained on the Waymo dataset is proficient while generating coherent and lifelike images from front and side cameras. Moreover, the pre-trained EILEV model is used to generate action narrations for the videos. The DriveGenVLM framework highlights the potential of integrating generative models and VLMs for autonomous driving tasks. In the future, the generated descriptions of driving scenarios can be used in large language models to offer driver assistance or support language model-based algorithms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post DriveGenVLM: Advancing Autonomous Driving with Generated Videos and Vision Language Models VLMs appeared first on MarkTechPost.