Machine learning models, especially those designed for code generation, heavily depend on high-quality data during pretraining. This field has seen rapid advancement, with large language models (LLMs) trained on extensive datasets containing code from various sources. The challenge for researchers is to ensure that the data used is abundant and of high quality, as this significantly impacts the model’s ability to handle complex tasks. In code-related applications, well-structured, annotated, and clean data ensures that models can generate accurate, efficient, and reliable outputs for real-world programming tasks.
A significant issue in code model development is the lack of precise definitions of “high-quality” data. While vast amounts of code data are available, much contains noise, redundancy, or irrelevant information, which can degrade model performance. Relying on raw data, even after filtering, often leads to inefficiencies. This problem becomes evident when models trained on large datasets underperform on practical benchmarks. To address this, there has been an increased focus on not just acquiring large amounts of data but curating data that aligns well with downstream applications, improving the model’s predictive abilities and overall utility.
Historically, the pretraining of code models involved scraping large repositories such as GitHub and processing raw data through basic filtering and deduplication techniques. Researchers would then apply random forest classifiers or simple quality filters to identify educationally valuable code, as seen in models like Phi-1. While these methods improved data quality to an extent, they were not enough to achieve optimal performance on more challenging coding tasks. Newer approaches have adopted more sophisticated tools, such as BERT-based annotators, to classify code quality and select data that would more effectively contribute to the model’s success.
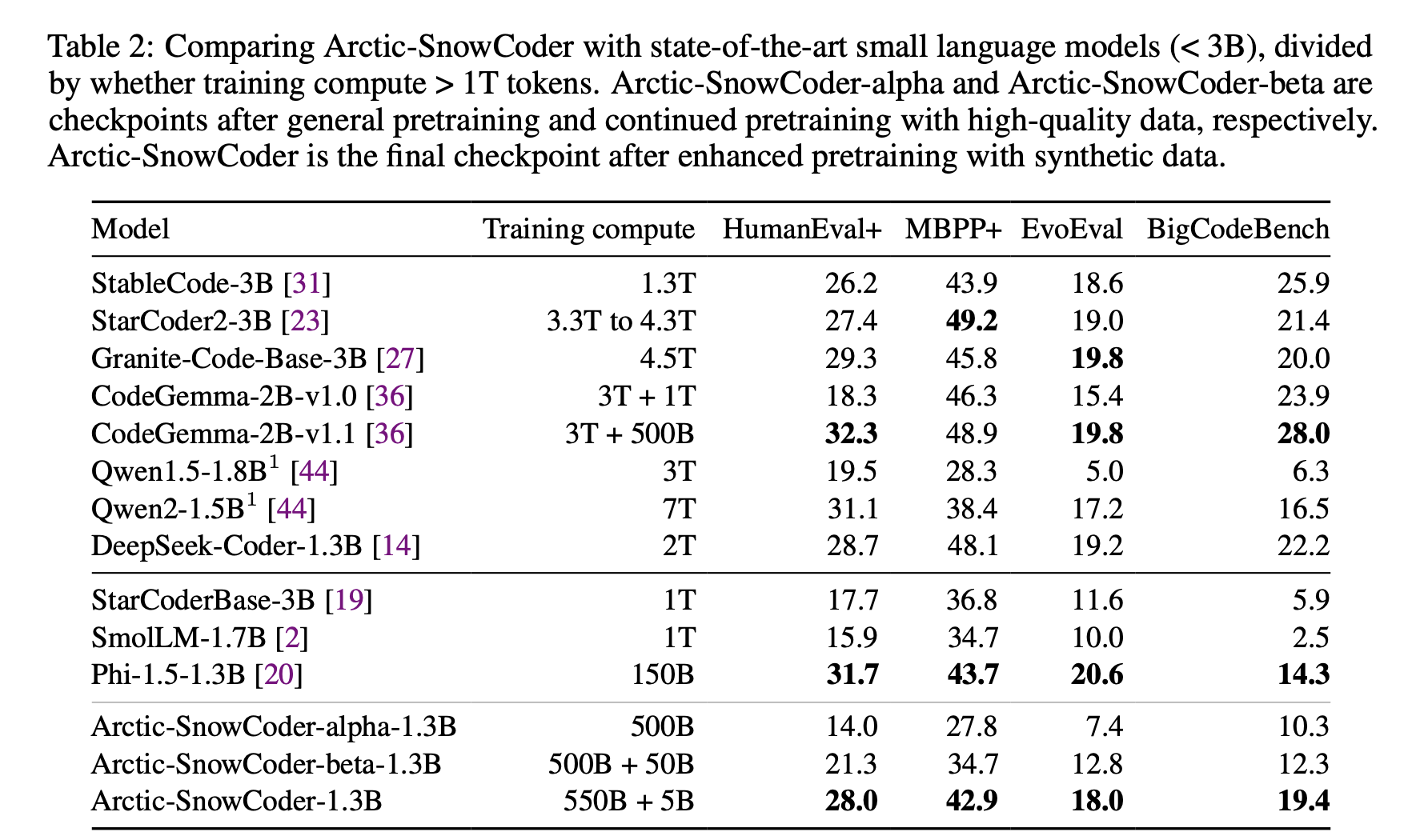
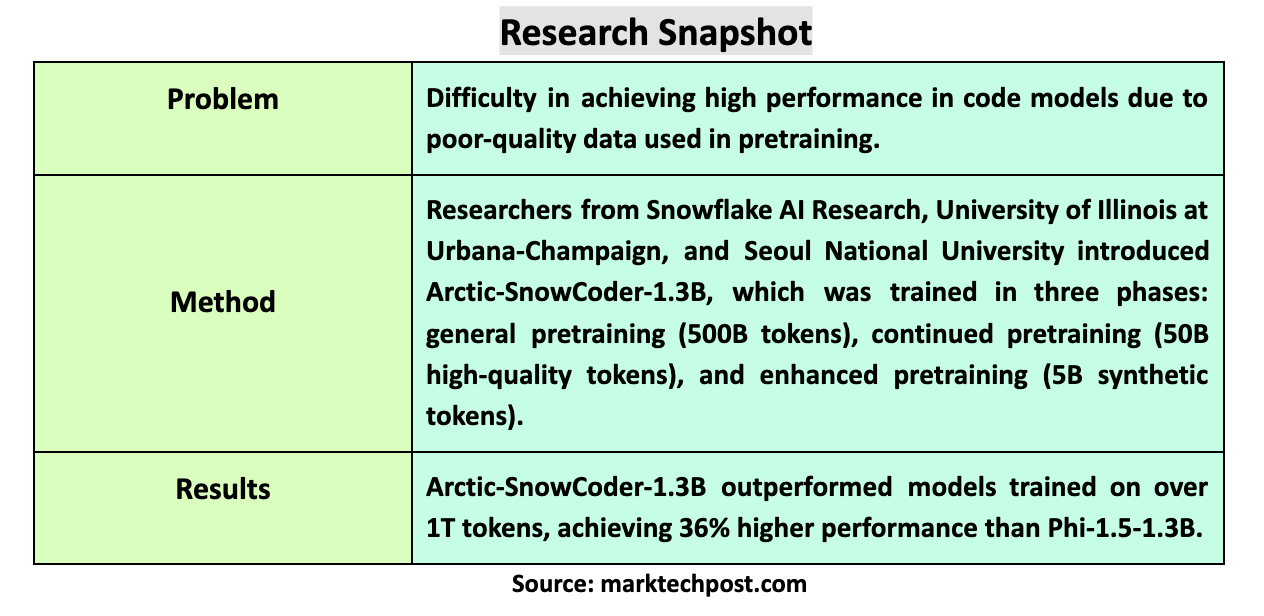
The research team from Snowflake AI Research, University of Illinois at Urbana-Champaign, and Seoul National University introduced Arctic-SnowCoder-1.3B, a novel approach to pretraining code models by progressively refining data quality over three distinct phases. This method combined general pretraining, continued pretraining with high-quality data, and final pretraining with synthetic data. The researchers leveraged existing datasets, such as The Stack v1 and GitHub crawls, and artificial data generated using Llama-3.1-70B to build a smaller, more efficient model. This process focused on optimizing the data used in each phase to ensure that the model could outperform its competitors.
In the first phase, Arctic-SnowCoder was trained on 500 billion code tokens derived from raw data sources such as The Stack v1 and GitHub. This data underwent basic preprocessing steps, including filtering and deduplication, resulting in approximately 400 billion unique tokens. During this phase, the model was trained without advanced quality filters, and the data was grouped by programming language and repository. This approach ensured a broad code knowledge base but required further refinement. In the second phase, the research team selected 50 billion tokens from this initial dataset, focusing on high-quality data. A BERT-based quality annotator was employed to rank code files, and the top 12.5 billion tokens were repeated four times to train the model further. This phase significantly improved the data quality, as the annotator was specifically trained to select tokens aligned with the model’s downstream applications.
The final phase involved enhanced pretraining with 5 billion synthetic tokens generated by Llama-3.1-70B. These tokens were created using the top-quality data from phase two as seeds, transforming lower-quality data into synthetic high-quality documents. This phase further refined the model’s ability to generate precise code by ensuring the training data was relevant and representative of real-world coding tasks. The result was a model that had undergone progressively more rigorous training, with each phase contributing to its enhanced performance.
The effectiveness of this approach is evident in Arctic-SnowCoder-1.3B’s results. Despite being trained on only 555 billion tokens, it significantly outperformed other models of similar size, such as Phi-1.5-1.3B and StarCoderBase-3B, which were trained on over 1 trillion tokens. On the BigCodeBench benchmark, which focuses on practical and challenging programming tasks, Arctic-SnowCoder exceeded the performance of Phi-1.5-1.3B by 36%. It surpassed StarCoder2-3B, trained on over 3 trillion tokens, on HumanEval+, achieving a score of 28.0 compared to StarCoder2-3B’s 27.4. Despite being trained on fewer tokens, the model’s ability to perform well highlights the importance of data quality over quantity.
In conclusion, Arctic-SnowCoder-1.3B illustrates the critical role of progressively refined, high-quality data in the pretraining of code models. By adopting a three-phase approach, the researchers enhanced the model’s performance significantly compared to larger models trained on far more tokens. This method demonstrates the importance of aligning pretraining data with downstream tasks and provides practical guidelines for future model development. Arctic-SnowCoder’s success is a testament to the value of high-quality data, showing that careful data curation and synthetic data generation can lead to substantial improvements in code generation models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Snowflake AI Research Introduces Arctic-SnowCoder-1.3B: A New 1.3B Model that is SOTA Among Small Language Models for Code appeared first on MarkTechPost.