
AI systems integrating natural language processing with database management can unlock significant value by enabling users to query custom data sources using natural language. Current methods like Text2SQL and Retrieval-Augmented Generation (RAG) are limited, handling only a subset of queries: Text2SQL addresses queries translatable to relational algebra, while RAG focuses on point lookups within databases. These methods often fall short for complex questions requiring domain knowledge, semantic reasoning, or world knowledge. Effective systems must combine the computational precision of databases with the language models’ reasoning capabilities, handling intricate queries beyond simple point lookups or relational operations.
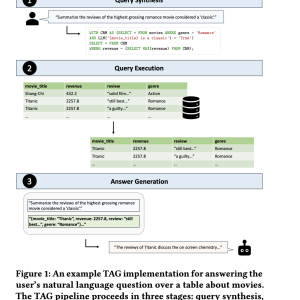
UC Berkeley and Stanford University researchers propose Table-Augmented Generation (TAG), a new paradigm for answering natural language questions over databases. TAG introduces a unified approach involving three steps: translating the user’s query into an executable database query (query synthesis), running this query to retrieve relevant data (query execution), and using this data along with the query to generate a natural language answer (answer generation). Unlike Text2SQL and RAG, which are limited to specific cases, TAG addresses a broader range of queries. Initial benchmarks show that existing methods achieve less than 20% accuracy, while TAG implementations can improve performance by 20-65%, highlighting its potential.
Text2SQL research, including datasets like WikiSQL, Spider, and BIRD, focuses on converting natural language queries into SQL but does not address queries requiring additional reasoning or knowledge. RAG enhances language models by leveraging external text collections, with models like dense table retrieval (DTR) and join-aware table retrieval extending RAG to tabular data. However, TAG expands beyond these methods by integrating language model capabilities into query execution and database operations for exact computations. Prior research on semi-structured data and agentic data assistants explores related concepts, but TAG aims to leverage a broader range of language model capabilities for diverse query types.
The TAG model answers natural language queries by following three main steps: query synthesis, query execution, and answer generation. First, it translates the user’s query into a database query (query synthesis). Then, it executes this query to retrieve relevant data from the database (query execution). Finally, it uses the retrieved data and the original query to generate a natural language answer (answer generation). TAG extends beyond traditional methods like Text2SQL and RAG by incorporating complex reasoning and knowledge integration. It supports various query types, data models, and execution engines and explores iterative and recursive generation patterns for enhanced query answering.
In evaluating the TAG model, a benchmark was created using modified queries from the BIRD dataset to test semantic reasoning and world knowledge. The benchmark included 80 queries, split evenly between those requiring world knowledge and reasoning. The hand-written TAG model consistently outperformed other methods, achieving up to 55% accuracy overall and demonstrating superior performance on comparison queries. Other baselines, including Text2SQL, RAG, and Retrieval + LM Rank, struggled, especially with reasoning queries, showing lower accuracy and higher execution times. The hand-written TAG model also achieved the fastest execution time and provided thorough answers, particularly in aggregation queries.
In conclusion, The TAG model was introduced as a unified approach for answering natural language questions using databases. Benchmarks were developed to assess queries requiring world knowledge and semantic reasoning, revealing that existing methods like Text2SQL and RAG fall short, achieving less than 20% accuracy. In contrast, hand-written TAG pipelines demonstrated up to 65% accuracy, highlighting the potential for significant advancements in integrating LMs with data management systems. TAG offers a broader scope for handling diverse queries, underscoring the need for further research to explore its capabilities and improve performance fully.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
The post Table-Augmented Generation (TAG): A Unified Approach for Enhancing Natural Language Querying over Databases appeared first on MarkTechPost.