
Zyphra has announced the release of Zamba2-mini 1.2B, a cutting-edge small language model designed specifically for on-device applications. This new model represents a landmark achievement in AI, combining state-of-the-art performance with remarkable efficiency, all within a compact memory footprint. The release of Zamba2-mini is poised to transform the landscape of on-device AI, offering developers and researchers a powerful tool for creating more responsive, efficient, and capable applications.
State-of-the-Art Performance in a Compact Package
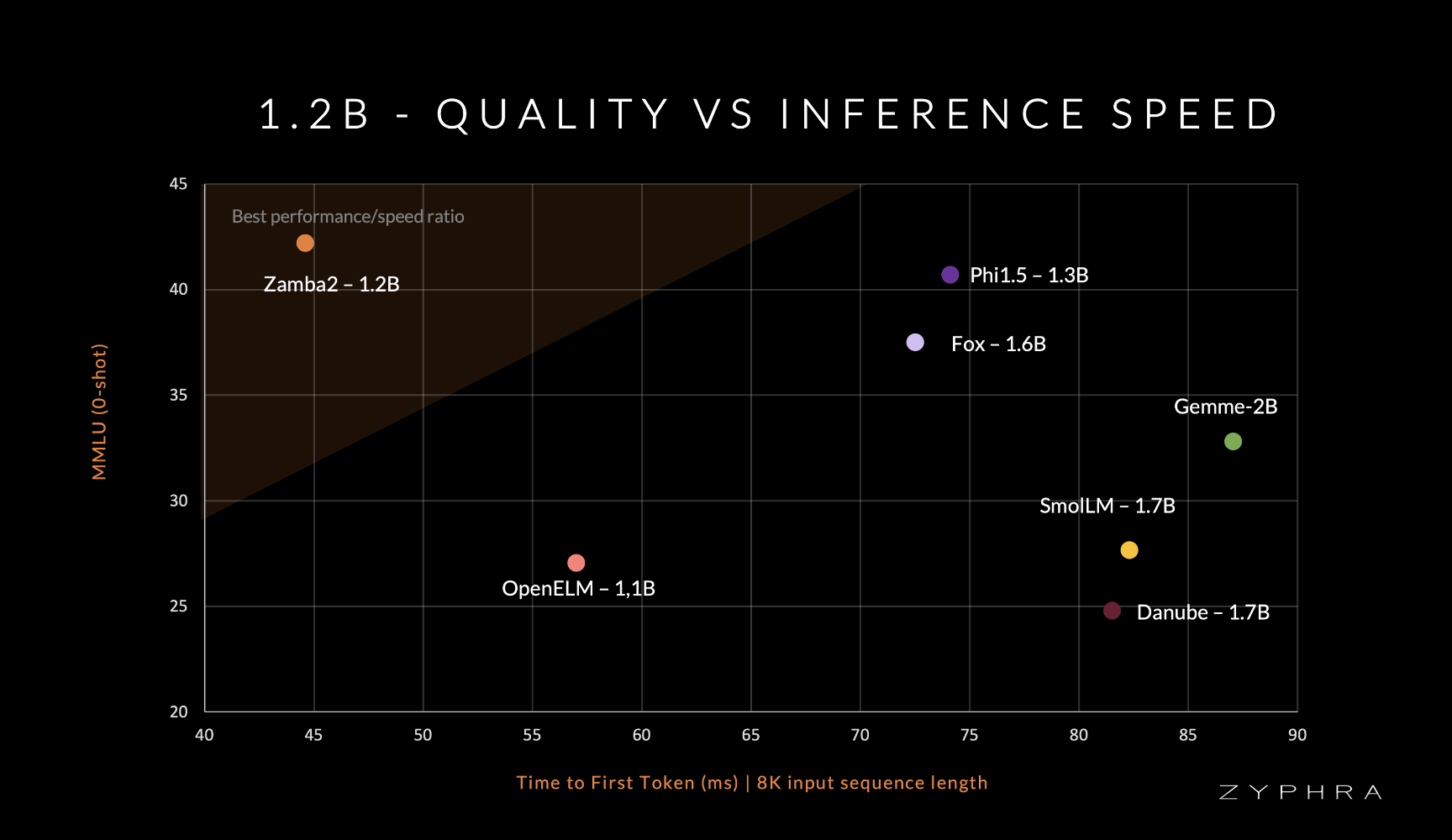
Zamba2-mini is the latest addition to Zyphra’s innovative Zamba series, which has been at the forefront of small language model development. Despite its modest size, Zamba2-mini achieves performance benchmarks that rival much larger models, including industry heavyweights like Google’s Gemma-2B, Huggingface’s SmolLM-1.7B, Apple’s OpenELM-1.1B, and Microsoft’s Phi-1.5. Zamba2-mini’s superior performance is particularly notable in inference tasks, where it outpaces its competitors with a 2x faster time-to-first-token, a 27% reduction in memory overhead, and a 1.29x lower generation latency compared to models like Phi3-3.8B.
This efficiency is achieved through a highly optimized architecture that blends the strengths of different neural network designs. Specifically, Zamba2-mini employs a hybrid architecture incorporating transformer and Recurrent Neural Network (RNN) elements. This combination allows Zamba2-mini to maintain the high-quality output typically associated with larger dense transformers while operating with a much smaller model’s computational and memory efficiency. Such efficiency makes Zamba2-mini an ideal solution for on-device AI applications where resources are limited, but high performance is still required.
Innovative Architectural Design
The architectural innovations behind Zamba2-mini are key to its success. At its core, Zamba2-mini utilizes a backbone of Mamba2 layers interleaved with shared attention layers. This design allows the model to allocate more parameters to its core operations while minimizing the parameter cost through shared attention blocks. These blocks are further enhanced by incorporating LoRA projection matrices, which provide additional expressivity and specialization to each layer without significantly increasing the model’s overall parameter count.
One of the critical advancements in Zamba2-mini over its predecessor, Zamba1, is the integration of two shared attention layers instead of one, as seen in the original Zamba architecture. This dual-layer approach enhances the model’s ability to maintain information across its depth, improving overall performance. Including Rotary Position embeddings in the shared attention layers has slightly boosted performance, demonstrating Zyphra’s commitment to incremental yet impactful improvements in model design.
The model’s training regimen also plays a significant role in its capabilities. Zamba2-mini was pretrained on a massive dataset of three trillion tokens from a combination of Zyda and other publicly available sources. This extensive dataset was rigorously filtered and deduplicated to ensure the highest quality training data, which was further refined during an “annealing” phase that involved training on 100 billion tokens of exceptionally high quality. This careful curation and training process has endowed Zamba2-mini with a level of performance and efficiency unmatched by other models of similar size.
Open Source Availability and Future Prospects
Zyphra has committed to making Zamba2-mini an open-source model under the Apache 2.0 license. This move aligns with the company’s broader mission to provide access to advanced AI technologies and foster innovation across the industry. By releasing Zamba2-mini’s model weights and integrating with platforms like Huggingface, Zyphra enables many developers, researchers, and companies to leverage the model’s capabilities in their projects.
The open-source release of Zamba2-mini is expected to spur further research and development in efficient language models. Zyphra has already established itself as a leader in exploring novel AI architectures, and the release of Zamba2-mini reinforces its position at the cutting edge of the industry. The company is eager to collaborate with the broader AI community, inviting others to explore Zamba’s unique architecture and contribute to advancing efficient foundation models.
Conclusion
Zyphra’s Zamba2-mini represents a significant milestone in developing small language models, particularly for on-device applications where efficiency and performance are paramount. With its state-of-the-art architecture, rigorous training process, and open-source availability, Zamba2-mini is poised to become a key tool for developers and researchers looking to push what is possible with on-device AI.
Check out the Model Card and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
The post Zyphra Unveils Zamba2-mini: A State-of-the-Art Small Language Model Redefining On-Device AI with Unmatched Efficiency and Performance appeared first on MarkTechPost.