
The main focus of existing Multimodal Large Language Models (MLLMs) is on individual image interpretation, which restricts their ability to tackle tasks involving many images. These challenges demand models to comprehend and integrate information across several images, including Knowledge-Based Visual Question Answering (VQA), Visual Relation Inference, and Multi-image Reasoning. The majority of current MLLMs struggle with these scenarios because of their architecture, which is mostly centered around single-image processing, even though the requirement for such skills in real applications is expanding.
In recent research, a team of researchers has presented MaVEn, a multi-granularity visual encoding framework designed to improve the performance of MLLMs in tasks requiring reasoning across numerous images. The primary purpose of traditional MLLMs is to comprehend and handle individual photos, which limits their capacity to efficiently handle and combine data from several images at once. MaVEn uses a unique strategy that blends two different kinds of visual representations to overcome these obstacles, which are as follows.
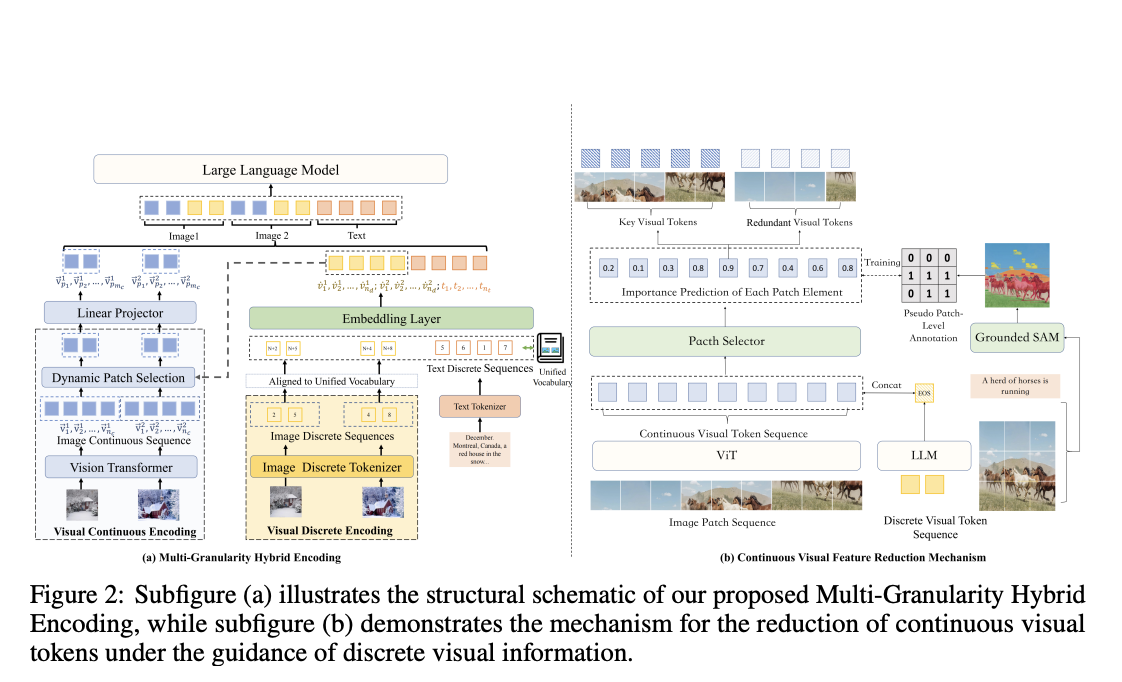
- Discrete Visual Symbol Sequences: These patterns extract semantic concepts with a coarse texture from images. MaVEn streamlines the representation of high-level concepts by abstracting the visual information into discrete symbols, which facilitates the model’s alignment and integration of this information with textual data.
- Sequences for Continuous Representation: These sequences are used to simulate the fine-grained characteristics of images, retaining the specific visual details that could be missed in a representation that is only discrete. This makes sure the model can still access the subtle information required for defensible interpretation and logic.
MaVEn bridges the gap between textual and visual data by combining these two methods, improving the model’s capacity to comprehend and process information from various images coherently. This dual encoding approach preserves the model’s effectiveness in tasks involving a single image while simultaneously enhancing its performance in multi-image circumstances.
MaVEn also presents a dynamic reduction method that is intended to manage lengthy continuous feature sequences that may occur in multi-image scenarios. By optimizing the model’s processing efficiency, this method lowers computational complexity without sacrificing the caliber of the visual data being encoded.
The experiments have demonstrated that MaVEn considerably improves MLLM performance in difficult situations requiring multi-image reasoning. Additionally, it illustrates how the framework improves the models’ performance in single-image tasks, which makes it a flexible answer for a variety of visual processing applications.
The team has summarized their primary contributions as follows.
- A unique framework that combines continuous and discrete visual representations has been suggested. This combination greatly improves MLLMs capability to process and comprehend complicated visual information from numerous images, as well as their ability to reason across several images.
- To address long-sequence continuous visual aspects, the study creates a dynamic reduction mechanism. Through the optimization of multi-image processing efficiency, this method minimizes computational overhead in ML models without sacrificing accuracy.
- The method performs exceptionally well in a range of multi-image reasoning scenarios. It also offers benefits in common single-image benchmarks, demonstrating its adaptability and efficiency in various visual processing applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Unlock the power of your Snowflake data with LLMs’
The post MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Models (MLLMs) appeared first on MarkTechPost.