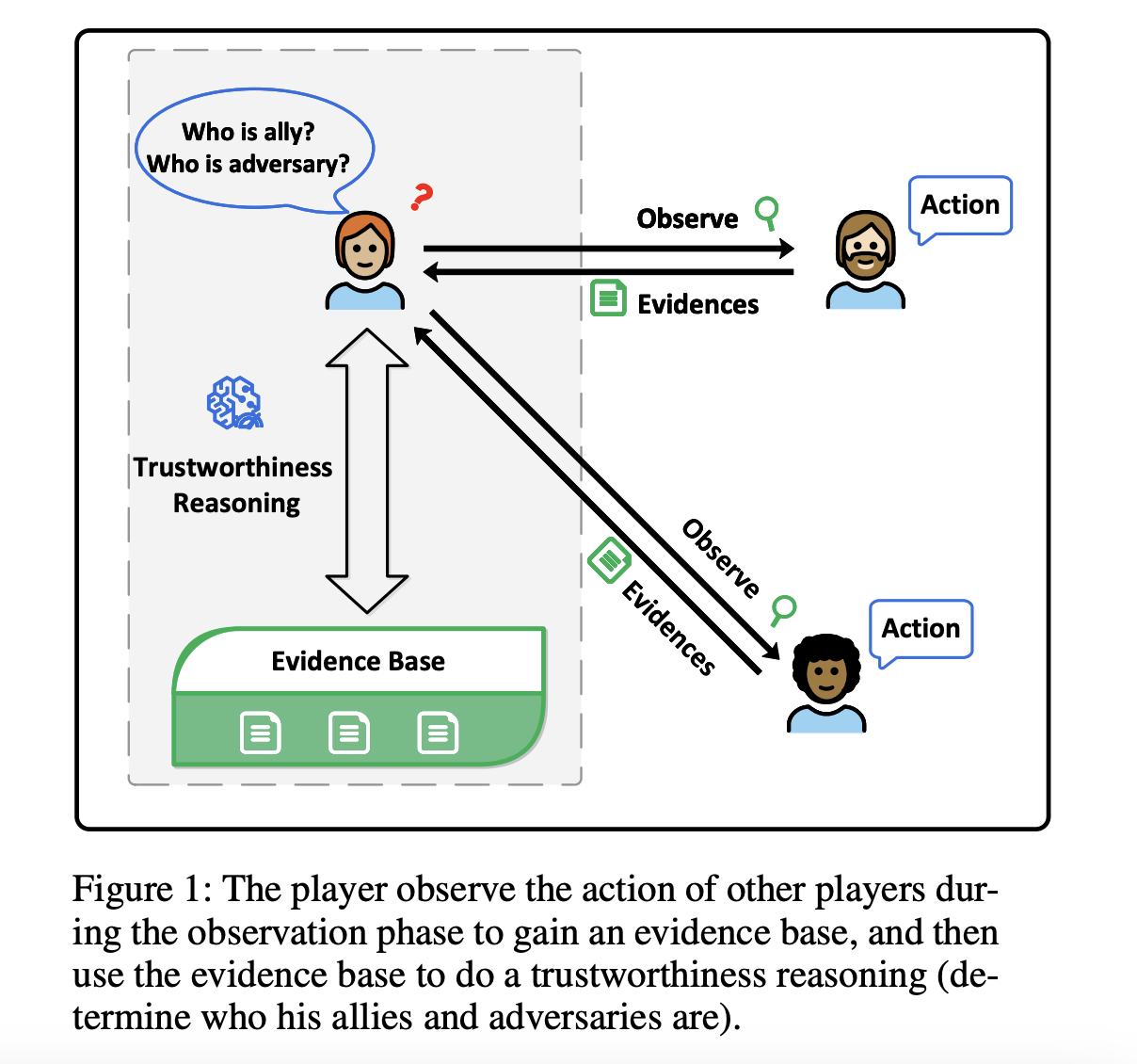

Trustworthiness reasoning in multiplayer games with incomplete information presents significant challenges. Players need to assess the reliability of others based on partial, often misleading information while making decisions in real time. Traditional approaches, heavily reliant on pre-trained models, struggle to adapt to dynamic environments due to their dependence on domain-specific data and feedback rewards. These limitations result in a lack of real-time adaptability, which is essential for effective decision-making in rapidly evolving scenarios. Addressing these challenges is critical for advancing AI’s application in complex environments, particularly in contexts where real-time trust assessment is crucial, such as in autonomous systems and strategic games.
Current methods for trustworthiness reasoning in such environments include symbolic reasoning, Bayesian reasoning, and reinforcement learning (RL). Symbolic reasoning focuses on coherence and consistency in models but often lacks flexibility in dynamic settings. Bayesian reasoning, while effective in updating beliefs based on evidence, requires significant computational resources and is prone to inaccuracies when dealing with limited or noisy data. RL, although powerful in decision-making, demands vast amounts of domain-specific training data, making it unsuitable for real-time applications. These methods generally struggle with computational complexity, limited data efficiency, and the inability to handle dynamic, real-time environments effectively.
The researchers from Nanjing University of Information Science and Technology and Hangzhou Dianzi University introduce the Graph Retrieval Augmented Trustworthiness Reasoning (GRATR) framework, a novel approach leveraging Retrieval-Augmented Generation (RAG) to enhance trustworthiness reasoning. GRATR constructs a dynamic trustworthiness graph that updates in real time, integrating evidential information as it becomes available. This graph-based method addresses the limitations of static data handling by existing RAG models, enabling the system to adapt to the evolving nature of interactions and trust relationships in real time. GRATR enhances reasoning by retrieving and integrating the most relevant trust data from the graph, improving decision-making, and reducing hallucinations in Large Language Models (LLMs). This approach represents a significant advancement by providing a more accurate and efficient solution for real-time trustworthiness reasoning.
The GRATR framework initializes with a dynamic evidence graph, where nodes represent players, and edges represent trust relationships. The graph is updated continuously as new observations are made, with evidence lists attached to edges and trustworthiness values attached to nodes. Key components include the evidence merging phase, where evidence is aggregated and evaluated, and the forward retrieval phase, where trustworthiness values are updated based on retrieved evidence chains. GRATR was validated using the multiplayer game “Werewolf,” with experiments comparing its performance against baseline LLMs and LLMs enhanced with Native RAG and Rerank RAG. The dataset used for these experiments consisted of 50 game iterations with eight players, including various roles such as werewolves, villagers, and leaders (witch, guard, and seer).
GRATR significantly outperforms baseline methods in terms of win rate and reasoning accuracy. For instance, GRATR achieved a total win rate of 76.0% in one experiment group, compared to 24.0% for the baseline LLM. Similarly, the win rate for the werewolf role was 72.4% with GRATR, compared to 27.6% for the baseline. GRATR consistently outperformed both Native RAG and Rerank RAG across various metrics, including total win rate, werewolf win rate, and leader win rate. For instance, in one comparison, GRATR achieved a total win rate of 83.7%, and the win rate for the werewolf role was 83.5%, which is significantly higher than the performance of LLM enhanced with Rerank RAG.
GRATR presents a significant advancement in trustworthiness reasoning for multiplayer games with incomplete information. By leveraging a dynamic graph structure that updates in real-time, GRATR addresses the limitations of existing methods, offering a more accurate and efficient solution for real-time decision-making. The experimental results highlight GRATR’s superior performance, particularly in enhancing the reasoning capabilities of LLMs while mitigating issues such as hallucinations. This contribution is poised to have a substantial impact on AI research, particularly in areas requiring robust real-time trust assessment, such as autonomous systems and strategic game environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Unlock the power of your Snowflake data with LLMs’
The post Achieving Superior Game Strategies: This AI Paper Unveils GRATR, a Game-Changing Approach in Trustworthiness Reasoning appeared first on MarkTechPost.