
LLMs are increasingly used in healthcare for tasks like question answering and document summarization, performing on par with domain experts. However, their effectiveness in traditional biomedical tasks, such as structured information extraction, remains to be seen. While LLMs have successfully generated free-text outputs, current approaches mainly focus on enhancing the models’ internal knowledge through methods like fine-tuning and in-context learning. These methods depend on readily available data, often insufficient in the biomedical domain due to domain shifts and the lack of resources for specific structured tasks, making zero-shot performance critical yet underexplored.
Researchers from several institutions, including ASUS Intelligent Cloud Services, Imperial College London, and the University of Manchester, conducted a study to benchmark the performance of LLMs in medical classification and Named Entity Recognition (NER) tasks. They aimed to analyze how different factors, such as task-specific reasoning, domain knowledge, and the addition of external expertise, influence LLM performance. Their findings revealed that standard prompting outperformed more complex techniques like Chain-of-Thought (CoT) reasoning and Retrieval-Augmented Generation (RAG). The study highlights the challenges of applying advanced prompting methods in biomedical tasks and emphasizes better integrating external knowledge in LLMs for real-world applications.
The existing literature on benchmarking LLMs in the medical domain primarily focuses on tasks like Question Answering, summarization, and clinical coding, often neglecting structured prediction tasks such as document classification and Named Entity Recognition. While previous work has provided valuable resources for traditionally structured tasks, many benchmarks overlook these in favor of evaluating domain-specific models. Recent approaches to enhance LLM performance include domain-specific pretraining, instruction tuning, CoT reasoning, and RAG. However, these methods often need more systematic evaluation in the context of structured prediction, which the study aims to address.
To assess LLM performance on structured prediction tasks, the study benchmark a range of models on biomedical text classification and NER tasks in a true zero-shot setting. This approach evaluates the models’ inherent parametric knowledge, which is crucial due to the scarcity of annotated biomedical data. We compare this baseline performance with enhancements from CoT reasoning, RAG, and Self-Consistency methods while keeping the parametric knowledge constant. Techniques are evaluated using a variety of datasets, including both English and non-English sources, and the models are constrained to ensure structured output.
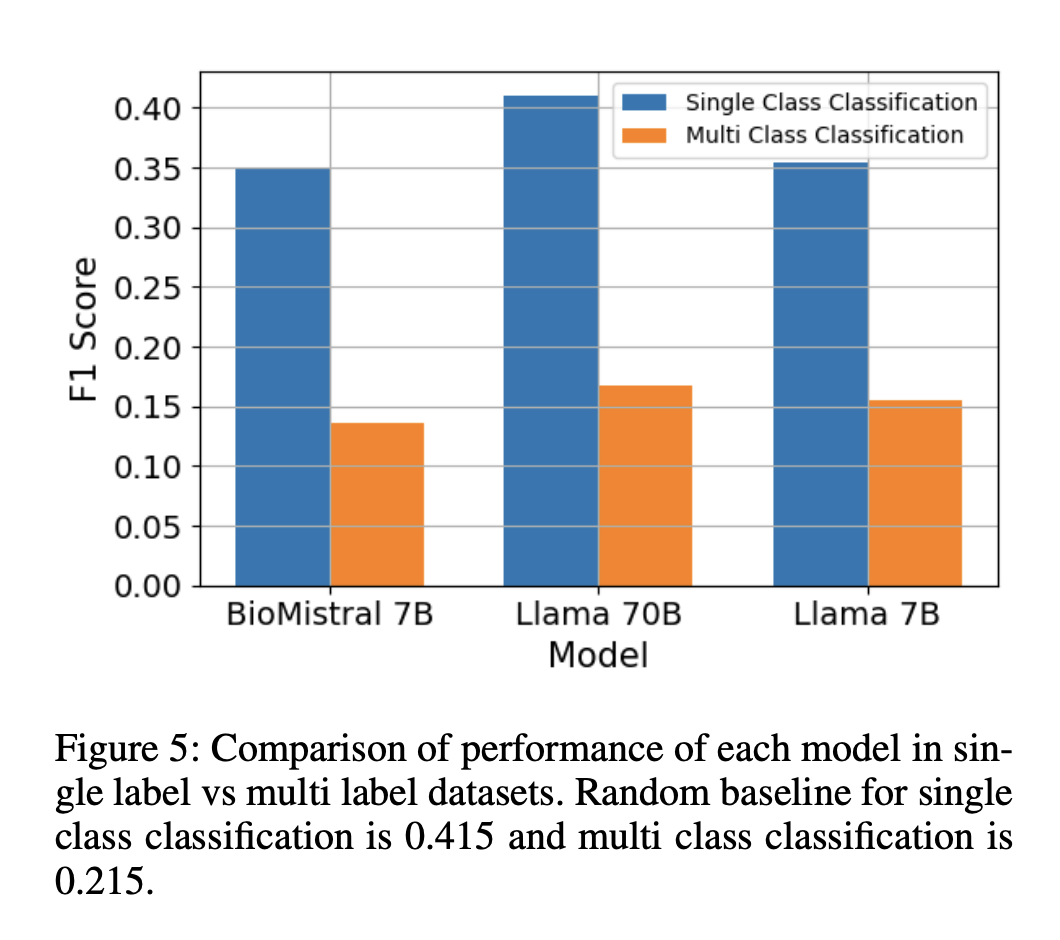
The evaluation results reveal that reasoning and knowledge enhancement techniques generally do not boost performance. Standard Prompting consistently yields the highest F1 scores for classification tasks across all models, with BioMistral-7B, Llama-2-70B, and Llama-2-7B scoring 36.48%, 40.34%, and 34.92%, respectively. Complex methods like CoT Prompting and RAG must often perform better than Standard Prompting. Larger models, such as Llama-2-70B, significantly improve, especially in tasks requiring advanced reasoning. However, multilingual and private datasets show lower performance, and high-complexity tasks still need to be improved, with RAG techniques showing inconsistent benefits.
The study benchmarks LLMs in Medical Classification and NER, revealing significant insights. Despite the advanced techniques like CoT and RAG, Standard Prompting consistently outperforms these methods across tasks. This underscores a fundamental limitation in LLMs’ generalizability and effectiveness in structured biomedical information extraction. The results highlight that current advanced prompting methods must translate better to biomedical tasks, emphasizing the need to integrate domain-specific knowledge and reasoning capabilities to enhance LLM performance in real-world healthcare applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Benchmarking Large Language Models in Biomedical Classification and Named Entity Recognition: Evaluating the Impact of Prompting Techniques and Domain Knowledge appeared first on MarkTechPost.