
Artificial intelligence (AI) planning involves creating a sequence of actions to achieve a specific goal in the development of autonomous systems that perform complex tasks, such as robotics and logistics. Furthermore, large language models (LLMs) have shown great promise in several areas focused on natural language processing and code generation. Nevertheless, if one has to generate a complete plan, applying LLMs for AI planning raises some challenges—one case arises when one has to create not just sound but complete plans. Soundness ensures that a plan is valid and leads toward a goal, and completeness ensures that all the possible solutions are considered. The main challenge within this domain is balancing flexibility and time spent, accuracy and feasibility, reliability, and the abundance or vagueness of information.
The problem mainly solved by this research is the problem of bringing soundness and completeness into the picture of AI planning when LLMs are being worked with. This usually involves methods that are far more scalable and effective than the traditional approach of collecting feedback and having human experts guide the planning phase. The problem comes in automating this process with minimum loss of accuracy and reliability in LLM. Researchers are particularly sensitive to diminishing this reliance on human intervention, which has been one of the major bottlenecks in developing scalable AI planning systems.
These various challenges have been studied through several approaches, where some appear promising while others remain inefficient. Treat LLMs as World Models Several methods involve using LLMs as world models that define the search space for planning tasks. In contrast, other methods include using LLMs to generate whole plans or planning models that automated systems evaluate. Often, the various techniques available have needed more reliability and efficiency due to many different factors, mainly the strong dependence on human feedback. Such methods make it necessary to incorporate more effective automation measures regarding errors or refinement of the generated plans, which, in turn, further limits their scalability and overall effectiveness.
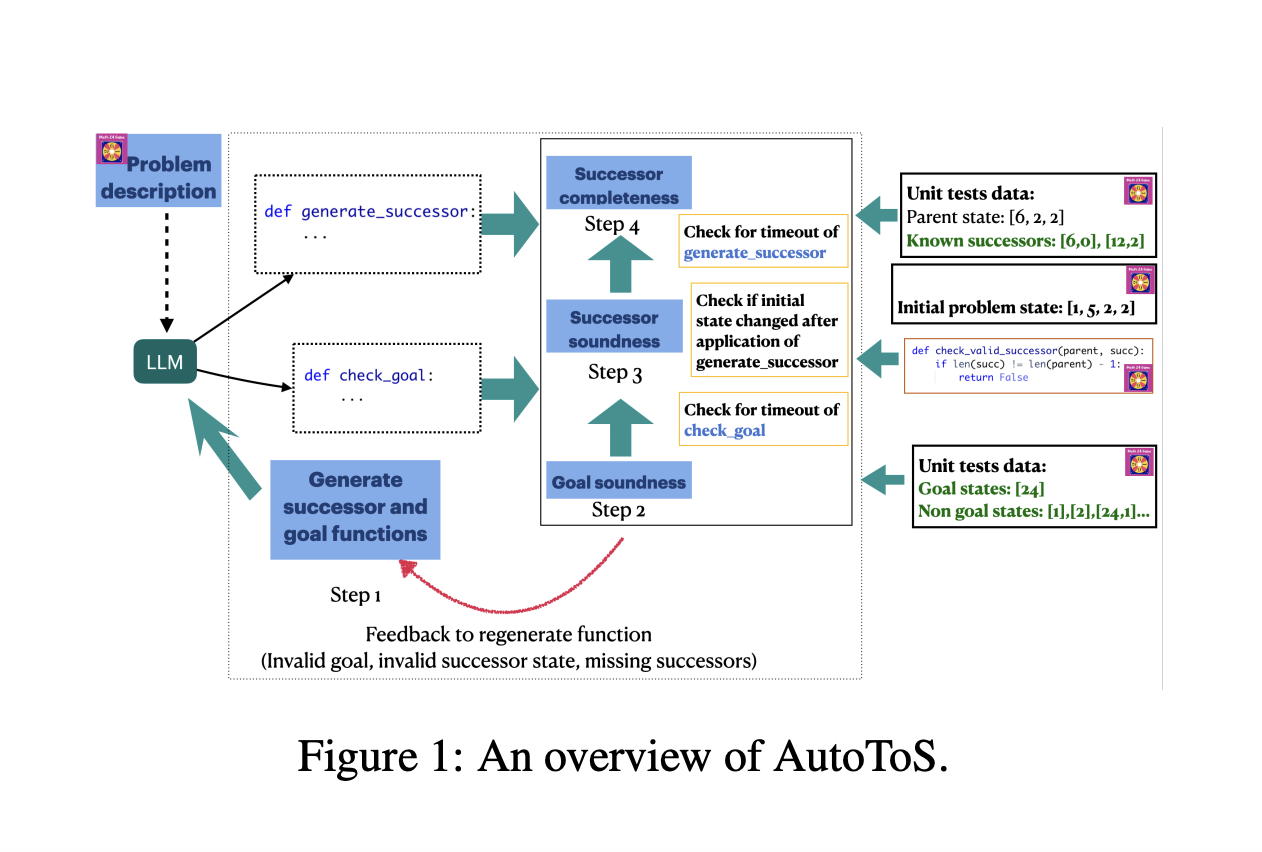
To this end, researchers from Cornell University and IBM Research introduced AutoToS, designed from the ground up to generate sound and complete search components without human oversight automatically. It aims to improve the components of LLM-generated searches by using unit tests and automated debugging processes. AutoToS provides a warranty that, through the loops of feedback, the LLM-guided code will sufficiently meet fulfillment criteria such as soundness and completeness in terms of planning. It is a key contribution to the field of AI planning and brings with it significantly increased scalability and efficiency.
This methodology is remarkable in both its novelty and depth. In it, the system extracts successor functions and a goal test from the LLM; after that, it automatically tests these components using generic and domain-specific unit tests. If some elements do not satisfy the conditions for soundness or completeness, AutoToS returns detailed feedback to the LLM, asking for code revisions. This is an iterative process up to the point in which the generated components are fully validated. The fact is that AutoToS does a Breadth-First Search and a Depth-First Search with extra checks to ensure the search process is sound and complete. This methodology not only automates feedback but also drastically reduces the amount of iterations required to arrive at correct results.
This fast performance of AutoToS was critically examined on several benchmark problems in the domain of search, and the results were quite compelling. Our system achieved 100% accuracy in all the domains we tested successfully: BlocksWorld, PrOntoQA, Mini Crossword, the 24 Game, and Sokoban. In order to get this same level of performance, AutoToS needed significantly fewer feedback iterations. For instance, AutoToS took, on average, 2.6 calls to the LLM to get 100% accuracy on the 24 Game domain. The system achieved perfect performance in the BlocksWorld domain, averaging just 2.8 calls. Results like this support the notion that sound and complete feedback can result in solutions acceptable and right with the least intervention on the part of the human. To further confirm the key role played by feedback soundness and completeness, the researchers also carried out an ablation study.
That is, the study concludes by introducing AutoToS as a state-of-the-art system in AI planning that automatically generates sound and complete search components. By disposing of the necessity of human feedback, AutoToS guarantees a scalable and efficient solution to complex planning problems with guarantees of its correctness and reliability. The group effort between IBM Research and Cornell University has manifested completely new horizons in the field: an automated feedback system that, without much difficulty, surpasses results based on human intervention. This work opens up paths for further developments in the domain of AI planning, with potential applicability from similar approaches across a wide array of domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Find Upcoming AI Webinars here
The post AutoToS: An Automated Feedback System for Generating Sound and Complete Search Components in AI Planning appeared first on MarkTechPost.