Natural Language Processing (NLP) has seen remarkable advancements, particularly in text generation techniques. Among these, Retrieval Augmented Generation (RAG) is a method that significantly improves the coherence, factual accuracy, and relevance of generated text by incorporating information retrieved from specific databases. This approach is especially crucial in specialized fields where precision and context are essential, such as renewable energy, nuclear policy, and environmental impact studies. As NLP continues to evolve, integrating RAG has become increasingly important for generating reliable and contextually accurate outputs in these complex domains.
A key challenge in text generation lies in maintaining the relevance and factual accuracy of the content, especially when dealing with complex and specialized fields like wind energy permitting and siting. While effective in general applications, traditional language models often need help to produce coherent and factually correct outputs in these niche areas. These models may generate irrelevant content or perpetuate inaccuracies due to the limitations inherent in their training data. This problem becomes more pronounced in scenarios that require a good understanding of specific domain knowledge, where the consequences of inaccuracies can be significant, such as in the environmental impact assessments of wind energy projects.
Current methods have relied heavily on large language models (LLMs) like Claude, GPT-4, and Gemini to address this challenge. Although powerful, these models often need to catch up when applied to domain-specific tasks, as they need more context and factual grounding for high-stakes environments. Existing benchmarks, such as the Stanford Question Answering Dataset (SQuAD), which consists of over 100,000 questions, have set a standard for evaluating the performance of these models. However, these benchmarks must be tailored to specific scientific domains, leaving a gap in the tools available to assess model performance in areas like wind energy siting and permitting. This gap has highlighted the need for specialized benchmarks to evaluate RAG models’ effectiveness in these critical fields.
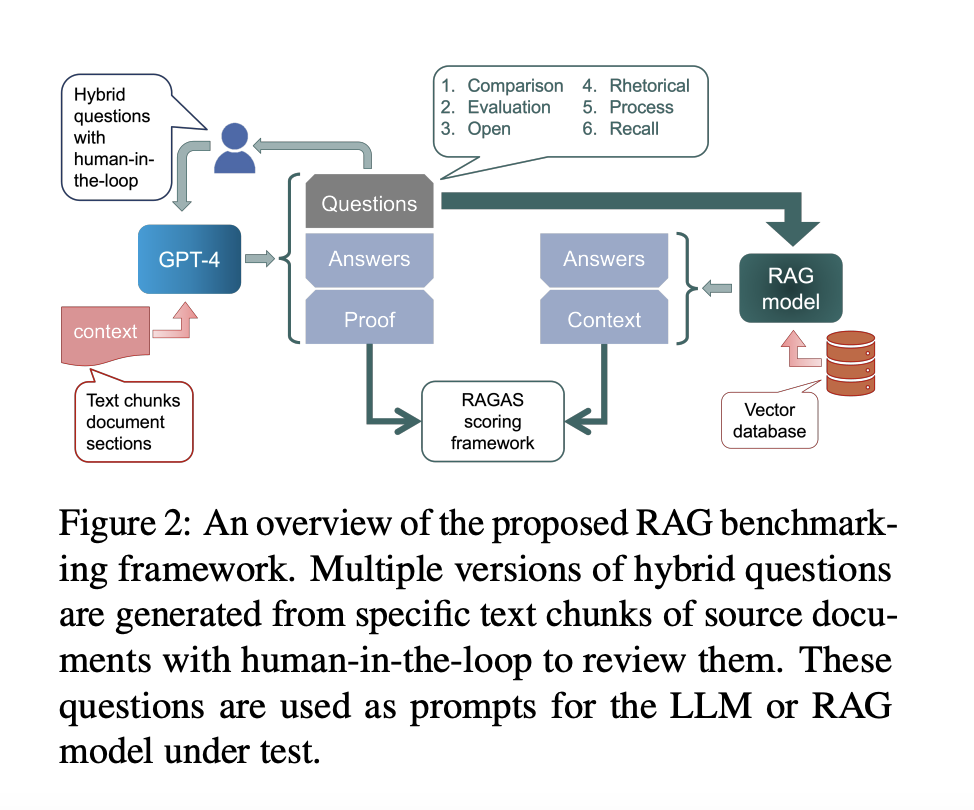
Pacific Northwest National Laboratory researchers have introduced a novel benchmark called PermitQA. This benchmark is specifically designed for the wind siting and permitting domain, a first-of-its-kind tool to evaluate RAG-based LLMs’ performance in handling complex, domain-specific questions. The framework developed for PermitQA is highly adaptable, making it suitable for application across various scientific fields. This flexibility is particularly important as it allows the framework to be customized for different domains, ensuring that the generated responses are not only accurate but also contextually relevant to the specific challenges of each field.
The PermitQA benchmark employs a sophisticated hybrid approach that combines automated and human-curated methods for generating benchmarking questions. The framework utilizes large language models to extract relevant information from extensive documents related to wind energy projects, such as environmental impact studies and permitting reports. These documents, often exceeding hundreds of pages, contain a wealth of information that must be accurately processed to generate meaningful questions. The automated methods rapidly generate initial questions while human experts refine them to ensure they are contextually accurate and challenging enough to evaluate the models thoroughly. This combination of automated speed and human expertise results in a robust benchmarking tool that can assess the performance of LLMs in specialized domains.
The performance of several RAG-based models, including GPT-4, Claude, and Gemini, was rigorously tested using the PermitQA benchmark. The results were telling: while the models performed well on straightforward, factual questions, their performance significantly dropped when faced with more complex, domain-specific queries. For example, the models’ answer correctness scores for “closed” type questions, which require straightforward answers, were as high as 0.672. However, the scores plummeted for “comparison” and “evaluation” type questions, with some models achieving nearly zero correctness. This stark contrast highlights the models’ limitations in handling nuanced and detailed domain-specific information. The PermitQA framework also evaluated context precision and recall. GPT -4 achieved context precision scores of 0.563 on “closed” questions but struggled with more complex “rhetorical” questions, where the precision dropped to 0.192.
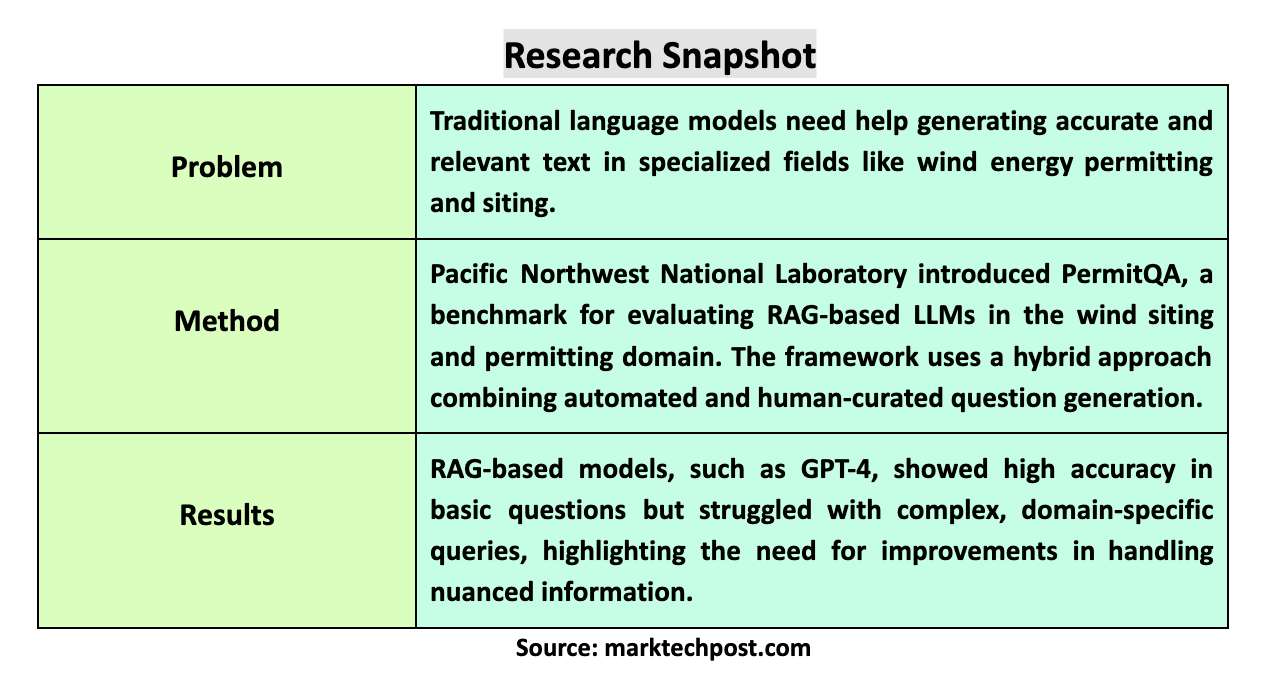
In conclusion, the PermitQA benchmark represents a significant step in evaluating RAG-based models, particularly in the specialized wind energy siting and permitting domain. The benchmark’s ability to combine automated question generation with human curation ensures that it can thoroughly assess the capabilities of LLMs across a range of question types and complexities. The findings from the PermitQA tests reveal that while current models can handle basic queries, they need help with more complex, domain-specific challenges, underscoring the need for further advancements in this area. This research addresses a critical gap in the field. It provides a versatile tool that can be adapted to other specialized domains, ensuring that LLMs can be evaluated and improved across various fields of study. The PermitQA framework thus serves as both a practical tool for current applications and a foundation for future research in improving text generation models in specialized scientific domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post PermitQA: A Novel AI Benchmark for Evaluating Retrieval Augmented Generation RAG Models in Complex Domains of Wind Energy Siting and Environmental Permitting appeared first on MarkTechPost.