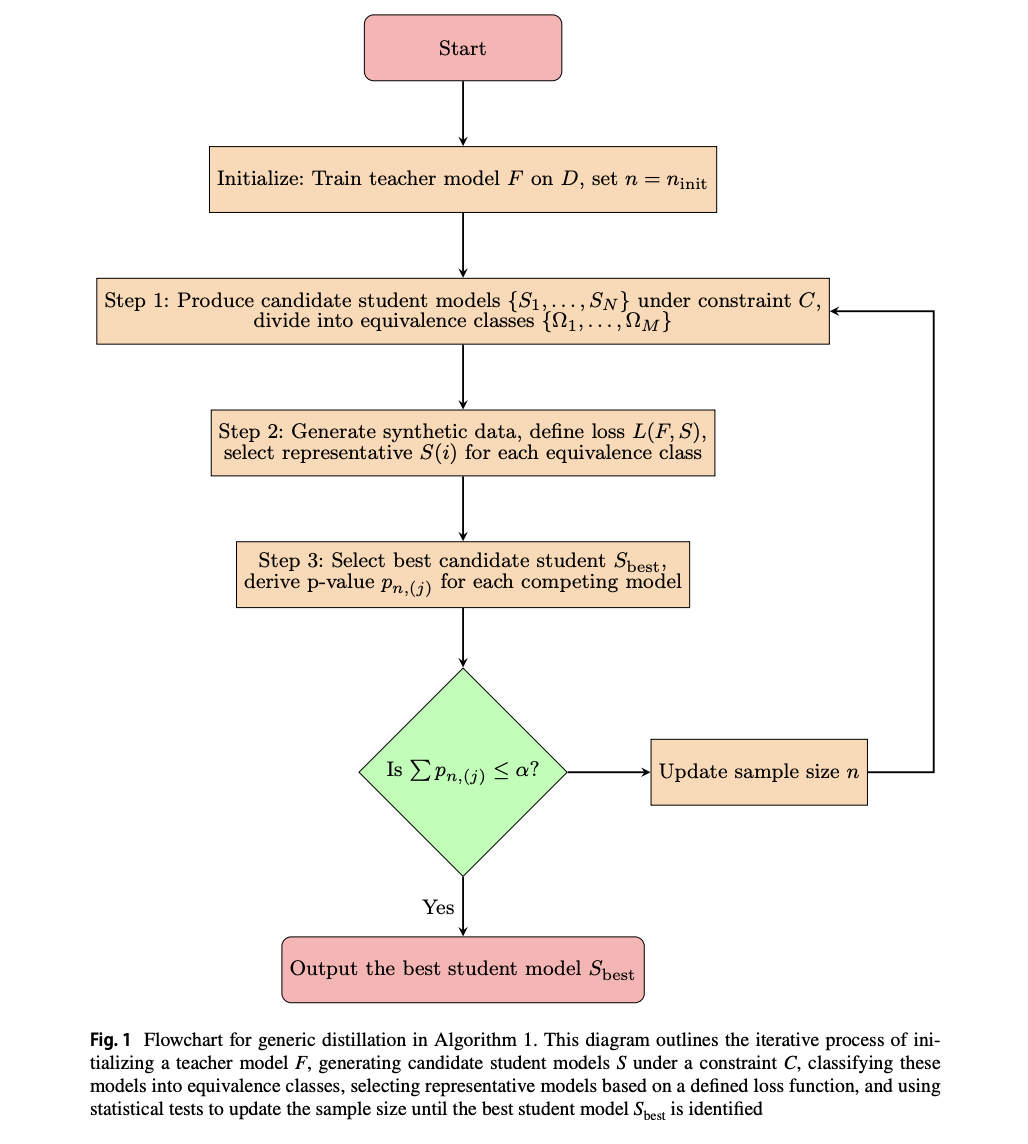
Model distillation is a method for creating interpretable machine learning models by using a simpler “student” model to replicate the predictions of a complex “teacher” model. However, if the student model’s performance varies significantly with different training datasets, its explanations may need to be more reliable. Existing methods for stabilizing distillation involve generating sufficient pseudo-data, but these methods are often tailored to specific types of student models. Strategies like assessing the stability of decision criteria in tree models or feature selection in linear models are employed to address variability. These approaches, while useful, are limited by their dependence on the particular structure of the student model.
Researchers from UC Berkeley and the University of Pennsylvania propose a generic method to stabilize model distillation using a central limit theorem approach. Their framework starts with multiple candidate student models, evaluating how well they align with the teacher model. They employ numerous testing frameworks to determine the necessary sample size for consistent results across different pseudo-samples. This method is demonstrated on decision trees, falling rule lists, and symbolic regression models, with applications tested on Mammographic Mass and Breast Cancer datasets. The study also includes theoretical analysis using a Markov process and sensitivity analysis on factors such as model complexity and sample size.
The study presents a robust approach to stable model distillation by deriving asymptotic properties for average loss based on the central limit theorem. It uses this framework to determine the probability that a fixed model structure will be chosen based on different pseudo samples and calculate the necessary sample size to control this probability. Additionally, researchers implement multiple testing procedures to account for competing models and ensure stability in model selection. The method involves generating synthetic data, selecting the best student model from candidate structures, and adjusting sample sizes iteratively until a significant model is identified.
The researchers specifically address three intelligible student models—decision trees, falling rule lists, and symbolic regression—demonstrating their applicability in providing interpretable and stable model explanations. Using Monte Carlo simulations, Bayesian sampling, and genetic programming, we generate diverse candidate models and classify them into equivalence classes based on their structures. The approach contrasts with ensemble methods by focusing on stability and reproducibility in model selection, ensuring consistent explanations for the teacher model across various data samples.
The experiments on two datasets using a generic model distillation algorithm, focusing on sensitivity analysis of key factors. The setup includes binary classification with cross-entropy loss, a fixed random forest teacher model, and synthetic data generation. Experiments involve 100 runs with varying seeds. Hyperparameters include a significance level (alpha) of 0.05, an initial sample size of 1000, and a maximum length of 100,000. Evaluation metrics cover interpretation stability and student model fidelity. Results show stabilization improves model structure consistency, especially in feature selection. Sensitivity analysis reveals that increasing candidate models and sample size enhances stability, while complex models require larger samples.
The study introduces a stable model distillation method using hypothesis testing and central limit theorem-based test statistics. The approach ensures that enough pseudo-data is generated to select a consistent student model structure from candidates reliably. Theoretical analysis frames the problem as a Markov process, providing bounds on stabilization difficulty with complex models. Empirical results validate the method’s effectiveness and highlight the challenge of distinguishing complex models without extensive pseudo-data. Future work includes refining theoretical analysis with Berry-Esseen bounds and Donsker classes, addressing teacher model uncertainty, and exploring alternative multiple-testing procedures.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Enhancing Stability in Model Distillation: A Generic Approach Using Central Limit Theorem-Based Testing appeared first on MarkTechPost.