The field of natural language processing has made substantial strides with the advent of Large Language Models (LLMs), which have shown remarkable proficiency in tasks such as question answering. These models, trained on extensive datasets, can generate highly plausible and contextually appropriate responses. However, despite their success, LLMs need help dealing with knowledge-intensive queries. Specifically, these queries often require up-to-date information or involve obscure facts that the model might have yet to encounter during training. This limitation can lead to factual inaccuracies or the generation of hallucinated content, particularly when the model is pressed for details outside its stored knowledge. The problem becomes even more pronounced when precision and reliability are paramount, such as in medical or scientific inquiries.
A central challenge in developing and applying LLMs is achieving an optimal balance between accuracy and processing efficiency. When LLMs are tasked with answering complex queries that require integrating information from various sources, they often need help managing long contexts. As the number of relevant documents increases, so does the complexity of reasoning, which can overwhelm the model’s capacity to process information efficiently. This inefficiency slows the response generation and increases the likelihood of errors, particularly in scenarios where the model must sift through extensive contextual information to find the most relevant details. The need for systems that can efficiently incorporate external knowledge, reducing both latency and the risk of inaccuracies, is thus a critical area of research in natural language processing.
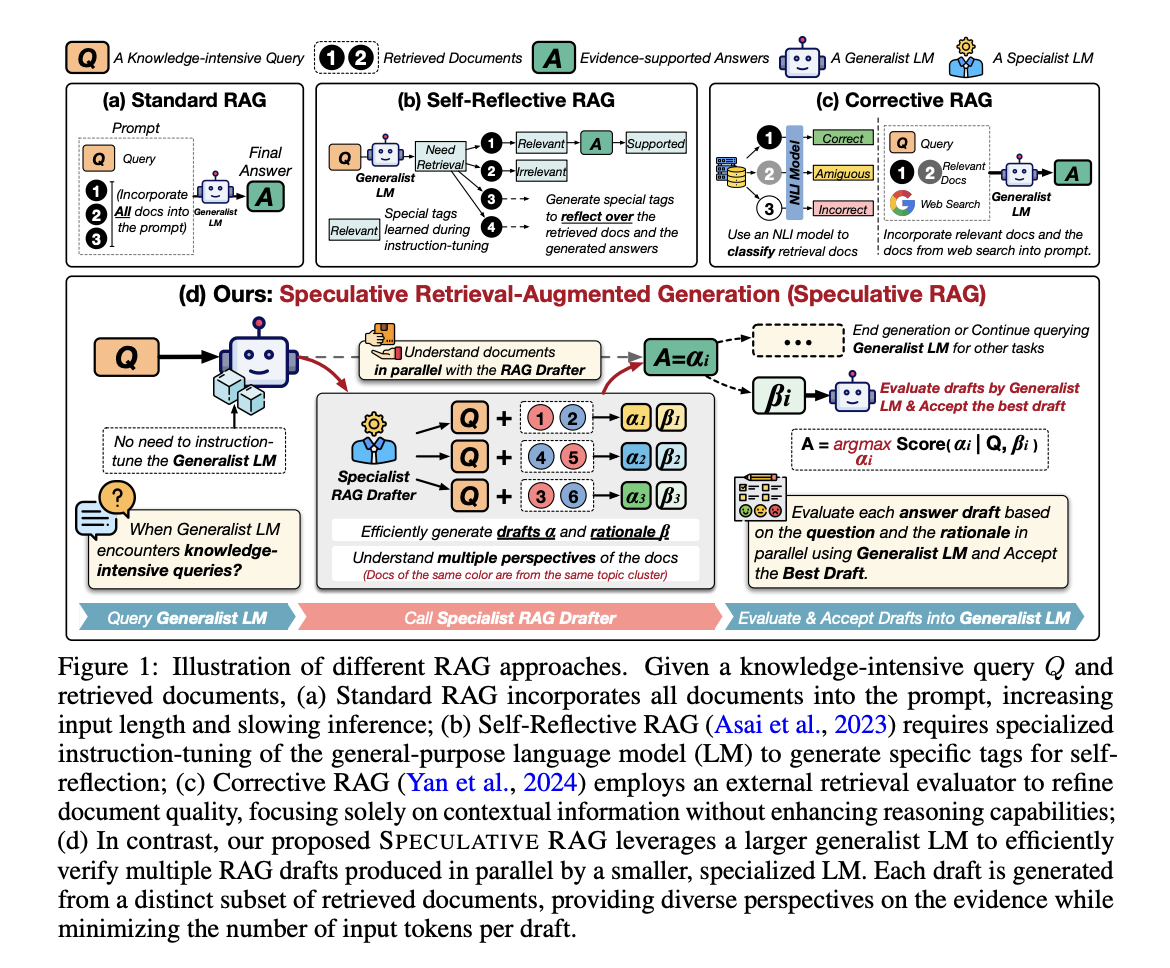
Researchers have developed methods like Retrieval Augmented Generation (RAG), which integrates external knowledge sources directly into the generative process of LLMs. Traditional RAG systems retrieve multiple documents related to the query and incorporate them into the model’s input to ensure a thorough understanding of the topic. While this approach has proven effective in reducing factual errors, it introduces new challenges. Including multiple documents significantly increases the input length, which, in turn, can slow down the inference process and complicate the reasoning required to generate accurate responses. Some advanced RAG systems attempt to refine the quality of the retrieved documents to improve the contextual information provided to the LLM. However, these methods often focus on improving accuracy only after adequately addressing the associated latency issues, which remain a significant bottleneck in the practical application of these models.
Researchers from the University of California San Diego, Google Cloud AI Research, Google DeepMind, and Google Cloud AI introduced a novel approach called Speculative Retrieval Augmented Generation (Speculative RAG). This framework innovatively combines the strengths of both specialist and generalist language models to improve efficiency and accuracy in response generation. The core idea behind Speculative RAG is to leverage a smaller, specialist LM that can generate multiple drafts of potential answers in parallel. Each draft is created from a distinct subset of documents retrieved based on the query to capture diverse perspectives and reduce redundancy. Once these drafts are generated, a larger, generalist LM steps in to verify them. The generalist LM evaluates the coherence and relevance of each draft, ultimately selecting the most accurate one for the final response. This method effectively reduces the input token count per draft, enhancing the response generation process’s efficiency without compromising the answers’ accuracy.
Speculative RAG employs a divide-and-conquer strategy that partitions retrieved documents into subsets based on content similarity. The documents are grouped using clustering techniques, and one document from each cluster is sampled to form a diverse subset. These subsets are then processed by the specialist LM, which generates answer drafts along with corresponding rationales. The generalist LM then evaluates these drafts by calculating a confidence score based on the coherence of the draft and its reasoning. This approach minimizes redundancy in the retrieved documents and ensures that the final answer is informed by multiple perspectives, thereby improving the overall quality and reliability of the response.
The performance of Speculative RAG has been rigorously tested against traditional RAG methods across various benchmarks, including TriviaQA, PubHealth, and ARC-Challenge. The results are compelling: Speculative RAG enhances accuracy by up to 12.97% on the PubHealth benchmark while reducing latency by 51%. In the TriviaQA benchmark, the method achieved an accuracy improvement of 2.15% and a latency reduction of 23.41%. On the ARC-Challenge benchmark, the accuracy increased by 2.14%, with a corresponding latency reduction of 26.73%. These figures underscore the effectiveness of the Speculative RAG framework in delivering high-quality responses more efficiently than conventional RAG systems.

In conclusion, Speculative RAG effectively addresses the limitations of traditional RAG systems by strategically combining the strengths of smaller, specialist language models with larger, generalist ones. The method’s ability to generate multiple drafts in parallel, reduce redundancy, and leverage diverse perspectives ensures that the final output is accurate and efficiently produced. Speculative RAG’s substantial improvements in accuracy and latency across multiple benchmarks highlight its potential to set new standards in applying LLMs for complex, knowledge-intensive queries. As natural language processing continues to evolve, approaches like Speculative RAG will likely play a crucial role in enhancing language models’ capabilities and practical applications in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Speculative Retrieval Augmented Generation (Speculative RAG): A Novel Framework Enhancing Accuracy and Efficiency in Knowledge-intensive Query Processing with LLMs appeared first on MarkTechPost.