
Logs provide important insights that are frequently the earliest signs of system problems, making them an essential tool for program maintenance and failure diagnostics. These logs must be effectively parsed for automated log analysis tasks like anomaly identification, troubleshooting, and root cause investigation. The act of turning semi-structured log messages into structured templates is known as log parsing, and it is a prerequisite for carrying out these automated tasks.
However, there are several obstacles that the state of log parsing technology meets in real-world systems, which frequently results in performance problems. These deficiencies can be attributed to the following three main factors.
- Dependency on Heuristics-Based Parsers: Heuristics-based techniques, which call for hand-crafted features and a thorough comprehension of particular domain expertise, are frequently used by traditional log parsers. These techniques struggle to scale successfully across different systems, even though they can perform admirably in restricted contexts. Generalizing these parsers to handle the vast range of log formats and structures found in large-scale systems is challenging since they require manually constructed rules.
- Limitations of Large Language Model (LLM)-Based Parsers: Several contemporary log parsers use LLMs in order to analyze log data. These LLM-based parsers usually function offline, processing logs in batches at regular intervals. This offline method limits their usefulness in real-time applications because prompt log analysis is essential for locating and fixing problems as soon as they arise. These parsers may be less useful in situations when prompt reactions to anomalies are necessary due to the inherent delay of offline processing.
- Difficulties with Online Parsing Algorithms: Although certain log parsers are made to operate online and handle logs as they are generated in real-time, they have their own set of difficulties. One significant problem is log drift, which occurs when minute modifications to the content or format of logs over time cause an increase in false positives. False positives can potentially overload the system, masking true abnormalities and impeding the timely identification and resolution of actual problems.
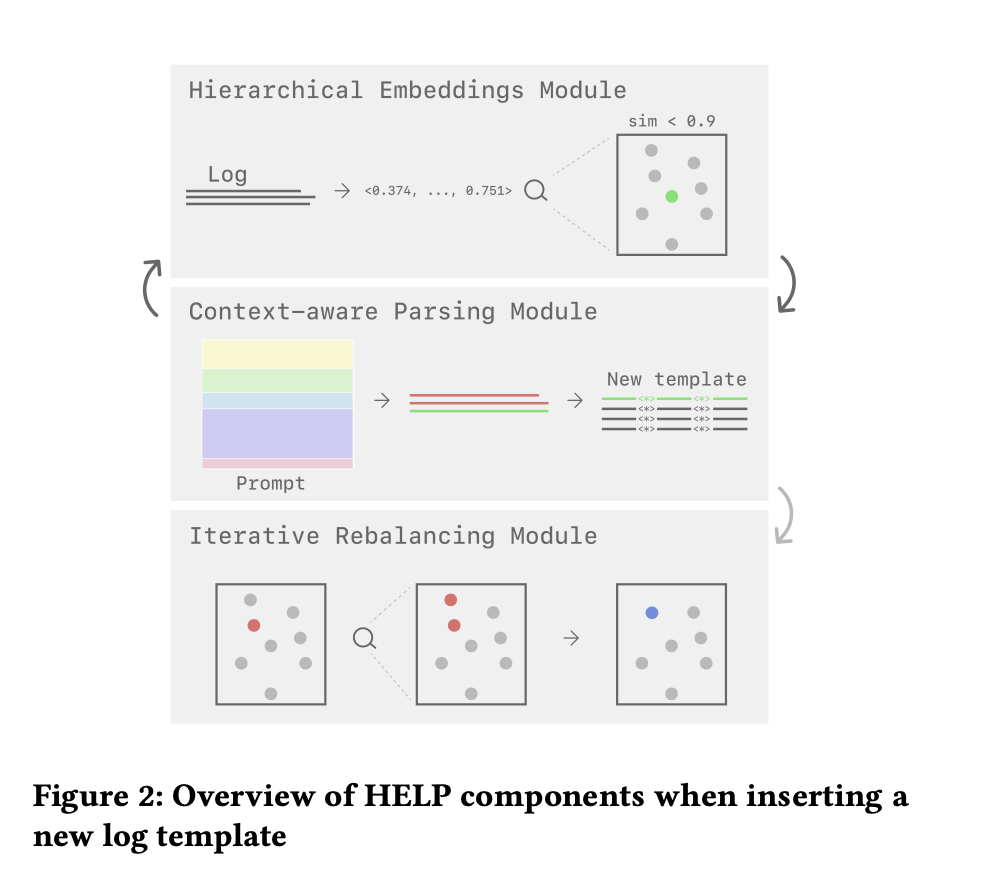
In recent research, the Hierarchical Embeddings-based Log Parser (HELP) has been presented as a solution to these problems. Utilizing the strength of LLMs, HELP is an inventive online semantic-based log parser that produces log parsing that is both very efficient and reasonably priced. HELP is unique among log parsers because of its hierarchical embedding module, which optimizes a text embedding model for log data. By clustering logs before parsing, this methodology drastically lowers the cost and complexity of accessing log data by several orders of magnitude.
A module for iterative rebalancing has also been included in HELP to address the issue of log drift. This module makes sure that the parser stays precise and functional even if log formats change over time by routinely updating the current log groupings. HELP maintains a high degree of accuracy in recognizing genuine anomalies while reducing the frequency of false positives by continuously improving its comprehension of log data.
The effectiveness of HELP has been comprehensively assessed using 14 large-scale public datasets. HELP showed much higher F1-weighted grouping and parsing accuracy compared to the state-of-the-art online log parsers. In addition to passing these benchmark tests, HELP has been effectively integrated into Iudex’s production observability platform. The feasibility and dependability of HELP in managing high-throughput log processing tasks in production contexts have been validated by this real-world application.
The team has summarized their primary contributions as follows.
- To facilitate online log grouping and parsing, HELP has been developed, the first log parser that makes use of semantic embeddings.
- HELP has been effectively implemented in an actual production setting, verifying its applicability. Its periodic rebalancing feature helps to prevent template drift and ensures log pattern assignment in real-time.
- Using 14 public log datasets, extensive testing has been conducted on HELP, and it has been found that it outperforms all other state-of-the-art log parsers in terms of parsing accuracy and log grouping. Furthermore, with no sacrifice in speed, HELP can be modified to become a parallel batch processing framework.
In conclusion, HELP is a significant development in log processing technology. The capabilities of LLMs are combined with the advantages of hierarchical embeddings and iterative rebalancing to provide HELP, a scalable, reliable, and effective solution for real-time log parsing in contemporary software systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post HELP (Hierarchical Embeddings-based Log Parser): A Semantic Embeddings-based Framework for Real-Time Log Parsing appeared first on MarkTechPost.