
Computational social science (CSS) leverages advanced computational techniques to analyze and interpret vast amounts of social data. This field increasingly relies on natural language processing (NLP) methods to handle unstructured text data. However, while large language models (LLMs) have revolutionized CSS by enabling rapid and sophisticated text analysis, their integration into practical applications remains a complex challenge. This complexity arises from various constraints, including high costs, data privacy concerns, and the limitations imposed by network infrastructures, particularly in resource-constrained or sensitive environments.
Due to these limitations, a significant problem in CSS is deploying LLMs in real-world applications. LLMs require substantial computational resources and often face obstacles related to cost-effectiveness and data security, especially when organizations rely on external APIs. Although powerful, these models are only sometimes reliable when applied to out-of-domain data. This unreliability is particularly problematic for supervised learning models, which are essential for many CSS tasks but demand extensive data labeling—a time-consuming and expensive process. The need for a solution that balances the capabilities of LLMs with the practicalities of deploying models in constrained environments has become increasingly urgent.
Current methods for CSS tasks, such as stance detection, misinformation identification, and ideology classification, typically involve LLMs due to their ability to perform zero-shot classification. However, these methods have limitations. For instance, labeling a dataset like SemEval-16, which consists of 2,814 data points, with a model like GPT-4 could cost over USD 30. LLMs need help with tasks requiring high contextual understanding, often leading to poor generalization across different datasets. This is evident in the poor performance of cross-dataset stance detection models, which fail to generalize effectively despite aggregating diverse datasets. These challenges highlight the need for other approaches to reduce reliance on LLMs while maintaining performance.
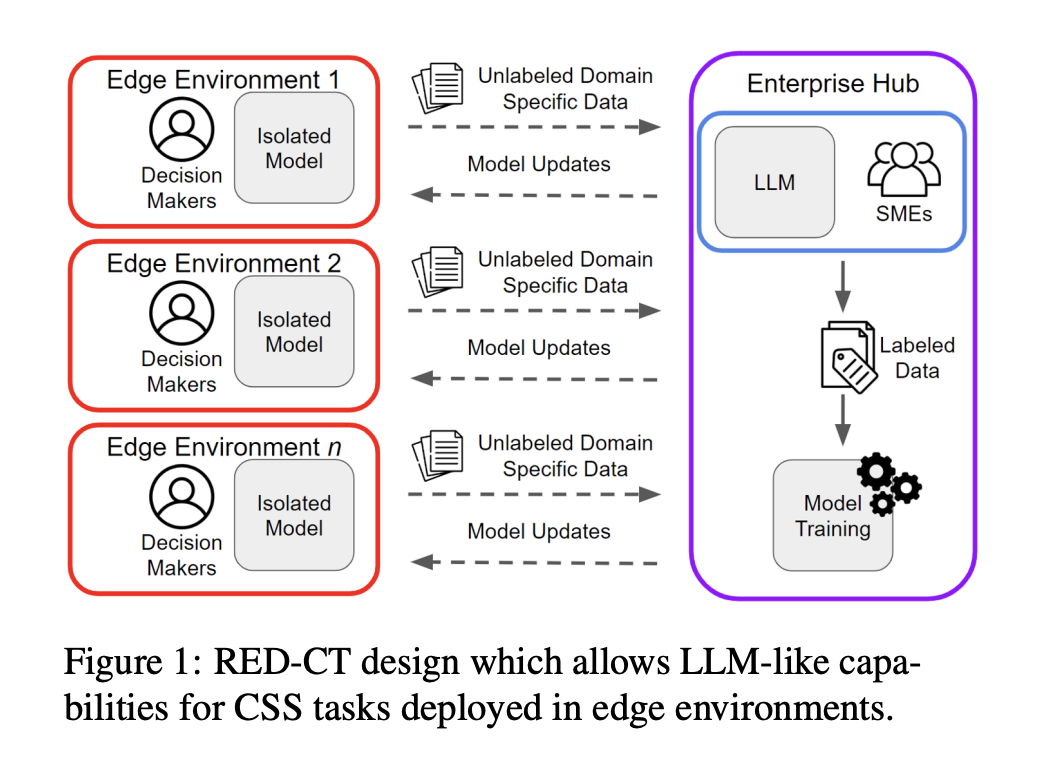
Researchers from the University of Washington, the Army Cyber Institute, and Carnegie Mellon University introduced the Rapid Edge Deployment for CSS Tasks (RED-CT) system to address these issues. This innovative system is designed to quickly deploy edge classifiers using LLM-labeled data in conjunction with minimal human annotation. The system is specifically tailored for use in environments where resources are limited, such as situations with restricted network access or where cost and data privacy are critical concerns. RED-CT aims to optimize the use of LLMs by reducing their dependency while benefiting from their classification capabilities.
The RED-CT system employs a confidence-informed sampling method that selects LLM-labeled data for human annotation, significantly improving the accuracy of edge classifiers. This system also integrates soft labels generated from LLM predictions, which are utilized during the training these classifiers. By focusing on the edge environment—where resources like time, computational power, and connectivity are constrained—RED-CT ensures that CSS tasks can be performed efficiently without over-reliance on LLMs. The modular design allows continuous performance improvement as LLMs and other system components evolve, making it a robust solution for dynamic and challenging environments.
Regarding performance, the RED-CT system demonstrated remarkable results across various CSS tasks. The researchers evaluated the system using four CSS tasks: stance detection, misinformation detection, ideology detection, and humor detection. The system outperformed LLM-generated labels in seven of the eight tasks tested, with an average improvement of 6.5% over base classifiers trained without system interventions. Specifically, the system showed significant gains in tasks like stance detection and misinformation identification, where integrating expert-labeled data and confidence-informed sampling played a crucial role. The RED-CT system’s ability to approximate or even surpass the performance of LLMs, particularly when minimal human intervention is involved, highlights its potential for real-world applications.

In conclusion, the RED-CT system offers a powerful and efficient solution for deploying edge classifiers in CSS tasks. By integrating LLM-labeled data with human annotations and innovative sampling techniques, this system addresses the critical challenges of using LLMs in constrained environments. The system reduces the dependency on LLMs and enhances performance in key areas, making it a valuable tool for computational social scientists. The significant improvements in accuracy and efficiency demonstrated by RED-CT suggest that it could become a standard approach for deploying machine learning models in environments with limited resources, providing a practical and scalable solution for CSS applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Rapid Edge Deployment for CSS Tasks (RED-CT): A Novel System for Efficiently Integrating LLMs with Minimal Human Annotation in Resource-Constrained Environments appeared first on MarkTechPost.