The application of RL to problems in complex decision-making, particularly in situations with limited resources and uncertain outcomes, has recently become very useful. In the varied applications of RL, what distinguishes Restless Multi-Arm Bandits (RMABs) is their solution to multi-agent resource allocation problems. RMAB models depict the management of several decision points or “arms,” each requiring careful selection to maximize cumulative rewards at each end. Such models have been instrumental in fields such as healthcare, where they optimize the flow of medical resources; online advertisement, where they improve the efficiency of targeting strategies; and conservation, where they inform anti-poaching operations. However, some challenges remain in applying RMABs in real life.
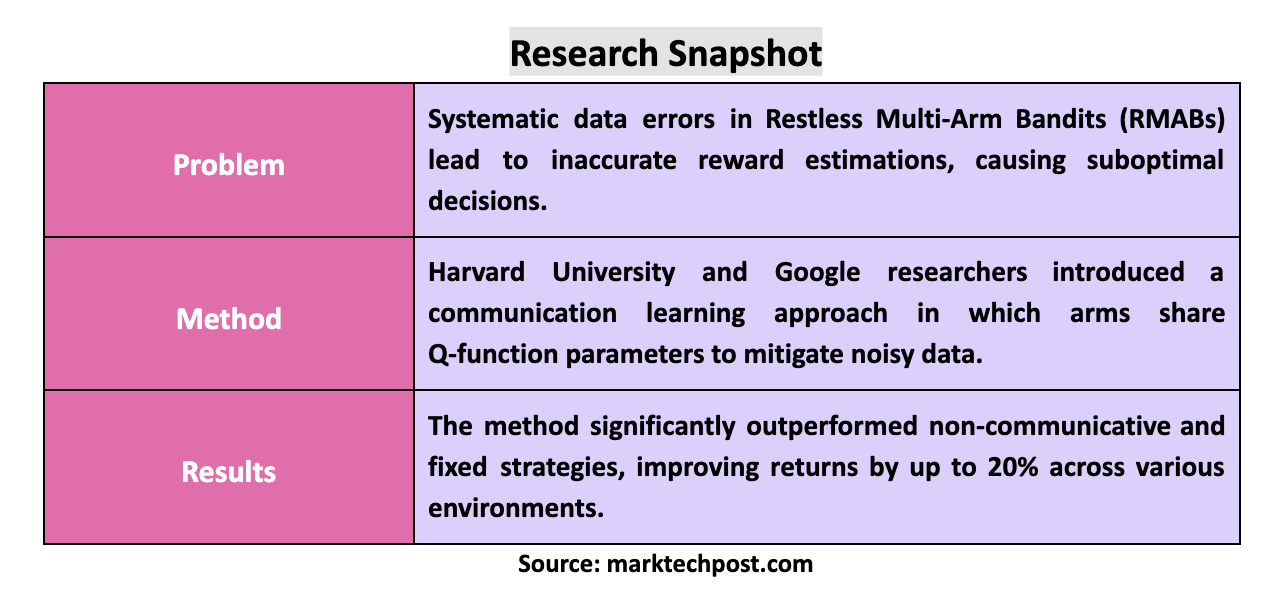
Systematic data errors are among the major problems affecting the efficient implementation of RMAB. These errors could result from inconsistent data collection protocols across geographies, noise added for differential privacy or changes in handling procedures. Inherent errors like these lead to wrong reward estimations and, hence, can result in suboptimal decisions on the part of the RMAB. For example, a case of overestimation in the expected delivery date has been reported in maternal health care, where inconsistent data collection methods lead to the allocation of resources and reduced deliveries within health facilities. These errors become particularly pernicious when they affect only some of the decision points—so-called “noisy arms”—within the RMAB model.
Several variants of deep RL techniques have been developed to handle such issues. The goal is to ensure the optimal performance of the RMAB methods under noisy data conditions. Most existing approaches assume reliable data collection from all arms, which may only be true in some real-world applications. These methods sometimes miss the best actions when some arms are affected by data errors since the so-called false optima can mislead them—cases in which the algorithm mistakes a suboptimal solution for the best. Misidentification can greatly reduce efficiency and effectiveness, especially in high-stakes health or epidemic intervention applications.
Researchers at Harvard University and Google proposed a new paradigm of learning within RMABs: communication. Sharing across the many arms of an RMAB allows them to help each other correct systematic errors in the data, thus improving decision quality. By opening up the opportunity for the arms to communicate, the researchers hoped to reduce the impact of noisy data on an RMAB’s performance. The proposed method has been tested in a wide range of settings, from synthetic environments to maternal healthcare scenarios and epidemic intervention models, all of which establish the applicability of this method in many applications.
The approach to communication learning uses a Multi-Agent MDP framework that provides an option of communicating with another arm of similar characteristics. When one arm needs to communicate, it gets the parameters of the Q-function from the other arm and refines its behavior policy. By exchanging information this way, the arm can explore better strategies and avoid the pitfalls of suboptimal actions caused by noisy data. The investigators constructed a decomposed Q-network architecture to manage the joint utility of communication overall arms. Concretely, their experiments showed that communication in both directions between noisy and non-noisy arms could be useful if the behavior policy of the receiver arm attains reasonable coverage over the state-action space.
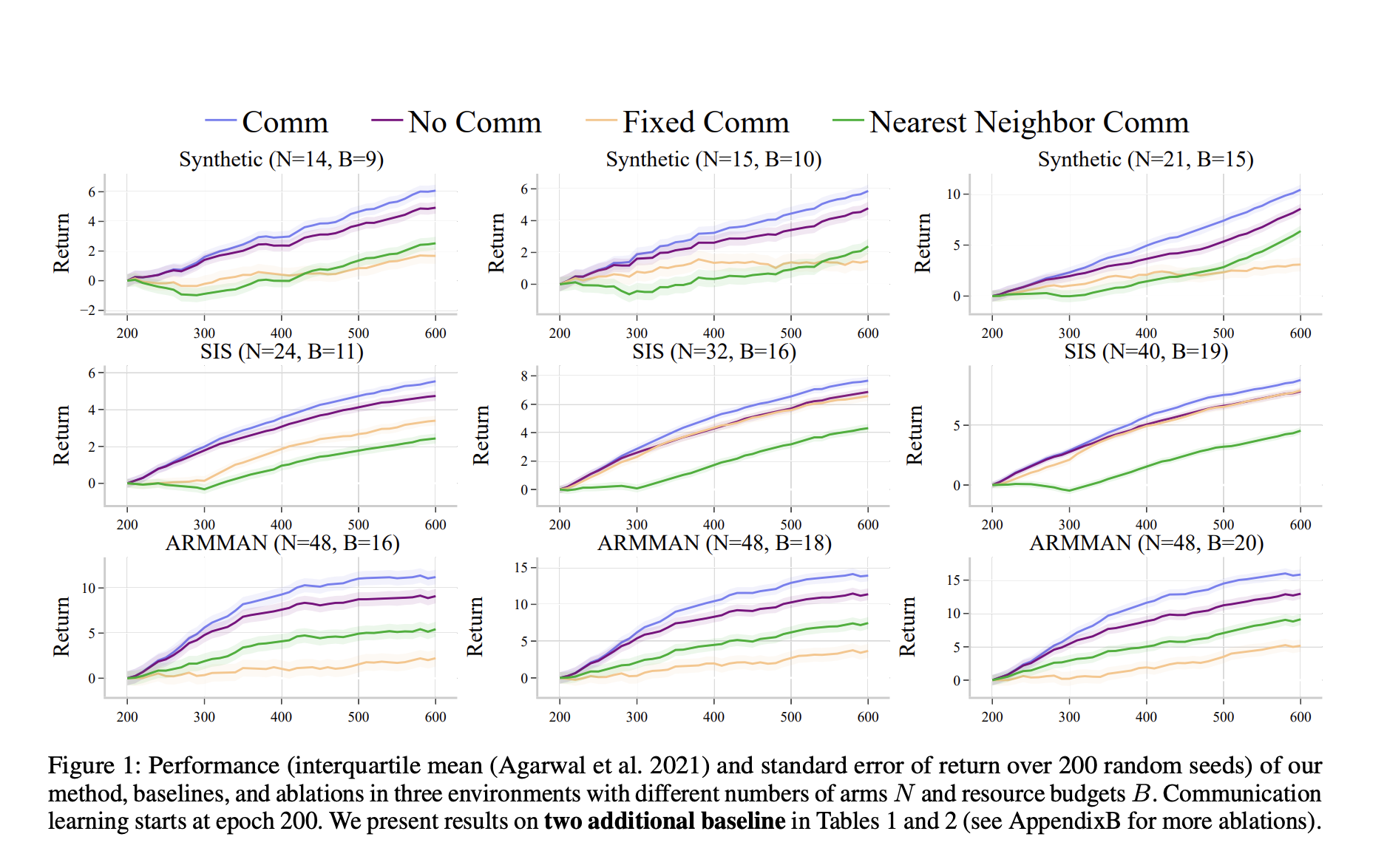
The researchers have rightly validated their approach with extensive empirical testing. In the empirical tests, they compared the performance of the proposed communication learning method against that of baseline methods. For example, in the artificial RMAB setting with 15 arms and a budget of 10, the proposed method was better than both non-communicative and fixed communication strategies with an approximate return of 10 at epoch 600, significantly improving the return compared to the no-communication baseline, which reached a return of about 8. Similar results were obtained in real-world scenarios like the ARMMAN maternal healthcare model, whereby for an environment with 48 arms and a budget of 20, the return attained by the method was 15, compared with 12.5 achieved by the no-communication baseline. These results show how this learning of communication is general across a wide variety of problem domains, resource constraints, and levels of data noise.
In conclusion, the study introduces a groundbreaking communication learning algorithm that significantly enhances the performance of RMABs in noisy environments. By allowing arms to share Q-function parameters and learn from each other’s experiences, the proposed method effectively reduces the impact of systematic data errors. It improves the overall efficiency of resource allocation decisions. The empirical results, backed by rigorous theoretical analysis, demonstrate that this approach not only outperforms existing methods but also offers greater robustness and adaptability to real-world challenges. This advancement in RMAB technology can potentially revolutionize how resource allocation problems are addressed in various fields, from healthcare to public policy, paving the way for more efficient and effective decision-making processes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Harvard and Google Researchers Developed a Novel Communication Learning Approach to Enhance Decision-Making in Noisy Restless Multi-Arm Bandits appeared first on MarkTechPost.