
As AI models grow more sophisticated, they often require extensive prompts with detailed context, leading to increased costs and latency in processing. This problem is especially pertinent for use cases like conversational agents, coding assistants, and large document processing, where the context needs to be repeatedly referenced across multiple interactions. The researchers address the challenge of efficiently managing and utilizing large prompt contexts in AI models, particularly in scenarios requiring frequent reuse of similar contextual information.
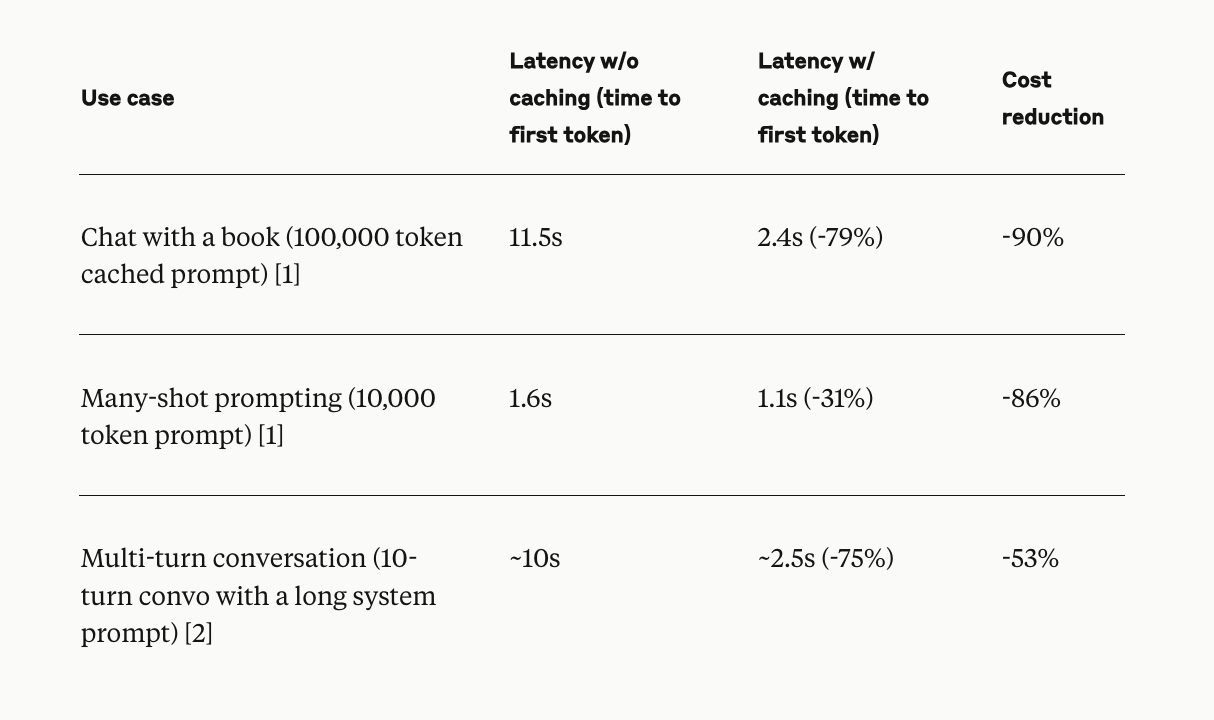
Traditional methods involve sending the entire prompt context with each API call, which can be costly and time-consuming, especially with long prompts. These methods are not optimized for prompts where the same or similar context is used repeatedly. Anthropic API introduces a new feature called “prompt caching,” which is available for specific Claude models. Prompt caching allows developers to store frequently used prompt contexts and reuse them across multiple API calls. The proposed model significantly reduces the cost and latency associated with sending large prompts repeatedly. The feature is currently in public beta for Claude 3.5 Sonnet and Claude 3 Haiku, with support for Claude 3 Opus forthcoming.
Prompt caching works by enabling developers to cache a large prompt context once and then reuse that cached context in subsequent API calls. This method is particularly effective in scenarios such as extended conversations, coding assistance, large document processing, and agentic search, where a significant amount of contextual information needs to be maintained throughout multiple interactions. The cached content can include detailed instructions, codebase summaries, long-form documents, and other extensive contextual information. The pricing model for prompt caching is structured to be cost-effective: writing to the cache incurs a 25% increase in input token price while reading from the cache costs only 10% of the base input token price. Early users of prompt caching have reported substantial improvements in both cost efficiency and processing speed, making it a valuable tool for optimizing AI-driven applications.
In conclusion, prompt caching addresses a critical need for reducing costs and latency in AI models that require extensive prompt contexts. By allowing developers to store and reuse contextual information, this feature enhances the efficiency of various applications, from conversational agents to large document processing. The implementation of prompt caching on the Anthropic API offers a promising solution to the challenges posed by large prompt contexts, making it a significant advancement in the field of LLMs.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post Prompt Caching is Now Available on the Anthropic API for Specific Claude Models appeared first on MarkTechPost.