In recent years, research on tabular machine learning has grown rapidly. Yet, it still poses significant challenges for researchers and practitioners. Traditionally, academic benchmarks for tabular ML have not fully represented the complexities encountered in real-world industrial applications.
Most available datasets either lack the temporal metadata necessary for time-based splits or come from less extensive data acquisition and feature engineering pipelines compared to common industry ML practices. This can influence the types and amounts of predictive, uninformative, and correlated features, impacting model selection. Such limitations can lead to overly optimistic performance estimates when models evaluated on these benchmarks are deployed in real-world ML production scenarios.
To address these gaps, researchers at Yandex and HSE University have introduced TabReD, a novel benchmark designed to closely reflect industry-grade tabular data applications. TabReD consists of eight datasets from real-world applications spanning domains such as finance, food delivery, and real estate. The team has made the code and datasets publicly available on GitHub.
Constructing the TabReD Benchmark
To construct TabReD, researchers used datasets from Kaggle competitions and Yandex’s ML applications. They followed four rules: datasets must be tabular, feature engineering should match industry practices, and datasets with data leakage should be excluded. They also ensured datasets had timestamps and enough samples for time-based splits, excluding those without future instances.
The eight datasets in the TabReD benchmark include the following:
- Homesite Insurance: Predicts whether a customer will buy home insurance based on user and policy features.
- Ecom Offers: Classifies whether a customer will redeem a discount offer based on transaction history.
- HomeCredit Default: Predicts whether bank clients will default on a loan, using extensive internal and external data, focusing on model stability over time.
- Sberbank Housing: Predicts the sale price of properties in the Moscow housing market, utilizing detailed property and economic indicators.
- Cooking Time: Estimates the time required for a restaurant to prepare an order based on order contents and historical cooking times.
- Delivery ETA: Predicts the estimated arrival time for online grocery orders using courier availability, navigation data, and historical delivery information.
- Maps Routing: Estimates travel time in a car navigation system based on current road conditions and route details.
- Weather: Forecasts temperature using weather station measurements and physical models.
These datasets have two key practical properties often missing in academic benchmarks. First, they are split into train, validation, and test sets based on timestamps, essential for accurate evaluation. Second, they include more features due to extensive data acquisition and feature engineering efforts.
Experimental Results and Future Research
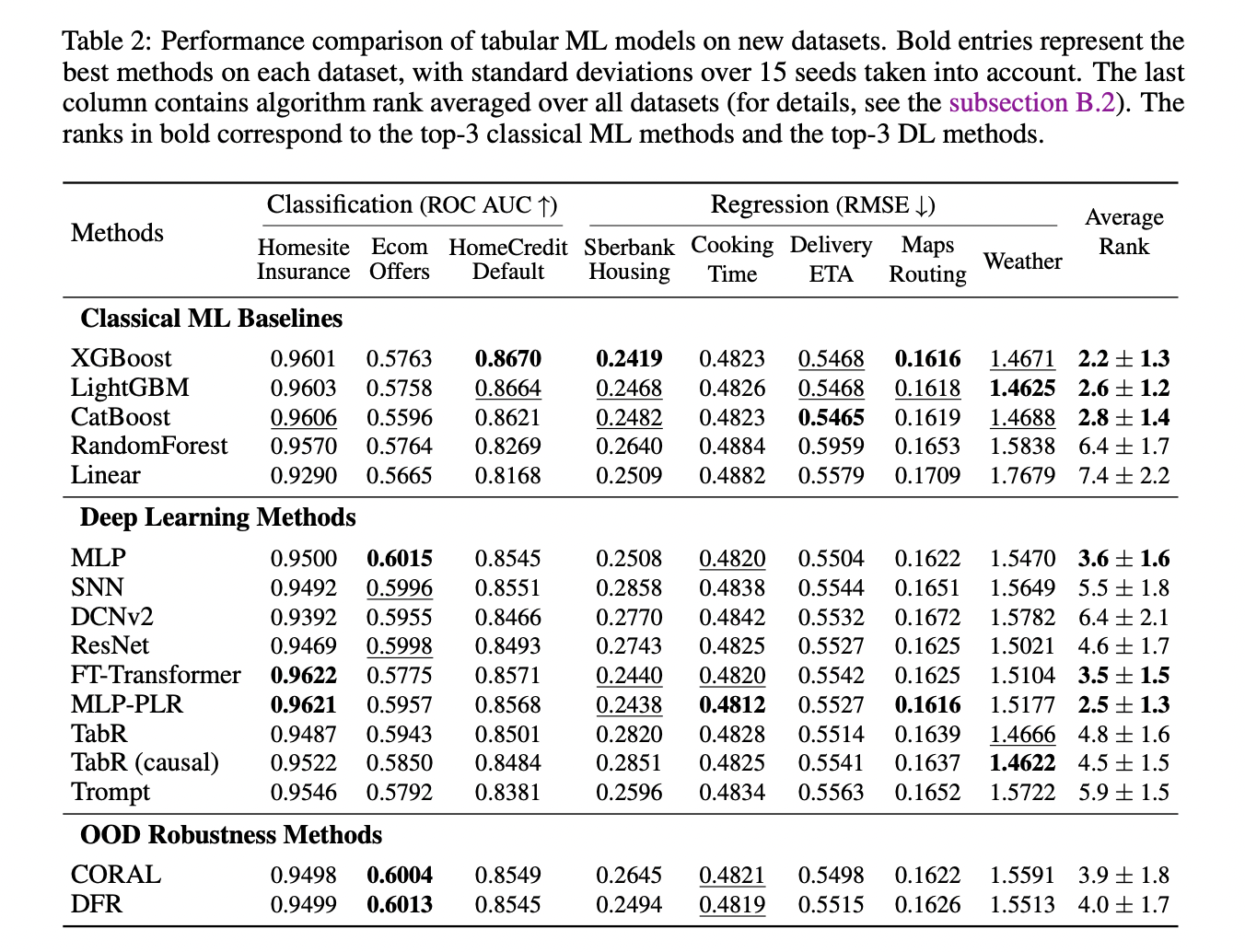
The researchers tested recent deep learning methods for tabular data on the TabReD benchmark to assess their performance with time-based data splits and additional features.
They concluded that time-based data splits were crucial for proper evaluation. The choice of splitting strategy significantly affected all aspects of model comparison: absolute metric values, relative performance differences, standard deviations, and the relative ranking of models.
The results identified MLP with embeddings for continuous features as a simple yet effective deep learning baseline, while more advanced models showed less impressive performance in this context.
TabReD bridges the gap between academic research and industrial application in tabular machine learning. It enables researchers to develop and evaluate models that are more likely to perform well in production environments by providing a benchmark that closely mirrors real-world scenarios. This is crucial for the streamlined adoption of new research findings in practical applications.
The TabReD benchmark sets the stage for exploring additional research avenues, such as continual learning, handling gradual temporal shifts, and improving feature selection and engineering techniques. It also highlights the need for developing robust evaluation protocols to better assess ML models’ true performance in dynamic, real-world settings.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post Yandex Introduces TabReD: A New Benchmark for Tabular Machine Learning appeared first on MarkTechPost.