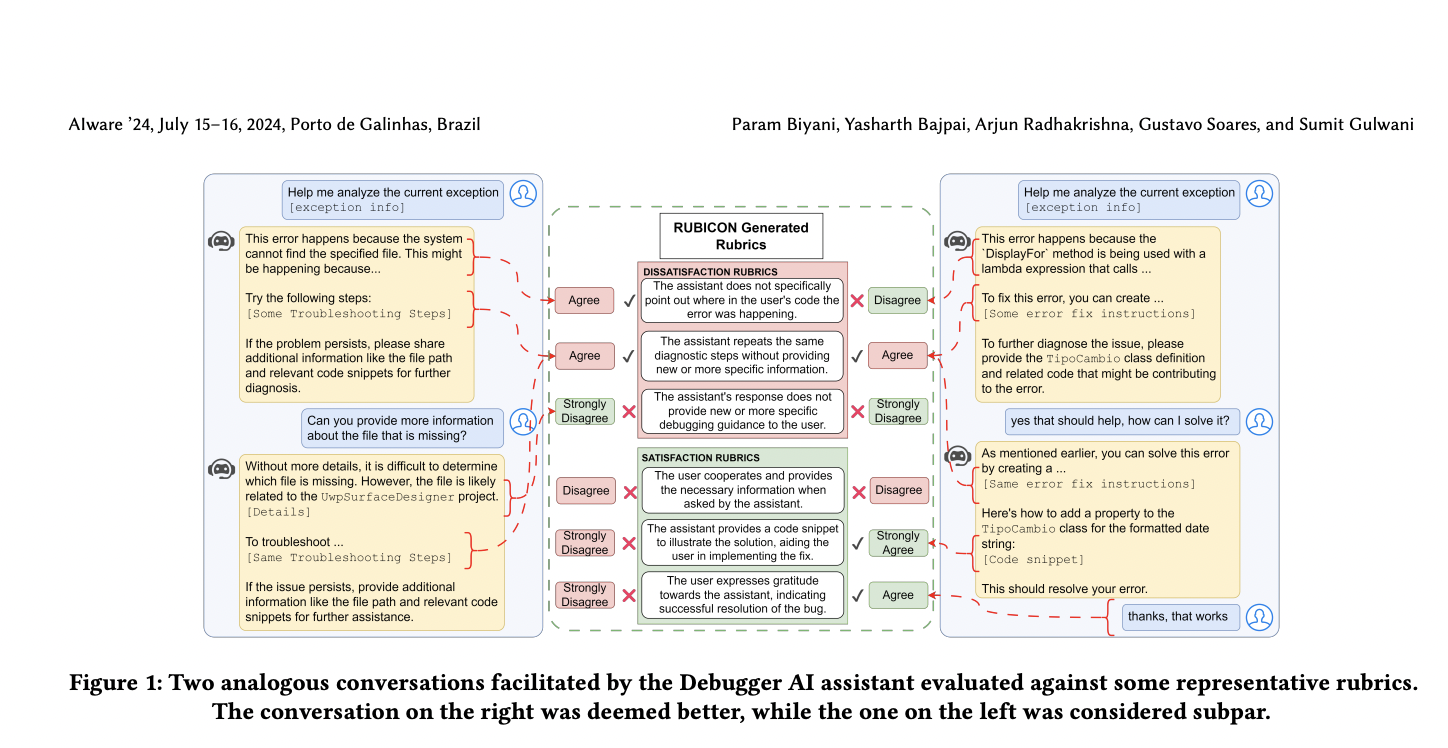
Evaluating conversational AI assistants, like GitHub Copilot Chat, is challenging due to their reliance on language models and chat-based interfaces. Existing metrics for conversational quality need to be revised for domain-specific dialogues, making it hard for software developers to assess the effectiveness of these tools. While techniques like SPUR use large language models to analyze user satisfaction, they may miss domain-specific nuances. The study focuses on automatically generating high-quality, task-aware rubrics for evaluating task-oriented conversational AI assistants, emphasizing the importance of context and task progression to improve evaluation accuracy.
Researchers from Microsoft present RUBICON, a technique for evaluating domain-specific Human-AI conversations using large language models. RUBICON generates candidate rubrics to assess conversation quality and selects the best-performing ones. It enhances SPUR by incorporating domain-specific signals and Gricean maxims, creating a pool of rubrics evaluated iteratively. RUBICON was tested on 100 conversations between developers and a chat-based assistant for C# debugging, using GPT-4 for rubric generation and assessment. It outperformed alternative rubric sets, achieving high precision in predicting conversation quality and demonstrating the effectiveness of its components through ablation studies.
Natural language conversations are central to modern AI applications, but traditional NLP metrics like BLEU and Perplexity are inadequate for evaluating long-form conversations, especially in LLMs. While user satisfaction has been a key metric, manual analysis is resource-intensive and privacy-intrusive. Recent approaches use language models to assess conversation quality through natural language assertions, capturing engagement and user experience themes. Techniques like SPUR generate rubrics for open-domain conversations but need more domain-specific contexts. This study emphasizes a holistic approach, integrating user expectations and interaction progress, and explores optimal prompt selection using bandit methods for improved evaluation accuracy.
RUBICON estimates conversation quality for domain-specific assistants by learning rubrics for Satisfaction (SAT) and Dissatisfaction (DSAT) from labeled conversations. It involves three steps: generating diverse rubrics, selecting an optimized rubric set, and scoring conversations. Rubrics are natural language assertions capturing conversation attributes. Conversations are evaluated using a 5-point Likert scale, normalized to a [0, 10] range. Rubric generation involves supervised extraction and summarization, while selection optimizes rubrics for precision and coverage. Correctness and sharpness losses guide the selection of an optimal rubric subset, ensuring effective and accurate conversation quality assessment.
The evaluation of RUBICON involves three key questions: its effectiveness compared to other methods, the impact of Domain Sensitization (DS) and Conversation Design Principles (CDP), and the performance of its selection policy. The conversation data, sourced from a C# Debugger Copilot assistant, was filtered and annotated by experienced developers, resulting in a 50:50 train-test split. Metrics like accuracy, precision, recall, F1 score, ΔNetSAT score, and Yield Rate were evaluated. Results showed that RUBICON outperforms baselines in separating positive and negative conversations and classifying conversations with high precision, highlighting the importance of DS and CDP instructions.
Internal validity is threatened by the subjective nature of manually assigned ground truth labels despite high inter-annotator agreement. External validity is limited by the dataset’s lack of diversity, being specific to C# debugging tasks in a software company, potentially affecting generalization to other domains. Construct validity issues include the reliance on an automated scoring system and assumptions made by converting Likert scale responses into a [0, 10] scale. Future work will address different calculation methods for the NetSAT score. RUBICON has succeeded in enhancing rubric quality and differentiating conversation effectiveness, proving valuable in real-world deployment.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post This AI Paper from Microsoft Present RUBICON: A Machine Learning Technique for Evaluating Domain-Specific Human-AI Conversations appeared first on MarkTechPost.