
In the realm of Large language models (LLMs), there has been a significant transformation in text generation, prompting researchers to explore their potential in audio synthesis. The challenge lies in adapting these models for text-to-speech (TTS) tasks while maintaining high-quality output. Current methodologies, such as neural codec language models like VALL-E, face several limitations. These include lower fidelity compared to mel-spectrograms, robustness issues stemming from random sampling strategies, and the need for complex two-pass decoding processes. These challenges hinder the efficiency and quality of audio synthesis, particularly in zero-shot TTS tasks that require multi-lingual, multi-speaker, and multi-domain capabilities.
Researchers have attempted to tackle the challenges in text-to-speech (TTS) synthesis. Traditional methods include concatenative systems, which reassemble audio segments, and parametric systems, which use acoustic parameters to synthesize speech. End-to-end neural TTS systems, such as Tacotron, TransformerTTS, and FastSpeech, simplified the process by generating mel-spectrograms directly from text.
Recent advancements focus on zero-shot TTS capabilities. Models like VALL-E treat TTS as a conditional language task, using neural codec codes as intermediate representations. VALL-E X extended this approach to multi-lingual scenarios. Mega-TTS proposed disentangling speech attributes for more efficient modeling. Other models like ELLA-V, RALL-E, and VALL-E R aimed to improve robustness and stability.
Some researchers explored non-autoregressive approaches for faster inference, such as SoundStorm’s parallel decoding scheme and StyleTTS 2’s diffusion model. However, these methods often struggle to maintain audio quality or efficiently handle multi-speaker, multi-lingual scenarios.
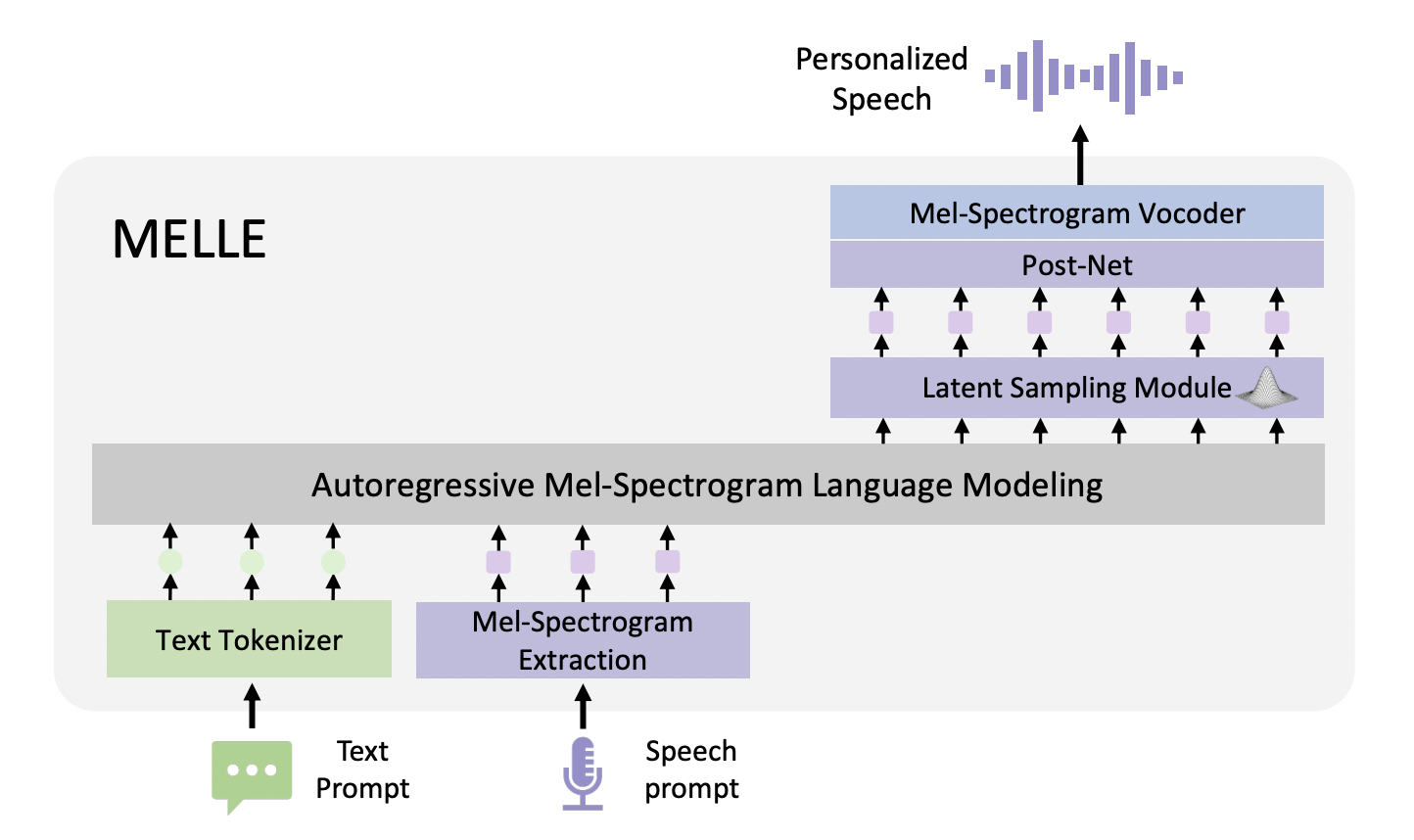
Researchers from The Chinese University of Hong Kong and Microsoft Corporation present MELLE, a unique approach to text-to-speech synthesis, utilizing continuous-valued tokens based on mel-spectrograms. This method aims to overcome the limitations of discrete codec codes by directly generating continuous mel-spectrogram frames from text input. The approach addresses two key challenges: setting an appropriate training objective for continuous representations and enabling sampling mechanisms in continuous space.
To tackle these challenges, MELLE employs regression loss with a spectrogram flux loss function instead of cross-entropy loss. This new loss function helps model the probability distribution of continuous-valued tokens more effectively. Also, MELLE incorporates variational inference to facilitate sampling mechanisms, enhancing output diversity and model robustness.
The model operates as a single-pass zero-shot TTS system, autoregressively predicting mel-spectrogram frames based on previous mel-spectrogram and text tokens. This approach aims to eliminate the robustness issues associated with sampling discrete codec codes, potentially offering improved fidelity and efficiency in speech synthesis.
MELLE’s architecture integrates several innovative components for efficient text-to-speech synthesis. It employs an embedding layer, an autoregressive Transformer decoder, and a unique latent sampling module that enhances output diversity. The model includes a stop prediction layer and a convolutional post-net for spectrogram refinement. Unlike neural codec models, MELLE doesn’t require a separate non-autoregressive model, improving efficiency. It can generate multiple mel-spectrogram frames per step, further enhancing performance. The architecture concludes with a vocoder to convert the mel-spectrogram into a waveform, offering a streamlined, single-pass approach that potentially surpasses previous methods in both quality and efficiency.
MELLE demonstrates superior performance in zero-shot speech synthesis tasks compared to VALL-E and its variants. It significantly outperforms vanilla VALL-E in robustness and speaker similarity, achieving a 47.9% relative reduction in WER-H on the continuation task and a 64.4% reduction on the cross-sentence task. While VALL-E 2 shows comparable results, MELLE exhibits better robustness and speaker similarity in the continuation task, highlighting its superior in-context learning ability.
MELLE’s performance remains consistently high even with increased reduction factors, allowing for faster training and inference. The model outperforms most recent works in both robustness and speaker similarity, even with larger reduction factors. MELLE-limited, trained on a smaller corpus, still surpasses VALL-E and its variants, except VALL-E 2. Using multiple sampling with a larger reduction factor can enhance performance while reducing inference time, as demonstrated by the five-time sampling results, which show consistent high robustness across different reduction factor settings.
This study introduces MELLE representing a significant advancement in zero-shot text-to-speech synthesis, introducing a continuous acoustic representation-based language modeling approach. By directly predicting mel-spectrograms from text content and speech prompts, it eliminates the need for discrete vector quantization and two-pass procedures typical of neural codec language models like VALL-E. The incorporation of latent sampling and spectrogram flux loss enables MELLE to produce more diverse and robust predictions. The model’s efficiency can be further enhanced by adjusting the reduction factor for faster decoding. Notably, MELLE achieves results comparable to human performance in subjective evaluations, marking a substantial step forward in the field of speech synthesis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post MELLE: A Novel Continuous-Valued Tokens-based Language Modeling Approach for Text-to-Speech Synthesis (TTS) appeared first on MarkTechPost.